







给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- public static void main(String[] args) {
- try {
- ServerSocket tomcat = new ServerSocket(9090);
- System.out.println(“服务器启动”);
- //
- Socket s = tomcat.accept();
- //
- byte[] buf = new byte[1024];
- InputStream in = s.getInputStream();
- //
- int length = in.read(buf);
- String request = new String(buf,0,length);
- //
- System.out.println(request);
- } catch (IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
这次我们在通过对应的URL在浏览器中对我们的山寨服务器进行访问,得到的输出结果是:

通过成果我们看到,我们已经成功的简单山寨了一下tomcat。
不过这里需要注意的是,我们自己山寨的tomcat服务器当中,之所以也成功的输出了Http协议的请求体,是因为:
我们是通过web浏览器进行访问的,如果通过普通的socket进行对serversocket的连接访问,是没有这些请求信息的。
因为我们前面已经说过了,web浏览器与服务器之间的通信必须遵循Http协议。
所以,我们日常生活中使用的web浏览器,会自动的为我们的请求进行基于http协议的包装。
但是,因为我们已经了解了原理,所以我们也可以自己模拟一下浏览器过过瘾:
[java]
view plain
copy
- //山寨浏览器
- public class MyBrowser {
- public static void main(String[] args) {
- try {
- Socket browser = new Socket(“192.168.1.102”, 9090);
- PrintWriter pw = new PrintWriter(browser.getOutputStream(),true);
- // 封装请求第一行
- pw.println(“GET/ HTTP/1.1”);
- // 封装请求头
- pw.println(“User-Agent: Java/1.6.0_13”);
- pw.println(“Host: 192.168.1.102:9090”);
- pw
- .println(“Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2”);
- pw.println(“Connection: keep-alive”);
- // 空行
- pw.println();
- // 封装实体主体
- pw.println(“UserName=zhangsan&Age=17”);
- // 写入完毕
- browser.shutdownOutput();
- // 接受服务器返回信息,
- InputStream in = browser.getInputStream();
- //
- int length = 0;
- StringBuffer request = new StringBuffer();
- byte[] buf = new byte[1024];
- //
- while ((length = in.read(buf)) != -1) {
- String line = new String(buf, 0, length);
- request.append(line);
- }
- System.out.println(request);
- //browser.close();
- } catch (IOException e) {
- System.out.println(“异常了,操!”);
- }finally{
- }
- }
- }
- //修改后的山寨tomcat服务器
- public class MyTomcat {
- public static void main(String[] args) {
- try {
- ServerSocket tomcat = new ServerSocket(9090);
- System.out.println(“服务器启动”);
- //
- Socket s = tomcat.accept();
- //
- byte[] buf = new byte[1024];
- InputStream in = s.getInputStream();
- //
- int length = 0;
- StringBuffer request = new StringBuffer();
- while ((length = in.read(buf)) != -1) {
- String line = new String(buf, 0, length);
- request.append(line);
- }
- //
- System.out.println(“request:”+request);
- PrintWriter pw = new PrintWriter(s.getOutputStream(),true);
- pw.println(“”);
- pw.println(“”);
- pw.println(“
LiveSession List ”); - pw.println(“”);
- pw.println(“”);
- pw.println(“<p style=“font-weight: bold;color: red;”>welcome to MyTomcat”);
- pw.println(“”);
- s.close();
- tomcat.close();
- } catch (IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
我们先启动服务器,然后运行浏览器模拟网页浏览的过程,首先看到服务器端收到的请求信息:
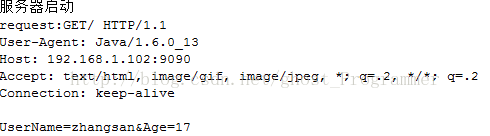
紧接着,服务器收到请求进行处理后,返回资源给浏览器,于是得到输出信息:

可以看到,我们在山寨浏览器当中得到的返回信息,实际上就是一个HTML文件的源码,
之所以我们的山寨浏览器中,这些信息仅仅是以纯文本形式显示,是因为我们的山寨浏览器不具备解析HTML语言的能力。
所以说,浏览器另外一个重要的功能其实就是:可以对超文本标记语言进行解析。而实际上,这也是浏览器开发的难点和重点。
上面这样的输出结果看上去显然不爽,所以说山寨货毕竟还是坑爹!
我们还是通过正规的WEB浏览器,来试着访问一下我们的山寨服务器,结果发现,效果帅多了:

而顺带一提的是,既然当浏览器向WEB服务器发起访问请求时,会封装有对应的HTTP请求体。
那么,对应的,当WEB服务器处理完浏览器请求,返回数据时,也会有对应的封装,就是所谓的HTTP响应体。
举例来说,假如我们将我们的山寨浏览器的代码进行修改,去连接真正的tomcat服务器:
[java]
view plain
copy
- public class MyBrowser {
- public static void main(String[] args) {
- try {
- Socket browser = new Socket(“192.168.1.102”, 8080);
- PrintWriter pw = new PrintWriter(browser.getOutputStream(),true);
- // 封装请求第一行
- pw.println(“GET / HTTP/1.1”);
- // 封装请求头
- pw.println(“User-Agent: Java/1.6.0_13”);
- pw.println(“Host: 192.168.1.102:8080”);
- pw
- .println(“Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2”);
- pw.println(“Connection: keep-alive”);
- // 空行
- pw.println();
- // 封装实体主体
- //pw.println(“UserName=zhangsan&Age=17”);
- // 写入完毕
- browser.shutdownOutput();
- // 接受服务器返回信息,
- InputStream in = browser.getInputStream();
- //
- int length = 0;
- StringBuffer request = new StringBuffer();
- byte[] buf = new byte[1024];
- //
- while ((length = in.read(buf)) != -1) {
- String line = new String(buf, 0, length);
- request.append(line);
- }
- System.out.println(request);
- //browser.close();
- } catch (IOException e) {
- System.out.println(“异常了,操!”);
- }finally{
- }
- }
- }
运行程序,你将会发下如下的输出信息:
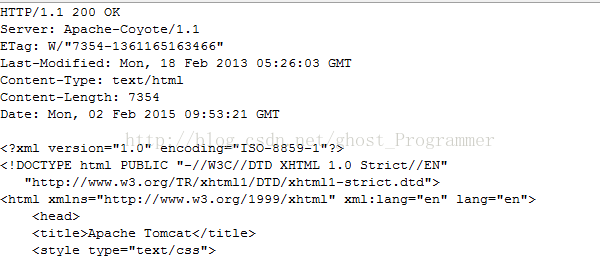
与HTTP请求类似,通常一个HTTP响应也包含三个部分:
- 协议/响应码/状态描述:协议也就是指HTTP协议的信息,响应码是指代表该次请求的处理结果的码(例如常见的200、404、500),其实就是该次请求处理的响应描述
- 响应标头:响应标头也包含与HTTP请求中的标头类似的有用信息。
- 响应实体:通常也就是指响应本身的HTML内容。
与HTTP请求一样,响应表头与响应实体之间,也会使用一个空行进行分割,方便解读。
同时我们也可以发现,其实真正被解析显示在浏览器网页上的内容,其实只是响应实体的部分。
响应行和响应标头当中,实际上是负责将相关的一些有用信息返回给我们,但这部分是不需要在浏览器中所展示的。
也就是说,我们的浏览器除了应当具备获取一个完整的HTTP响应的能力之外,还应该具备解析HTTP协议响应的能力。
事实上,Java也为我们提供了这样的对象,那就是URL及URLConnection对象。
如果我们在我们的山寨浏览器中,植入这样的对象,来进行与服务器之间的HTTP通信,那么:
[java]
view plain
copy
- public class MyBrowser2 {
- public static void main(String[] args) {
- try {
- URL url = new URL(“http://192.168.1.102:8080”);
- HttpURLConnection conn = (HttpURLConnection) url.openConnection();
- InputStream in = conn.getInputStream();
- byte[] buf = new byte[1024];
- int length = 0;
- StringBuffer text = new StringBuffer();
- String line = null;
- while ((length = in.read(buf)) != -1) {
- line = new String(buf, 0, length);
- text.append(line);
- }
- System.out.println(text);
如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
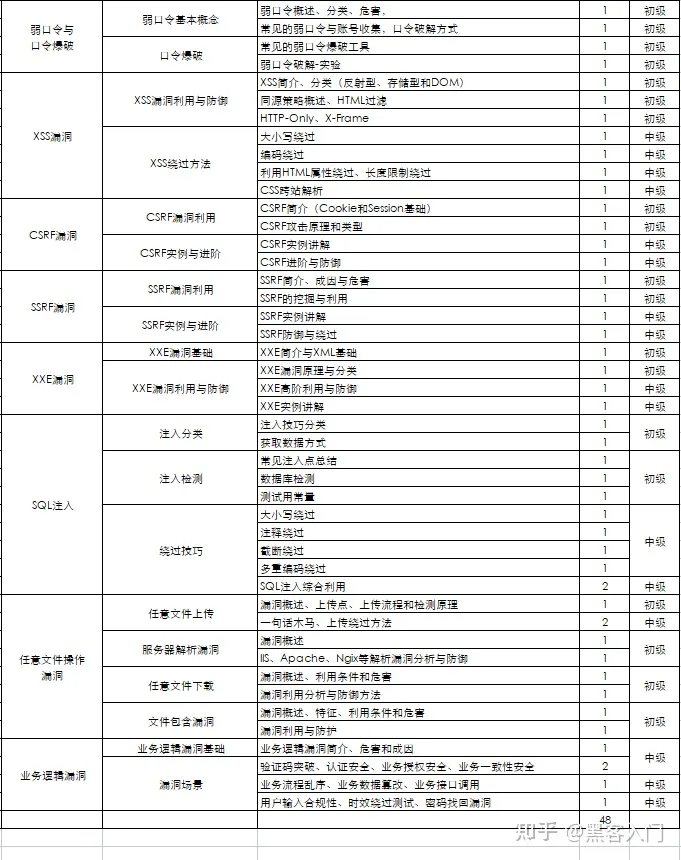
网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
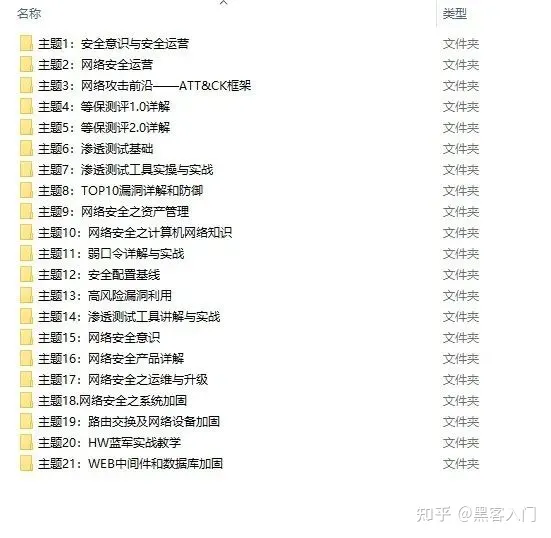
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 8338
8338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









