







#
#作者:韦访
#博客:https://blog.csdn.net/rookie_wei
#微信:1007895847
#添加微信的备注一下是CSDN的
#欢迎大家一起学习
#
1、概述
最近有点懒,下完班就没心思写博客了。今早收到一个在校大学生的支付宝红包,虽然只是几块钱,但是留言说感谢我在CSDN上的分享。之前的博客也对一些在做毕设的同学们有点帮助,看来写的博客还是有一丢丢价值的,还是尽量继续更新博客吧。还有一点就是,加我微信进群的同学们有问题尽量在群里讨论,不要私聊我,要不然私聊信息太多影响我的生活和工作了,希望能理解。这一讲开始来分析人体姿态检测的源码,写第一篇姿态检测的博客之前,其实源码我已经分析完了,希望看到这篇博客之前,最好先自己去看一下论文,然后自己再分析一下源码,实在看不懂了再来参考这篇博客,自己分析收获很多的。
运行示例代码和论文解析博客如下,
https://blog.csdn.net/rookie_wei/article/details/90551331
https://blog.csdn.net/rookie_wei/article/details/90705880
2、训练模型
想看懂深度学习的算法,就从模型的训练过程去分析。这一讲,我们先将模型训练的代码跑起来。先看一下工程根目录下的README.md文件,看看有没有介绍怎么训练的。

看到上面这行,训练的说明应该就在etcs/training.md文件里,打开这个文件看看。
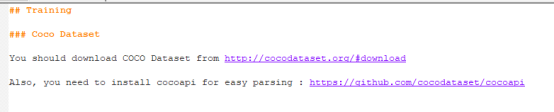
首先需要下载数据集,如果你在上一讲中已经下载了对应的数据集这里就可以跳过了,一共有三个压缩包,解压以后得到三个文件夹,如下,

关于数据集上一讲中已经讲过了,这里就不再赘述。接着往下看,

运行train.py文件,带上一些参数,来看看(猜猜)这些参数,
--model参数,我先假装不知道它是干嘛的,直接用它给的参数就可以了
--datapath参数,应该就是数据集的路径了
--batchsize参数,这个参数我们应该很熟悉啦,batch的大小
--lr参数,这个参数应该也很熟悉了,学习率
--modelpath参数,看样子应该是我们模型训练好以后,保存的路径
根文件夹下没找到这个train.py文件,这个文件在tf_pose文件夹下,顺便看看train.py的源码,看看它的参数,以验证我们上面猜测对不对,
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Training codes for Openpose using Tensorflow')
parser.add_argument('--model', default='mobilenet_v2_1.4', help='model name')
parser.add_argument('--datapath', type=str, default='/data/public/rw/coco/annotations')
parser.add_argument('--imgpath', type=str, default='/data/public/rw/coco/')
parser.add_argument('--batchsize', type=int, default=64)
parser.add_argument('--gpus', type=int, default=4)
parser.add_argument('--max-epoch', type=int, default=600)
parser.add_argument('--lr', type=str, default='0.001')
parser.add_argument('--tag', type=str, default='test')
parser.add_argument('--checkpoint', type=str, default='')
parser.add_argument('--input-width', type=int, default=432)
parser.add_argument('--input-height', type=int, default=368)
parser.add_argument('--quant-delay', type=int, default=-1)
args = parser.parse_args()--model参数,这里的默认参数跟我们上面给的不一样,那说明这个参数是有多个选择的,我们先不管它是干嘛的,按上面的参数传入就可以了。
--datapath参数,要给到annotations文件夹,我放数据集的路径是“G:\tensorflow\post-estimation\datasets\annotations”,你们根据自己的路径自己修改。
--imgpath参数,看样子也是数据集的路径,但是只要给到datasets文件夹就可以了,我的路径是,G:\tensorflow\post-estimation\datasets\。
--batchsize、--lr参数,就不多说了。
--gpus参数,应该是GPU的个数,我只有以后,那这个参数要改成1,土豪随意。
有没有发现,没有modelpath参数啊?
搜索这个词,找到下面的代码,
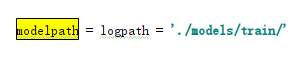
那就不管了,用默认的。因为train.py文件在tf_pose文件夹下,所以命令行运行的时候,在train.py前要加上tf_pose,所以最后我们要执行的命令如下,
python tf_pose\train.py --model=cmu --datapath=G:\tensorflow\post-estimation\datasets\annotations --batchsize=64 --lr=0.001 --imgpath=G:\tensorflow\post-estimation\datasets\ --gpus=1上面的文件路径格式是windows系统的,因为我现在工作只用windows系统,多年不用windows虽然有点不习惯,但是没办法也只能用了。为了不来回的切换系统,我直接将家里的系统也装成win10了。
运行结果,
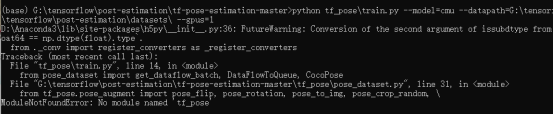
出错了,pose_dataset.py文件第31行,找不到tf_pose模块。有问题不可怕,解决就是了。方法有很多,
方法一:
将当前文件夹添加到Python的PYTHONPATH环境变量,
如下图所示,
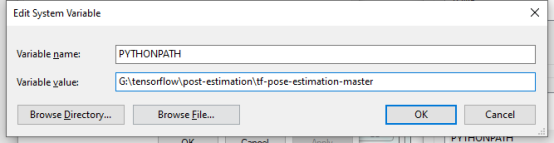
然后再重启终端。
方法二:
还是设置Python的PYTHONPATH环境变量,但是不改系统的环境变量,直接命令行设置,但是只是临时的,关闭终端以后就无效了,在终端执行,
set PYTHONPATH=G:\tensorflow\post-estimation\tf-pose-estimation-master 上面的G:\tensorflow\post-estimation\tf-pose-estimation-master是我的项目的根目录,根据自己的情况自行修改。
方法三:
不改变环境变量,将train.py拷贝到项目的根目录下执行,不就有tf_pose模块了嘛?
我用的是方法3,你们随意,但是使用方法3的话,得稍微修改一丢丢代码,将train.py拷贝到项目根目录,再将
from pose_dataset import get_dataflow_batch, DataFlowToQueue, CocoPose
from pose_augment import set_network_input_wh, set_network_scale
from common import get_sample_images
from networks import get_network改成
from tf_pose.pose_dataset import get_dataflow_batch, DataFlowToQueue, CocoPose
from tf_pose.pose_augment import set_network_input_wh, set_network_scale
from tf_pose.common import get_sample_images
from tf_pose.networks import get_network再执行训练命令,
python train.py --model=cmu --datapath=G:\tensorflow\post-estimation\datasets\annotations --batchsize=64 --lr=0.001 --imgpath=G:\tensorflow\post-estimation\datasets\ --gpus=1运行结果,
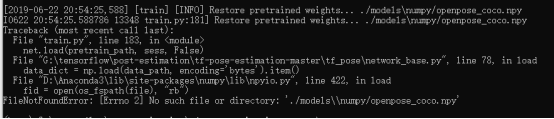
还是出错,但是已经不是上面的错了,继续解决就是了。
没找到./models\\numpy/openpose_coco.npy文件,那就看看models\numpy文件夹下有什么内容,

一个download.sh文件,打开看看,
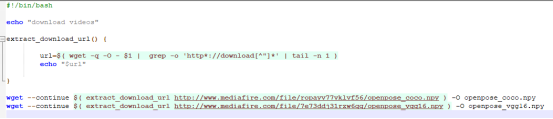
下载两个文件,如果是Linux系统的话,直接执行就好了。如果是windows系统,且安装了Git,那就打开Git终端,到该文件夹下执行,如下图所示,

实在不行,就用浏览器打开这两个链接,手动下载,
http://www.mediafire.com/file/7e73ddj31rzw6qq/openpose_vgg16.npy
http://www.mediafire.com/file/ropayv77vklvf56/openpose_coco.npy

国内的网络下载这两个文件很慢,我将它们上传了,链接如下,
https://download.csdn.net/download/rookie_wei/11254072
文件下载完以后,继续回到项目根目录执行我们的训练命令,
python train.py --model=cmu --datapath=G:\tensorflow\post-estimation\datasets\annotations --batchsize=64 --lr=0.001 --imgpath=G:\tensorflow\post-estimation\datasets\ --gpus=1运行结果,

还出错,但是是新的错误,这个错误是numpy版本的问题,可以参考博客,
https://blog.csdn.net/rookie_wei/article/details/89928617
解决方法就是降低numpy的版本,执行下面命令,
pip uninstall numpy
pip install numpy==1.16.2再运行上面的训练命令,运行结果,
Traceback (most recent call last):
File "G:\tensorflow\post-estimation\tf-pose-estimation-master\tf_pose\pose_dataset.py", line 447, in run
self.op.run(feed_dict=feed)
File "D:\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py", line 2450, in run
_run_using_default_session(self, feed_dict, self.graph, session)
File "D:\Anaconda3\lib\site-packages\tensorflow\python\framework\ops.py", line 5216, in _run_using_default_session
session.run(operation, feed_dict)
File "D:\Anaconda3\lib\site-packages\tensorflow\python\client\session.py", line 929, in run
run_metadata_ptr)
File "D:\Anaconda3\lib\site-packages\tensorflow\python\client\session.py", line 1128, in _run
str(subfeed_t.get_shape())))
ValueError: Cannot feed value of shape (64, 368, 368, 3) for Tensor 'image:0', which has shape '(64, 368, 432, 3)'
2019-06-23 20:10:44,232 ERROR Exception in Thread-1:Cannot feed value of shape (16, 368, 368, 3) for Tensor 'image:0', which has shape '(16, 368, 432, 3)'还是出错,是不是要崩溃啦?看出错提示,
Cannot feed value of shape (64, 368, 368, 3) for Tensor 'image:0', which has shape '(64, 368, 432, 3)',
我们喂的数据的shape是(64, 368, 368, 3) ,而模型要求的是(64, 368, 432, 3)。为什么会有这种现象呢?我以前训练可没出现这个现象,没办法,只能看源码了。打开train.py文件,看main函数,
# define input placeholder
set_network_input_wh(args.input_width, args.input_height)
scale = 4
if args.model in ['cmu', 'vgg'] or 'mobilenet' in args.model:
scale = 8
set_network_scale(scale)
output_w, output_h = args.input_width // scale, args.input_height // scale上面的代码的作用就是设置输入输出图像的宽高,参数默认的宽高是(432, 368),为什么我们喂的数据的宽高会是(368, 368)呢?看看set_network_input_wh函数和set_network_scale函数,
_network_w = 368
_network_h = 368
_scale = 2
def set_network_input_wh(w, h):
global _network_w, _network_h
_network_w, _network_h = w, h
def set_network_scale(scale):
global _scale
_scale = scale这里默认的_network_w和_network_h都是368,会不会是我们传进来的参数并没有起作用?看一下报错的提示,pose_dataset.py文件的447行,
for dp in self.ds.get_data():
feed = dict(zip(self.placeholders, dp))
self.op.run(feed_dict=feed)
self.last_dp = dp上面的代码是属于DataFlowToQueue类的run函数,这个ds是这个类的构造函数传入的,那么我们去搜索一下这个类在哪里调用的。通过搜索找到在train.py的main函数就使用了这个类,代码如下,
# prepare data
df = get_dataflow_batch(args.datapath, True, args.batchsize, img_path=args.imgpath)
enqueuer = DataFlowToQueue(df, [input_node, heatmap_node, vectmap_node], queue_size=100)
q_inp, q_heat, q_vect = enqueuer.dequeue()那么,看看这个get_dataflow_batch函数干了什么。
def get_dataflow_batch(path, is_train, batchsize, img_path=None):
logger.info('dataflow img_path=%s' % img_path)
ds = get_dataflow(path, is_train, img_path=img_path)
ds = BatchData(ds, batchsize)
# if is_train:
# ds = PrefetchData(ds, 10, 2)
# else:
# ds = PrefetchData(ds, 50, 2)
return ds再看看get_dataflow函数呢,
def get_dataflow(path, is_train, img_path=None):
ds = CocoPose(path, img_path, is_train) # read data from lmdb
if is_train:
ds = MapData(ds, read_image_url)
ds = MapDataComponent(ds, pose_random_scale)
ds = MapDataComponent(ds, pose_rotation)
ds = MapDataComponent(ds, pose_flip)
ds = MapDataComponent(ds, pose_resize_shortestedge_random)
ds = MapDataComponent(ds, pose_crop_random)
ds = MapData(ds, pose_to_img)
# augs = [
# imgaug.RandomApplyAug(imgaug.RandomChooseAug([
# imgaug.GaussianBlur(max_size=3)
# ]), 0.7)
# ]
# ds = AugmentImageComponent(ds, augs)
ds = PrefetchData(ds, 1000, multiprocessing.cpu_count() * 1)
else:
ds = MultiThreadMapData(ds, nr_thread=16, map_func=read_image_url, buffer_size=1000)
ds = MapDataComponent(ds, pose_resize_shortestedge_fixed)
ds = MapDataComponent(ds, pose_crop_center)
ds = MapData(ds, pose_to_img)
ds = PrefetchData(ds, 100, multiprocessing.cpu_count() // 4)
return ds看看pose_to_img函数,
def pose_to_img(meta_l):
global _network_w, _network_h, _scale
return [
meta_l[0].img.astype(np.float16),
meta_l[0].get_heatmap(target_size=(_network_w // _scale, _network_h // _scale)),
meta_l[0].get_vectormap(target_size=(_network_w // _scale, _network_h // _scale))
]这里就用到了我们上面设置的_network_w, _network_h, _scale三个参数,那么,我们分别在pose_to_img函数和set_network_input_wh函数打印这三个参数的值,看看是否一致。将set_network_scale函数改为,
def set_network_scale(scale):
global _scale
_scale = scale
print('wf====>>>>set_network_scale _scale:', _scale, ' _network_w:', _network_w, ' _network_h:', _network_h)将pose_to_img函数改为,
def pose_to_img(meta_l):
global _network_w, _network_h, _scale
print('wf====>>>>pose_to_img _scale:', _scale, ' _network_w:', _network_w, ' _network_h:', _network_h)
return [
meta_l[0].img.astype(np.float16),
meta_l[0].get_heatmap(target_size=(_network_w // _scale, _network_h // _scale)),
meta_l[0].get_vectormap(target_size=(_network_w // _scale, _network_h // _scale))
]再运行,运行结果,
wf====>>>>set_network_scale _scale: 8 _network_w: 432 _network_h: 368
wf====>>>>pose_to_img _scale: 2 _network_w: 368 _network_h: 368
奇怪了啊,从set_network_scale _scale函数打印的结果来看,我们是已经将值传下去了,而且这些变量也都是global全局变量,为何pose_to_img函数打印的值还是初始值呢?据经验判断,我觉得pose_to_img可能是由另一个进程调用的,那么,我们在这两个函数打印出它们所在的进程id和父进程id看看。
将pose_to_img函数改为,
def set_network_scale(scale):
global _scale
_scale = scale
print('wf====>>>>set_network_scale _scale:', _scale, ' _network_w:', _network_w, ' _network_h:', _network_h, 'os.getpid():', os.getpid(), 'os.getppid():', os.getppid())将pose_to_img函数改为,
def pose_to_img(meta_l):
global _network_w, _network_h, _scale
print('wf====>>>>pose_to_img _scale:', _scale, ' _network_w:', _network_w, ' _network_h:', _network_h, 'os.getpid():', os.getpid(), 'os.getppid():', os.getppid())
return [
meta_l[0].img.astype(np.float16),
meta_l[0].get_heatmap(target_size=(_network_w // _scale, _network_h // _scale)),
meta_l[0].get_vectormap(target_size=(_network_w // _scale, _network_h // _scale))
]再运行,运行结果,
wf====>>>>set_network_scale _scale: 8 _network_w: 432 _network_h: 368 os.getpid(): 13320 os.getppid(): 11092
wf====>>>>pose_to_img _scale: 2 _network_w: 368 _network_h: 368 os.getpid(): 15412 os.getppid(): 13320
wf====>>>>pose_to_img _scale: 2 _network_w: 368 _network_h: 368 os.getpid(): 5352 os.getppid(): 13320
os.getpid打印的是当前进程id,os.getppid打印的是当前进程的父进程id,由上面的结果来看,调用set_network_scale函数和pose_to_img函数的不是同一个进程,而调用pose_to_img函数的又有两个不同的进程,而且它们的父进程都是调用set_network_scale函数的进程。说明我的判断是对的,因为不同的进程之间的变量是不共享的。
我没有研究过tensorpack模块和pycocotools模块,不知道它们运行的机制,我上个月用另两台电脑(一个是win10,一个是Ubuntu)运行的时候是没有出现这个现象的,不知道是不是它们版本升级导致的?但这个不是我们现在研究的重点,那么,最直接的解决这个问题的方法就是,直接改pose_augment.py文件的_network_w, _network_h, _scale这三个变量的初始值,改成,
_network_w = 432
_network_h = 368
_scale = 8记得把上面两个函数的打印先去掉,再运行,运行结果,
Traceback (most recent call last):
File "train.py", line 209, in <module>
_, gs_num = sess.run([train_op, global_step])
File "D:\Anaconda3\lib\site-packages\tensorflow\python\client\session.py", line 929, in run
run_metadata_ptr)
File "D:\Anaconda3\lib\site-packages\tensorflow\python\client\session.py", line 1152, in _run
feed_dict_tensor, options, run_metadata)
File "D:\Anaconda3\lib\site-packages\tensorflow\python\client\session.py", line 1328, in _do_run
run_metadata)
File "D:\Anaconda3\lib\site-packages\tensorflow\python\client\session.py", line 1348, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[64,64,368,432] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator cuda_host_bfc
[[{{node swap_out_gradients/pool1_stage1_grad/MaxPoolGrad_0}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[node Adam/update (defined at train.py:143) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.还有问题,继续改,OOM错误,内存溢出,将batchsize改小点看看,改后的运行命令如下,
python train.py --model=cmu --datapath=G:\tensorflow\post-estimation\datasets\annotations --batchsize=16 --lr=0.001 --imgpath=G:\tensorflow\post-estimation\datasets\ --gpus=1运行结果,
![]()
总算跑起来了。
我不想每次运行都带一堆参数,所以直接将上面的参数写成默认值。
parser.add_argument('--model', default='cmu', help='model name')
parser.add_argument('--datapath', type=str, default='G:/tensorflow/post-estimation/datasets/annotations')
parser.add_argument('--imgpath', type=str, default='G:/tensorflow/post-estimation/datasets/')
parser.add_argument('--batchsize', type=int, default=16)
parser.add_argument('--gpus', type=int, default=1)
parser.add_argument('--max-epoch', type=int, default=600)
parser.add_argument('--lr', type=str, default='0.001')
parser.add_argument('--tag', type=str, default='test')
parser.add_argument('--checkpoint', type=str, default='')
parser.add_argument('--input-width', type=int, default=432)
parser.add_argument('--input-height', type=int, default=368)
parser.add_argument('--quant-delay', type=int, default=-1)















 1538
1538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









