







 本文深入探讨GRU和LSTM的代码实现,以2-gram语言模型为例,介绍了网络结构,包括GRU和LSTM的输入层、隐层结构,并通过详细推导解释了梯度计算过程,特别关注了bptt的部分。
本文深入探讨GRU和LSTM的代码实现,以2-gram语言模型为例,介绍了网络结构,包括GRU和LSTM的输入层、隐层结构,并通过详细推导解释了梯度计算过程,特别关注了bptt的部分。
RNN学习笔记(六)-GRU,LSTM 代码实现
在这篇文章里,我们将讨论GRU/LSTM的代码实现。在这里,我们仍然沿用RNN学习笔记(五)-RNN 代码实现里的例子,使用GRU/LSTM网络建立一个2-gram的语言模型。
项目源码:https://github.com/rtygbwwwerr/RNN
参考项目:https://github.com/dennybritz/rnn-tutorial-gru-lstm
1.网络结构
为了解决当词典中的words数量很大时,输入向量过长的问题,我们在输入层和隐层之间引入了Embedding Layer,通过该层,输入的one-hot将被转换为word的Embedding vector。
1.1 GRU网络
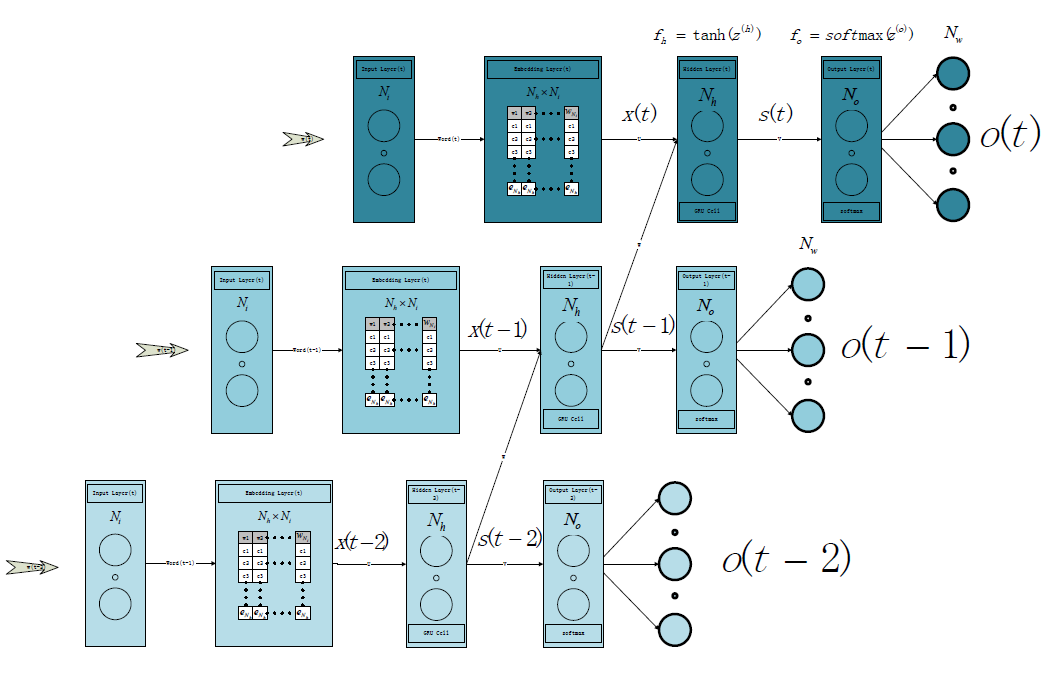
1.2 LSTM网络
略。
2.代码实现
这里我们重点讨论bptt部分(*:“ ⊙ ”表示elemwise乘法运算)。对于GRU网络来说,有
softmax(x)′=softmax(x)[1−softmax(x)]
输出层节点的输入值 z(o)k(t) 导数如下:
δ(o)k(t)=∂Lt∂z(o)k(t)
=ok(t)−1
写成向量形式为:
δ(o)(t)=o(t)−1
∂Lt∂V=δ(o)k(t)∂z(o)k(t)∂V=[ok(t)−1]⊙st
可以看到,这一层的导数与常规RNN是一致的。
从隐层开始,导数将有所不同,我们先来看下单个GRU网络节点结构:
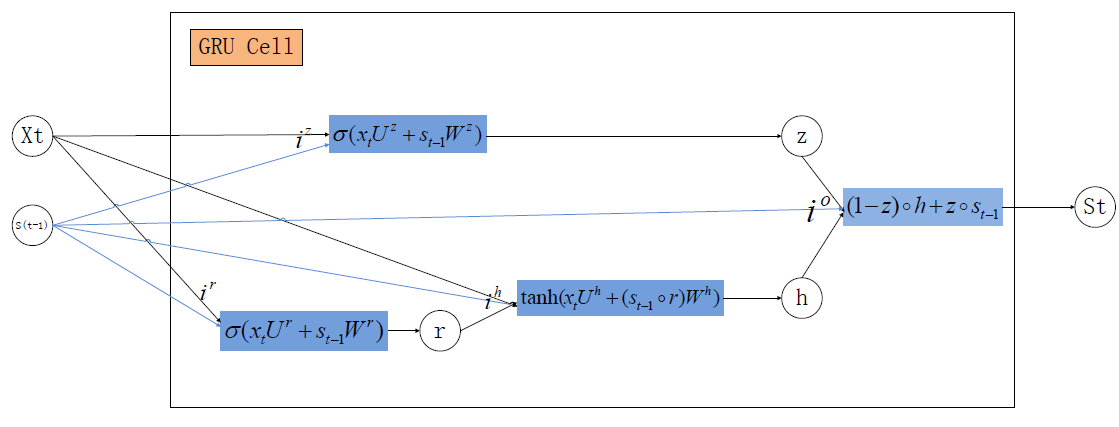
这里,先对符号做一下约定:
iz(t)=xtUz+s(t−1)Wz :t时刻update gate 对应的输入
ir(t)=xtUr+s(t−1)Wr :t时刻rest gate 对应的输入
ih(t)=xtUh+(s(t−1)⊙r(t))Wh :t时刻隐单元对应的输入
io(t)=(1−z(t))⊙h(t)+z(t)⊙s(t−1) :t时刻output gate对应的输入
f(io(t))=io
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









