






一篇经典的弱监督分割论文,发表在CVPR2019上面
论文标题:
Weakly Supervised Learning of Instance Segmentation with Inter-pixel Relations
作者信息:

代码地址:
https://github.com/jiwoon-ahn/irn
Abstract
作者提出了一种实例弱监督分割的模型:训练分类模型获得seeds,然后expansion获得更清晰的边缘。作者提出了IRNet,主打两点:
1.使用了Instance label进行seeds的传播和扩展。
2.在attention map上,借助 inter-pixel relations训练模型。
Introduction
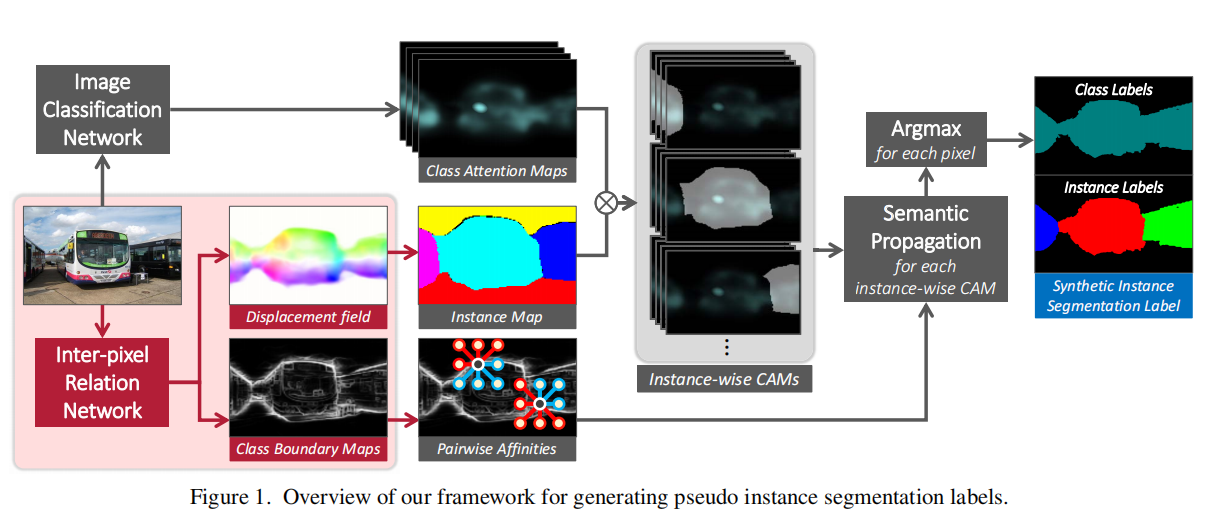
传统CAM方法及其缺点: CAM主要体现的是区域对分类的贡献度,它们的分辨率太小,通常只突出对象的部分区域,另外,不能区分同一类的不同实例。
作者IRNet的改进: 引入两个额外的监督措施, a class-agnostic instance map 和 pairwise semantic affinities。(依次对应于branch1和branch2)
IRNet的简要结构: 主要有两个branch。
第一个branch预测一个位移向量场,其中每个像素上的一个二维向量表示该像素所属的实例的质心。通过将位移实例标签指定指向相同位置的像素,将位移字段转换为实例映射。(没看太明白)
第二个branch第检测不同对象类之间的边界。然后从检测到的边界中计算出成对的语义亲和度。在亲和度的基础上训练模型。
Methods
如图是IRNet的framwork。
1.Class Attention Maps
作者首先使用分类网络获得CAM,获得方法很常规,即最后一层卷积的feature map的每个通道,按照分类权重后加权求和,即:
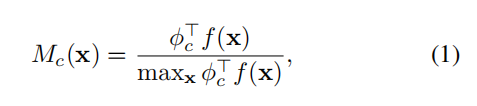
CAM在作者提出的IRNet中有两个作用:一方面被用于获得图像的实例的种子区域,另一方面被用于IRnet的进一步监督学习。
作者选用的是resnet50,修改了最后一层,提高了backbone输出的分辨率
2.Inter-pixel Relation Network
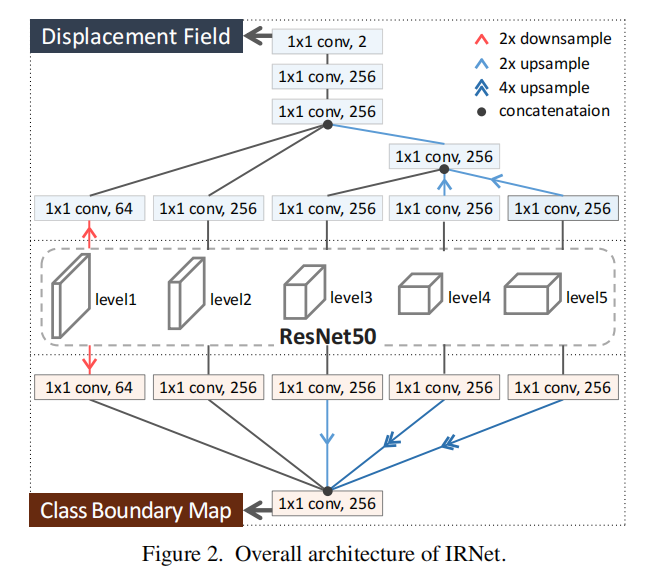
2.1 IRNet Architecture
IRNet有两个分支输出,分别预测一个向量场(Displacement Field)和一个图像的边界图(Boundary Detection)
它们共享resnet50的主干,从所有不同level 的backbone中获得特征:
Displacement Field: 使用多层1×1的卷积来调整通道数和分辨率(figure2),最后一个连接的特征图中,通过三个1×1的卷积层解码一个位移场,其输出有两个通道。(最终获得instance map )
Boundary Detection 使用1×1的卷积来调整通道数,最后再concate输出,通道数是256。(最终获得class boundry map)
2.2 Inter-pixel Relation Mining from CAMs
作者的模型仅仅使用Inter-pixel relations作为唯一的监督信号,这里定义了inter-pixel relations的两种类型,一个是坐标的位移(displacement of coordinates),另外一个是类的差异( class equivalence)。其中坐标的位移可以用减法去计算,class equivalence则使用CAM去进行预测,做法如figure 3 所示:
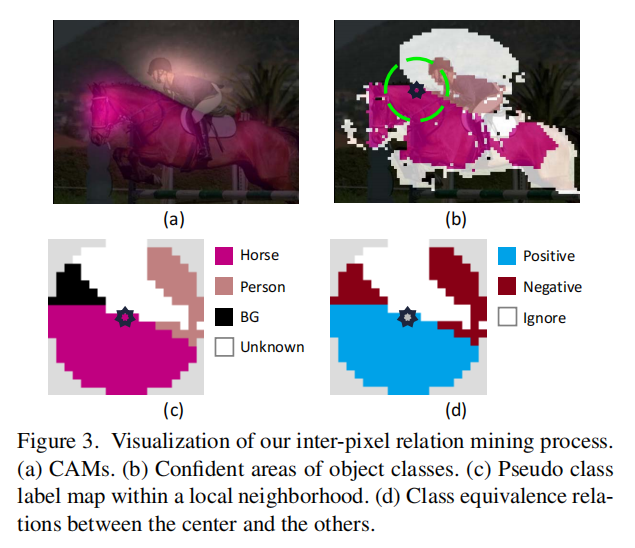
具体获得class equivalence的做法:
首先,根据模糊的CAM确定图像的前景或者背景,如果attention 分数小于0.05视为背景,分数大于0.3视为前景,中间部分的值视为不确定值,直接将其忽略。
然后,对所有确定值得区域应用CRF进行refine,并根据每个像素的最佳的score的确定类别,以构建伪标签 M M M。
最后,根据像素的类别的关系,将像素划分为两类,记为
P
+
P^+
P+和
P
−
P^-
P−,划分的计算公式如下:
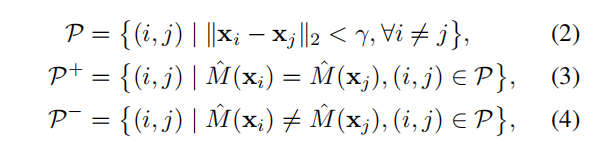
即同类的为positive ,否则为negative,其中
r
r
r表示所参与计算的像素对的最大半径距离。
2.3 Loss for Displacement Field Prediction
IRNet预测的第一个branch是Displacement Field,记为
D
D
D。作者希望每个像素的
D
D
D能够指向这个instance的中心区域(质心)。
作者认为这个可以进行隐式的学习得到,需要满足两个条件:
条件一,每个实例下的像素对的估计的质心要相同,(即所有的像素坐标加上D应该都指向同一个位置),即
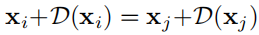
条件二,根据中心区域(质心)的定义,每个实例所有对应像素点的场向量加一块的和应为为0,即
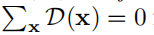
作者设计损失函数满足这两个条件
对于条件一: 对于一对像素点
(
i
,
j
)
∈
P
+
(i,j)\in P^+
(i,j)∈P+它们极有可能在相同的实例中,那么用他它们在
D
D
D上的差值来近似它们的图像坐标位移,即用下述公式:
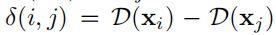 表示:
表示:
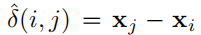
在两者相等的情况下,很容易获得(简单的移项)
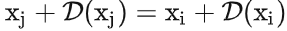
这样只要设计损失函数使得
δ
(
i
,
j
)
\delta(i,j)
δ(i,j)和
δ
^
(
i
,
j
)
\hat{\delta}(i,j)
δ^(i,j)越小越好,即:
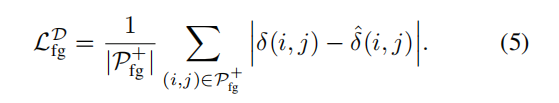
对于条件二: 作者认为IRNet可以自动学习得到,即通过训练可以逐步收敛到该条件(我没搞懂为啥)。
为了消除背景质心对网络的影响,作者希望背景像素的
D
D
D的差异,即
δ
(
i
,
j
)
\delta(i,j)
δ(i,j)越小越好,设计损失函数:
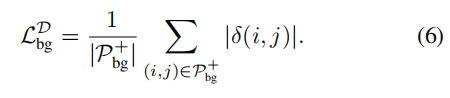
2.4 Loss for Class Boundary Detection
作者IRNet第二个branch用于预测类别的边界,并用
B
∈
[
0
,
1
]
w
×
h
B\in[0,1]^{w×h}
B∈[0,1]w×h进行表示。但是实际上并没有专门的边界的label,作者这里使用了多实例学习(Multiple Instance Learning)的方法来获得。
具体来所,作者定了一种像素间的语义亲和度(semantic affinity)。对于两个像素
x
i
x_i
xi和
x
j
x_j
xj,其语义亲和度可以表示为:
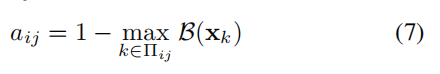
其中
∏
i
j
\prod_{ij}
∏ij表示像素
x
i
x_i
xi和
x
j
x_j
xj之间连线的所有点。即如果连线上的所有点的
B
B
B都为1,
a
i
j
a_{ij}
aij为0,否则
a
i
j
a_{ij}
aij为1(同类为0,异类为1)。这种方式可以对像个像素之间是否存在类边界进行较好的量化,作者设计了交叉熵损失函数进行训练:
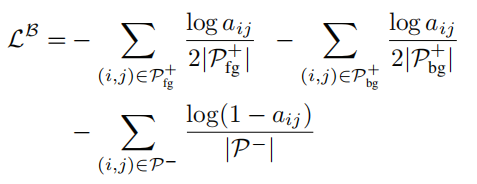
这个公式可以这样理解,对与同一个实例中的正样本(
P
+
P^+
P+),它们本应当是同类,所以
a
i
j
a_{ij}
aij越小越好。
对于负样本(
P
−
P^-
P−),它们本应当是异类,所以
a
i
j
a_{ij}
aij越大越好。
2.5 Joint Learning of the Two Branches
最终的损失函数是两个分支损失函数的和,即:
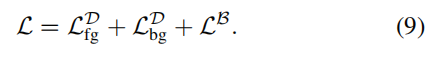
3 Label Synthesis Using IRNet
根据前面的介绍,branch1对应于instance map,branch 2对应于class boundary map 。其中class boundary map semantic affinity利用公式(7)可以直接计算(figure4中说明,输入RGB图像,)
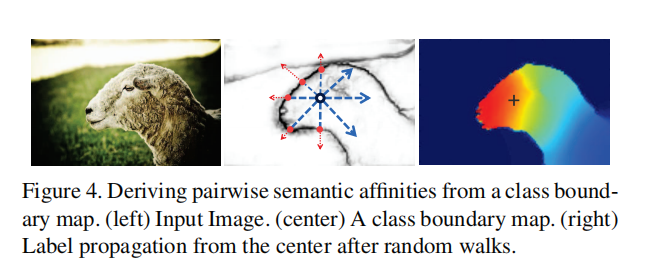
这一部分作者主要介绍branch1输出的
D
D
D如何转化为instance map。
3.1Generating Class-agnostic Instance Map
class-agnostic instance map 记为 I I I,格式是2D的 W × D W×D W×D(和 D D D相同)。 I I I通过将位移矢量指向同一质心的像素分组来获得。(具体怎么算的没说)
作者认为
D
D
D实在CAM的基础上进行计算的,因此它对质心的估算的不准确,所以作者使用下列公式进行refine:
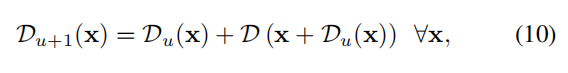
这里通过在当前估计的质心位置添加位移矢量,迭代地定义每个位移矢量。(具体原理没说)。
作者修正的质心的
D
D
D的位置也是分散的,因此将一小群相邻像素而不是单个坐标作为质心。figure5是修正后的样子。

3.1Synthesizing Instance Segmentation Labels
对于获得的class-agnostic instance map
I
I
I,把它和CAM合成得到class-agnostic instance map,合成公式如下:
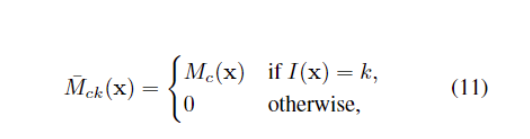
其中
k
k
k表示实例,
c
c
c表示类别。这里还进行了下一步的refine的操作,使用random walk算法,把instance-wise CAM 通过将其注意力分数传播到相关区域来单独细化。该算法中的系数ransition probability matrix
T
T
T是从semantic affinity matrix
A
=
[
a
i
j
]
A=[a_{ij}]
A=[aij]中获得,公式如下:
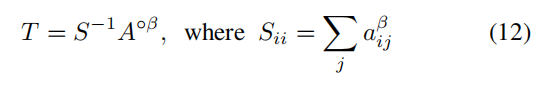
式子中,
A
o
β
A^{o\beta}
Aoβ是
A
A
A关于
β
\beta
β得哈达玛幂,
S
S
S是
A
o
β
A^{o\beta}
Aoβ的行归一化矩阵,
β
\beta
β是一个系数。具体random walk的公式如下:
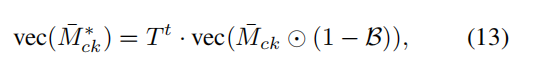
作者通过乘以
1
−
B
1-B
1−B来惩罚边界像素的分数,因为这些独立的像素不会将它们的分数传播给邻居,并且与序列中的其他像素相比分数过高。然后选择
c
c
c和
k
k
k的组合,最大化
M
c
k
M_{ck}
Mck,生成实例分割的标签,如果最大得分小于最低25%,则将该像素视为背景。
Experiments
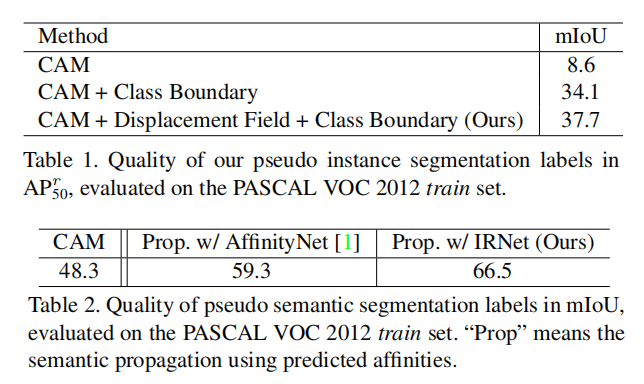
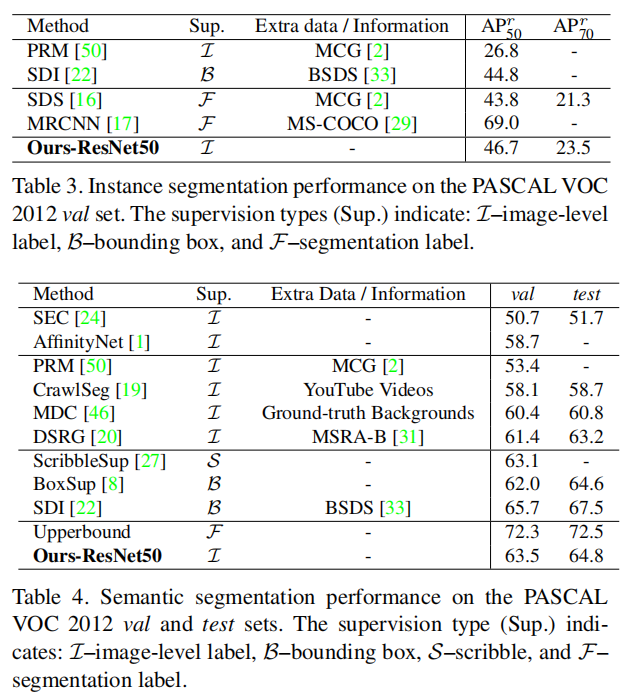
总结
非常经典的弱监督分割论文,但是感觉流程蛮复杂的,算法说的也很简略。我自己太菜了,很多地方看不太懂。















 2167
2167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









