






一篇弱监督分割领域的论文,发表在CVPR2022上:
论文标题:
Weakly Supervised Semantic Segmentation using Out-of-Distribution Data
作者信息:

代码地址:
https://github.com/naver-ai/w-ood
Abstract
作者认为在WSSS任务中,会出现前景任务和背景任务的一些虚假的相关性,比如车轨和火车。作者利用分类器可能做出错误判断的方法,标注一些分布外(Out-of-Distribution)的数据。用这些数据提供的cue,来减弱分割中的错误关联性。该消耗了较小的标注成本,效果较好。
Introduction
(现有的方法及其缺点)
1.常规的two-stage 分割方法,先生成CAM,再正常训练分割。缺点是仅基于图像级标签,伪标签存在前景和背景线索之间的混淆。需要额外的信息来学习来充分区分前景和背景线索。
2.一些方法引入了显著性检测任务,它自然地以不需要知道类别方式提供了图像中突出的前景对象。但是显著性检测任务对不显著的前景对象并不是很有效。
3.一些方法如超像素、纹理、光流等方法,但是它们往往会生成不准确的对象边界,这种低级信息没有考虑与类相关联的语义,效果也不好。
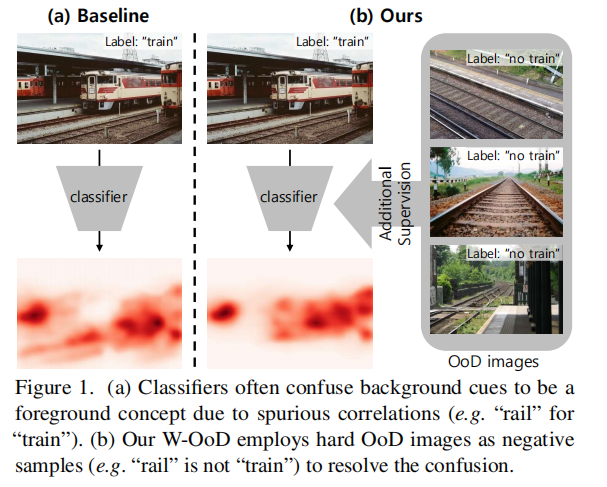
(作者的方法)
选择并获取OoD数据,基于度量学习(metric-learning)提出了W-OoD方法(大致的原理是通过训练网络,扩大分布内数据和OoD数据的特征距离)
3. Method
3.1. Collecting the Hard OoD Data
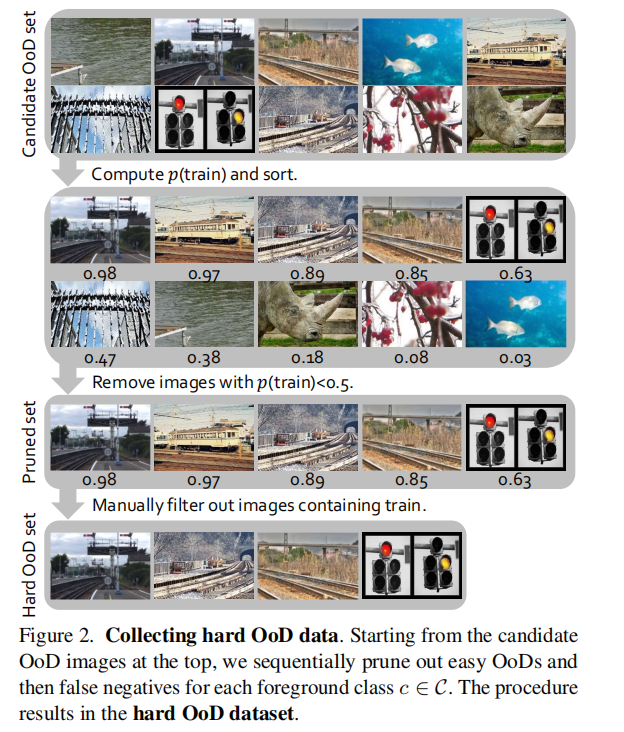
Where to get the candidate OoDs:
(作者举了构建数据集的四个步骤)
(1)define the list C of foregroundclasses of interest
(2)acquire unlabelled images from various sources
(3)determine for each image whether it contains one of the foreground classes
(4)tag each image with the foreground category labels
作者认为满足步骤(2)但是不满足步骤(3)的图片可以用于candidate OoDs。
(其实就是就是说图像里面没有前景类别的,可以作为OoD数据的候选)
Hard OoD samples via ranking and pruning:
(作者进一步介绍了获得Hard OoD的方法(见图2))
OoD data可能包含太多无关的杂碎信息,作者讲输入到分类器中,按照分类器的输出的预测值
p
p
p 进行下列操作(混淆分类器的能力):
(1)删除明显不对劲的
p
<
0.5
p<0.5
p<0.5
(2)对所有的图片按照
p
p
p进行排序
Manual pruning of positive samples
这些数据中可能包含有前景信息(positive)的图片没有去除,需要人工的的进行手动去除。
设图片中包含positive的图片的比例是
r
r
r,需要
n
n
n个Hard OoD图片,则需要人工检查
n
/
(
1
−
r
)
n/(1-r)
n/(1−r)张图片。
Surrogate source of OoD data
(OoD的数据来源问题)
从理论上讲,最好通过复制Pascal数据集构建过程来获得硬OoD集,以便在Pascal上分析和基准测试作者的方法。但这个显然是不行的,无法找到和Pascal数据集相同分布的图像。
作者使用的是OpenImages数据集,使用提供的类别标签从OpenImages数据集中过滤出20个Pascal类,以模拟Pascal数据集。
3.2. Learning with Hard OoD Dataset
(利用Hard OoD Dataset的方法)
比较简略的方式是把这些标签均匀分布到原本的数据集中, 或者直接标记伪“背景”类插入到数据集中,显然这样效果不好(忽略了样本的多样性)。
作者的目标是训练一个分类器
F
F
F,来使常规数据的特征
z
i
n
z_{in}
zin和OoD数据
z
O
o
D
z_{OoD}
zOoD的距离尽可能的远。采用聚类的方法。
记
Z
i
n
Z_{in}
Zin和
Z
O
o
D
Z_{OoD}
ZOoD分别表示常规数据的特征和OoD数据经过分类器的特征的集合。
对于常规数据
Z
i
n
Z_{in}
Zin,构建一类簇
P
i
n
P^{in}
Pin,其中包含
c
c
c个类别,每个类别代表其前景对象的种类。
对于OoD数据作者并没有使用对应的方法,而是使用K-means聚类成
k
k
k个类别,构建了
P
O
o
D
P^{OoD}
POoD。
这样就有两大类簇,分别是:
P
i
n
=
{
P
c
i
n
}
c
=
1
C
P^{in}=\{P_c^{in}\}_{c=1}^C
Pin={Pcin}c=1C和
P
O
o
D
=
{
P
k
O
o
D
}
k
=
1
K
P^{OoD}=\{P_k^{OoD}\}_{k=1}^K
POoD={PkOoD}k=1K。
聚类中心由图像决定,计算方法是:
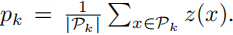
类到聚类中心的计算方法:
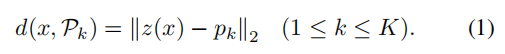
对于作者提出的方法,希望簇
P
i
n
P^{in}
Pin到中心的距离越小越好,希望
P
O
o
D
P^{OoD}
POoD到中心的距离越远越好,即设计损失函数:
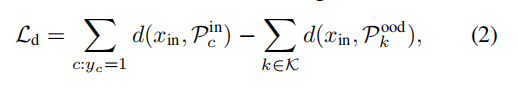
作者也将类别损失函数加进入了,对于常规的数据,用正常的类别标签计算损失,对于OoD则标签是全0,cls损失的计算方法:
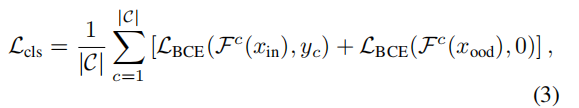
总的损失函数:

3.3. Training Segmentation Networks
上述过程仅仅训练了一个分类器 F F F,对于后面的产生伪mask的操作,作者采用的是IRNet的方法。
Experiments
(简单看下实验结果)
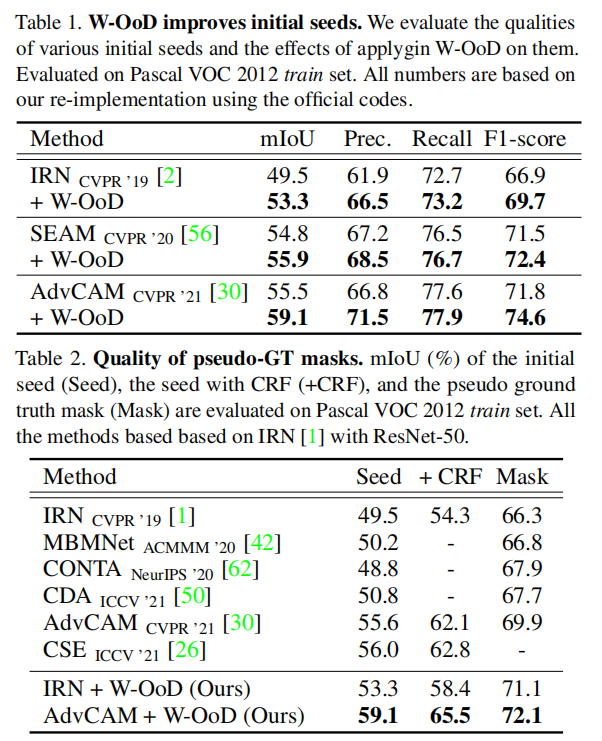















 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









