







在完成这篇博文时,参考了以下网站:
(1)http://blog.163.com/jw_67/blog/static/136199256201031310142614/
(2)http://blog.csdn.net/karen99/article/details/7771743
(3)http://www.dakaren.com/index.php/archives/389.htm
(4)http://www.cppblog.com/abilitytao/archive/2013/02/22/198007.html
(5)http://guoyb.com/Tech/32.html
*********************************************************************************************************************************
(1)中给出了粒子滤波在目标跟踪中的算法流程及相应的OpenCV代码。
(2)结合一个具体的例子阐述了卡尔曼滤波思想,直白地解释了卡尔曼滤波中的状态方程和测量方程的含义。
(3)结合一个具体例子阐述了粒子滤波的算法思想和步骤,推荐。
(4)讲述粒子滤波用于机器人定位。
(5)也是对粒子滤波的理解和描述,推荐。
另外给大家推荐几篇paper和slides
(a)Sanjeev Arulampalam, M., et al. "A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking." Signal Processing, IEEE Transactions on 50.2 (2002): 174-188. 这篇文章是关于粒子滤波的经典论文,几乎每篇基于粒子滤波框架实现跟踪的文章都要引用它。截止到目前,这篇论文的引用次数已经超过了7300次。强烈推荐大家读一下这篇paper!
(b)程水英, 张剑云. "粒子滤波评述." 宇航学报 29.4 (2008): 1099-1111. 这篇文章可以看成是上面的翻译版和简化版。
(c)西安交大蔡远利老师的课件《PARTICLE FILTERING》,可以在新浪爱问上免费下载:http://ishare.iask.sina.com.cn/f/23292474.html.
(d)Particle Filters and Applications in Computer Vision, Maître de Conférences - Université de Bourgogne. 这个Slides写得很不错,推荐。
一年前做毕业设计的时候就接触到了粒子滤波,之前一直没怎么研究过,最近几天下定决心一定要把粒子滤波搞懂。上个月从图书馆借了一本书《粒子滤波算法及其应用》,但是书中全是公式的推导,搞得云里雾里的。
下面忽略具体细节,只给出粒子滤波的算法框架。
我们开始从动态空间模型引入粒子滤波。时变问题分析的一般动态状态空间模型分为状态转移模型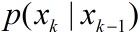
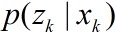
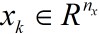
k的状态变量,
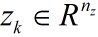
k的测量值。对于非线性、非高斯过程,模型可表示为
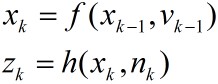
其中和
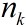


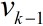
下面就说一下有了数据之后,如何进行处理。有两种方法,批处理和自适应(序贯)处理。在批处理中,一次全部接受并保存整个数据块,然后基于整个数据块进行有关状态x的推理,随着数据量的增加,计算量将急剧增大,实时性不强。自适应处理在接收数据的同时进行序贯推理,每接收到一个新的测量值z,就对x的部分或全部结果做一次更新,可以对动态系统的状态进行实时估计。
要得到后验概率密度

1)预测
利用Chapman-Kolmogorov方程得,
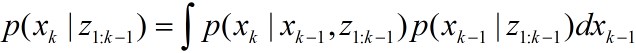
又
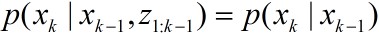
可得
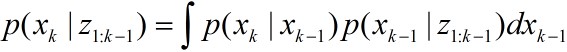
2)更新
在时刻k,得到测量值
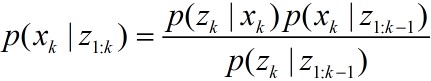
其中
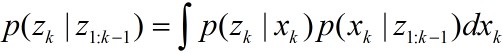
上述递归式只是一个概念意义上的解,对于非线性非高斯系统无法获得解析,所以我们只能求近似解。
首先介绍一下蒙特卡罗(Mente Carlo, MC)思想。大家接触蒙特卡罗一般是从微积分开始,或者概率论中对一些参数,比如pi的估计问题。考虑积分问题





可以证明
上述蒙特卡罗方法是利用一系列的采样值估计函数的积分值,其实质是用频率来近似概率,而粒子滤波方法是使用粒子分布的密集程度来近似表示后验概率密度。接着要说序贯重要性采样(Sequential Importance Sampling, SIS),它利用蒙特卡罗仿真(或者说模拟)来执行递归贝叶斯滤波。利用一些带有相应权值的随机样本(称为粒子)来代表要求的后验密度函数,并利用这些粒子和它们的权值计算状态估计(比如






至此我们就得到了真实后验密度函数的一个离散带权估计。选择权值是依据重要性采样原则。一般情况下很难从




因此若样本


若有
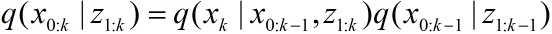
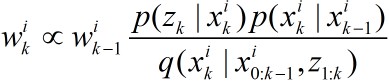
若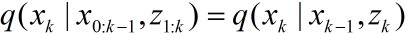




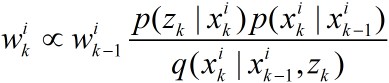
后验滤波密度可以被近似为
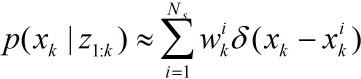
下面给出SIS算法的伪代码:

其中的(48)即是上面的(*2)式。
下面通过一个图更好地解释SIS:
遗憾的是SIS会产生退化问题。经过一系列迭代之后,大多数粒子的权值变得非常小,几乎微不足道,权值只集中在很少的几个粒子上。这意味着大量的计算花费在对于近似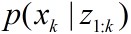
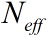

其中
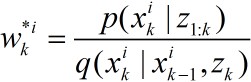
上面的
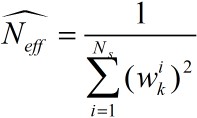
这里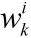

为了解决退化问题,可以增加粒子数目,即增大
i)选取好的重要密度

最优的重要性密度为
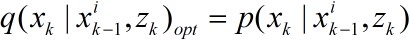
相应的权值为
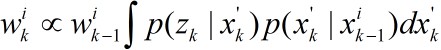
这在实际应用中难以实现。通常的做法是选取先验作为重要性密度,即
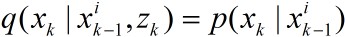

ii)重采样(Resampling)的基本思想是剔除权值较小的粒子,对于权值较大的粒子按照其权值大小进行复制。具体做法是从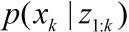

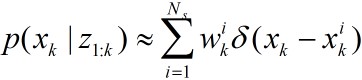


可以通过下图对采样和重采样有一个直观的认识:
在算法中我们通常给定一个阈值

下面给出重采样算法的伪代码:

至此我们就对粒子滤波算法的核心部分进行了简单地阐述,重点介绍了序贯重要性采样(SIS)和重采样(Resampling)。下面给出一般粒子滤波算法的伪代码:

上面描述了粒子滤波算法的整个流程和伪代码,下面给出一个具体的程序。我们使用M. Sanjeev Arulampalam论文中的例子:
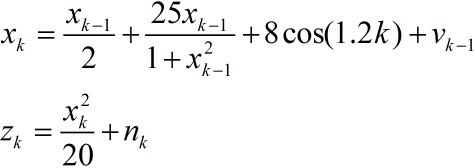
其中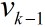
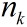
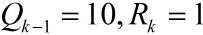

主程序
clear all;
Ns=1000;%粒子数目
v1=5;%x1方差
v=10;%过程噪声方差
n=1;%测量噪声方差
ts=100;%时间序列
Gau=inline('1/(2*pi*1)^(1/2)*exp(-(x.^2)/(2*1))');%高斯函数
f=inline('x./2+25*x./(1+x.^2)+8*cos(1.2*t)','x','t');%f
h=inline('(x.^2)/20');%h
x=zeros(1,ts);%存储状态变量
z=zeros(1,ts);%存储测量值
x(1)=sqrtm(v1)*randn(1);%初始状态变量x1
z(1)=feval(h,x(1))+sqrtm(n)*randn(1);%测量值z1
for t=2:ts %仿真系统
x(t)=feval(f,x(t-1),t-1)+sqrtm(v)*randn(1);
z(t)=feval(h,x(t))+sqrtm(n)*randn(1);
end
xTrue=x;%真实值
xHat=Sim(f,h,Gau,v,v1,Ns,z);%仿真值
plot(1:ts,xHat,'b--',1:ts,xTrue,'r');%作图对比
xlabel('时间序列');
legend('状态估值','状态真值');
title('粒子滤波仿真实验');
grid on;
RMSE=sum((xTrue-xHat).^2);
RMSE=sqrt(RMSE/ts)%计算均方根误差function [xHat]=Sim(f,h,Gau,v,v1,Ns,z)
n=size(v1,2);
x=sqrtm(v1)*randn(n,Ns);% 1.初始化粒子
ts=size(z,2);
xHat=zeros(1,ts);
for t=1:ts
e=z(t)-h(x);% 2.残差
w=feval(Gau,e);%利用高斯函数将残差映射成权值
w=w/sum(w);%权值归一化
xHat(t)=sum(repmat(w,n,1).*x,2);%将粒子加权求和作为近似值
ind=Resampling(w);% 3.重采样
x=x(:,ind);%新的粒子
x=feval(f,x,t)+sqrtm(v)*randn(n,Ns);% 4.更新状态值
endfunction [ind]=Resampling(w)
c=cumsum(w);
Ns=length(w);
u=((0:Ns-1)+rand(1))/Ns;
ind=zeros(1,Ns);
i=1;
for j=1:Ns
while(c(i)<u(j))
i=i+1;
end
ind(j)=i;
end使用Matlab运行结果:
RMSE =
3.9465
大家初看粒子滤波的时候很容易被里面复杂的公式和名词弄得一头雾水,不妨先看一下上面的代码,在Matlab上运行一下,可能就一目了然了,然后再去看算法的理论细节。文中多有不严谨之处,还请大家多多指教。















 1489
1489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









