







Weakly Supervised Semantic Point Cloud Segmentation: Towards 10× Fewer Labels
论文:https://arxiv.org/abs/2004.04091
Abstract
- 语义分割现有方法的成功归因于深层网络设计和大量带标签的训练数据,其中后者被认为始终可用。
- 但是,在实践中,获取3d点云分割标签通常非常昂贵。
- 在这项工作中,提出了一种弱监督的点云分割方法,该方法只需要在训练阶段标记一小部分点即可。
- 通过学习梯度近似以及利用其他空间和颜色平滑度约束,可以实现这一点。
- 在三个具有不同程度的弱监督的公共数据集上进行了实验。
- 提出的方法可以产生接近甚至有时比完全监督的方法更好的结果,而标签减少了10倍。
(一)Introduction
发现:
- 数据集标注昂贵。
提出问题:
- 是否有可能学习仅带有部分标记点的点云分割模型。
- 如果可以,那么多少就足以进行良好的分割。

问题定义:
- 弱监督学习
现有工作:
- 只有极少数的作品试图解决相关问题。
- Weakly supervised segmentation-aided classification of urban scenes from 3d lidar point clouds,提出了一种非参数条件随机场分类器(CRF)来捕获用于弱监督分割的几何结构。但是,它将任务转换为纯粹的结构优化问题,因此无法捕获上下文,例如空间和颜色提示。
- Semantic segmentation of 3d lidar data in dynamic scene using semi-supervised learning,提出了一种半监督3D LiDAR数据分割的方法。它将3D点转换为深度图,并使用CNN进行特征学习,并且从LiDAR扫描的时间一致性生成半监督约束。因此,它不适用于一般的3D点云分割。
目的:
- 使用强大的上下文建模能力和处理通用的3D点云数据来实现弱监督分割。
方法:
- 基于pointnet,DGCNN学习点云特征嵌入。
- 给定部分标记的点云数据,采用一个不完整的监督分支,该分支具有softmax交叉熵损失,该损失仅在标记的点处惩罚。
效果:
- 即使标签数量减少了10倍,也就是仅10%的点被标记,这种简单的策略也可以成功。
- 因为可以将不完全监督的学习梯度视为完全监督的采样近似值。
- 近似梯度收敛于分布的真实梯度,并且间隙以正态分布分布,其方差与采样点的数量成反比。
- 给定足够的标记点,近似梯度接近于真实梯度。
小结:
- 对每个样本中带有较少标记点的更多样本进行广泛注释总是比对具有更多(或完全)标记点的较少样本进行标记更好。
进一步改进:
- 由于上述方法仅对标记点施加了约束,因此建议在三个正交方向上对未标记点附加约束。
- 首先,引入了一个额外的不精确监督分支,该分支以与多实例学习相似的方式定义了点云样本水平的交叉熵损失。它的目的是抑制关于the negative categories的任何点的激活。
- 第二,通过随机训练的平面内旋转和翻转来扩充训练样本,从而引入了一个Siamese自我监督分支,然后鼓励原始和经扩充的逐点预测保持一致。
- 最后,语义部分/对象在空间和色彩空间中通常是连续的。为此,提出了空间和颜色平滑度约束,以鼓励具有相似颜色的空间相邻点具有相同的预测。
提出网络:

论文贡献:
- 这是研究深度学习环境中的弱监督点云分割的第一项工作。
- 对弱监督的成功进行了解释,并提供了在固定标签预算下对注释策略的深入了解。
- 基于inexact supervision, self-supervision以及空间和色彩平滑度采用了三项附加损失,以进一步约束未标记的数据。
- 在三个公共数据集上进行实验,这些数据集是鼓励未来研究的基准。
(二) Related Work
两种类型的弱监管: incomplete and inexact supervision. 论文将不精确监督作为对点云分割任务的不完全监督的补充。
(三)Methodology
3.1 Point Cloud Encoder Network
符号定义:
- 将输入点云数据正式表示为 { X b } b = 1... B \left \{X_{b}\right \}_{b=1...B} { Xb}b=1...B,其中 B B B个单独的形状(例如,形状分割)或房间块(例如,室内点云分割)。
- 每个样本 X b ∈ R N × F X_{b}\in R^{N\times F} Xb∈RN×F包含N个3d点,这些点具有xyz坐标和可能的附加特征,例如RGB值。
- 每个样本还附有按点分割的标签 y b ∈ { 1 , . . . , K } N y_{b}\in \left \{1,...,K\right \}^{N} yb∈{ 1,...,K}N,例如飞机的机身,机翼和引擎。
- 将one-hot encoded labe表示为 Y ^ ∈ 0 , 1 B × N × K \hat{Y}\in {0,1}^{B\times N\times K} Y^∈0,1B×N×K。
- 使用由 Θ Θ Θ参数化的点云编码器网络 f ( X ; Θ ) f(X;Θ) f(X;Θ)获得嵌入的点云特征 Z b ∈ R N × K Z_{b}\in {R}^{ N\times K} Zb∈RN×K。
- 嵌入的维数与分割类别的数量相同。
3.2. Incomplete Supervision Branch
假设在点云样本 { X b } \left \{X_{b}\right \} {
Xb}中只有很少的点被标记为ground-truth。将二进制掩码表示为 M ∈ { 0 , 1 } B × N M\in \left \{0,1\right \}^{ B\times N} M∈{
0,1}B×N,标记点为1,否则为0。将标记点上的softmax交叉熵损失定义为:
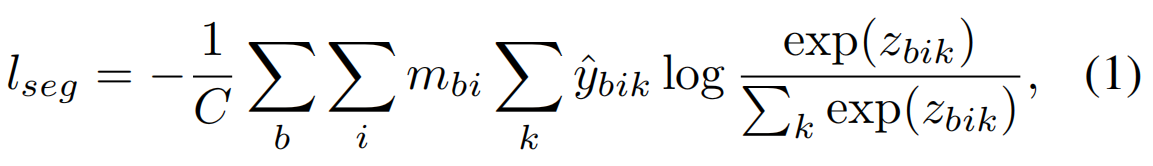
其中 C = ∑ b , i m b i = ∥ M ∥ 1 C= \sum_{b,i}^{}m_{bi}=\left \| M\right \|_{1} C=∑b,imbi=∥M∥1是归一化变量。
现象: 论文方法只需要10%的标记点就可以产生具有竞争力的结果,即 ∥ M ∥ 1 / ( B ⋅ N ) = 0.1 \left \|M \right \|_{1}/(B\cdot N)=0.1 ∥M∥1/(B⋅N)=0.1。
详细说明:
-
假设两个权重相似的网络,一个在完全监督下训练的网络和另一个在弱监督下训练的网络应该产生相似的结果。
-
假设两个网络均以相同的初始化开始,则每个步骤中梯度的较高相似性意味着两个网络收敛至相似结果的机会较高。
-
写出具有完全监督 ∇ Θ l f ∇_{Θ}lf
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1487
1487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









