







 该文使用Python对天津财政收支数据进行时间序列分析,包括导入数据、绘制图表、单位根检验、差分处理、白噪声检验、ARIMA模型选择与训练。通过BIC最小化选取最佳ARIMA参数,并进行模型检验与预测,最后讨论模型适用性。
该文使用Python对天津财政收支数据进行时间序列分析,包括导入数据、绘制图表、单位根检验、差分处理、白噪声检验、ARIMA模型选择与训练。通过BIC最小化选取最佳ARIMA参数,并进行模型检验与预测,最后讨论模型适用性。
#导入相关的库
import pandas as pd
import numpy as np
from matplotlib import pyplot
import matplotlib.pyplot as plt
from matplotlib.pyplot import rcParams
#rcParams设定画布大小
rcParams['figure.figsize'] = 15, 6
#导入时序数据
data = pd.read_excel(r"C:\Users\18703\Desktop\天津市财政收支1996-2017.xlsx")
data.head()

tf = data[['税收收入']]
tf.index = data['年份']
tf.head()

检查数据是否为平稳序列
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
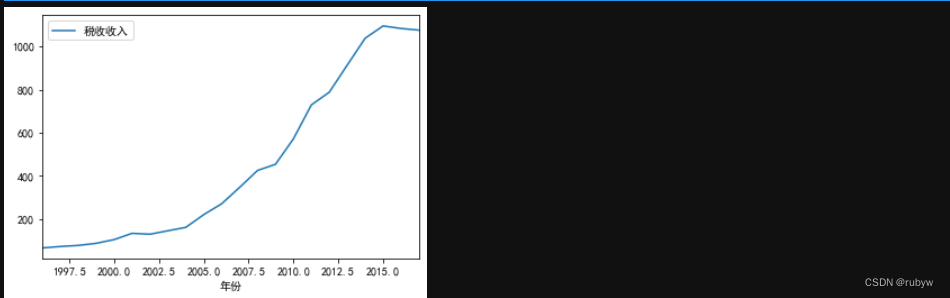
#绘制时序图
tf.plot()
plt.show()
#绘制自相关图
plot_acf(tf).show
#绘制偏自相关图
plot_pacf(tf).show
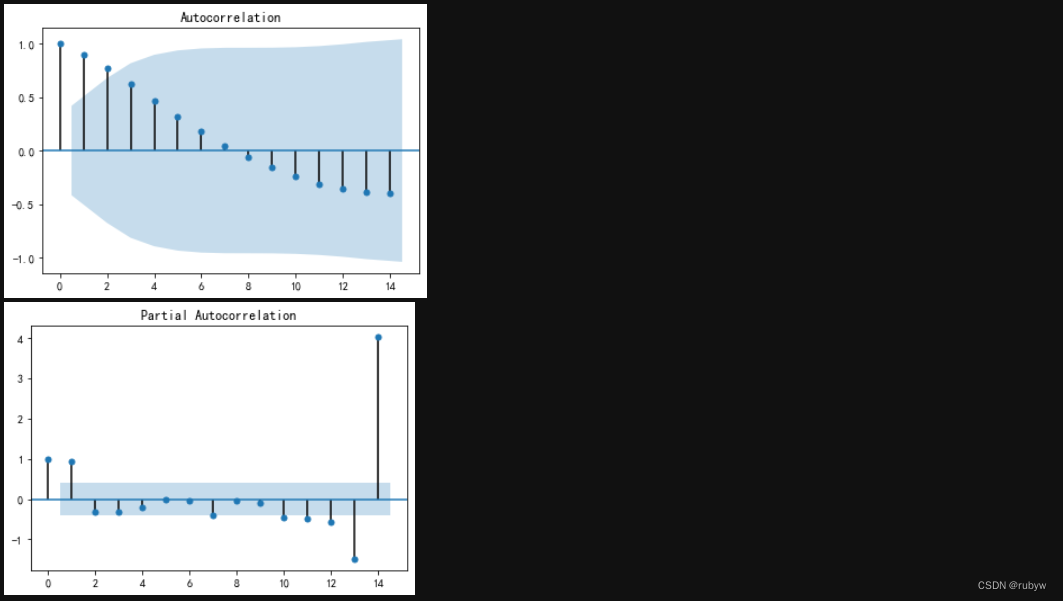
#单位根检验
from statsmodels.tsa.stattools import adfuller as ADF
ADF(tf['税收收入'])#第二个值为p值,p<0.05,拒绝原假设,不存在单位根

差分-转化为平稳序列
#1阶差分
tf_diff1 = tf.diff(1).dropna()
tf_diff1.columns = ['一阶差分']
tf_diff1.plot()
plt.show()

ADF(tf_diff1['一阶差分'])

#随机性检验(白噪声检验)
from statsmodels.stats.diagnostic import acorr_ljungbox
acorr_ljungbox(tf_diff1,lags=1) #p=0.00751547<0.05,拒绝原假设,所以一阶差分后的序列不是随机的

#由acf,pacf判断模型参数
plot_acf(tf_diff1).show()
plot_pacf(tf_diff1).show()

模型训练
#ARIMA(1,1,1)
from statsmodels.tsa.arima_model import ARIMA
from statsmodels.api import tsa
arima = ARIMA(tf, order=(1,1,1))
result = arima.fit(disp=False)
print(result.aic,result.bic,result.hqic)

plt.plot(tf_diff1)
plt.plot(result.fittedvalues, color='red')
plt.title('ARIMA RSS:%.4f' % sum(result.fittedvalues - tf_diff1['一阶差分']) ** 2)
plt.show() #RSS:累计平方误差
#根据bic遍历p,q值,取bic最小时对应的p,q
from statsmodels.tsa.arima_model import ARIMA
tmp = []
for p in range(4):
for q in range(4):
try:
tmp.append([ARIMA(tf,(p,1,q)).fit().bic,p,q])
except:
tmp.append([None,p,q])
tmp = pd.DataFrame(tmp,columns = ['bic','p','q'])
tmp[tmp['bic'] ==tmp['bic'].min()]
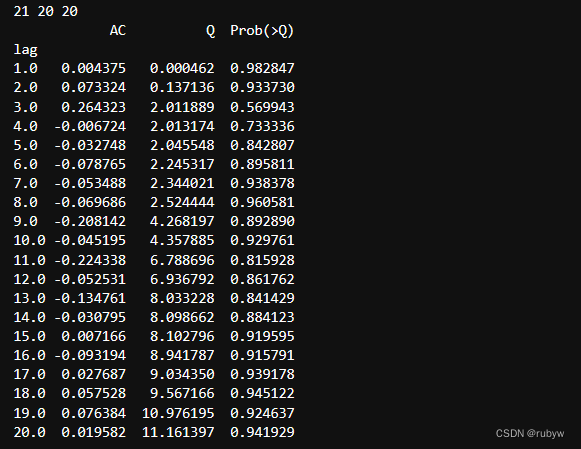
模型检验
# ARIMA Ljung-Box检验 -----模型显著性检验,Prod> 0.05,说明该模型适合样本
resid = result.resid
r, q, p = tsa.acf(resid.values.squeeze(), qstat=True)
print(len(r), len(q), len(p))
test_data = np.c_[range(1, 21), r[1:], q, p]
table = pd.DataFrame(test_data, columns=['lag', 'AC', 'Q', 'Prob(>Q)'])
print(table.set_index('lag'))
#原假设是相关系数为0
模型预测
tf.loc[2017]=None
tf.loc[2018]=None
predict = result.predict(22,23,dynamic=True)
print(predict)
fig,ax = plt.subplots(figsize=(12,8))
ax = tf.ix[1996:2018].plot(ax=ax)
# predict.plot(ax=ax)

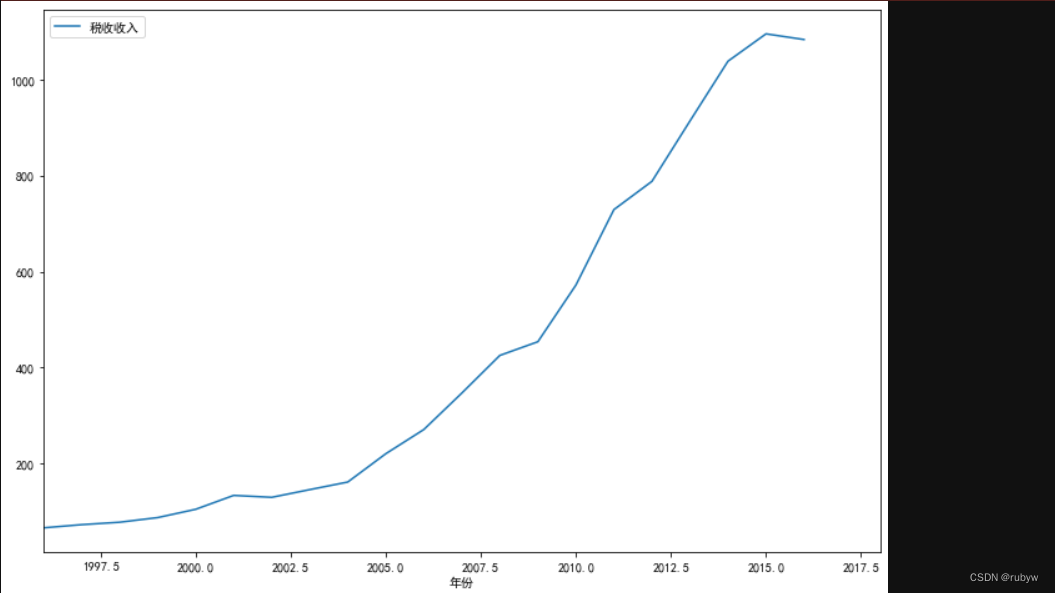
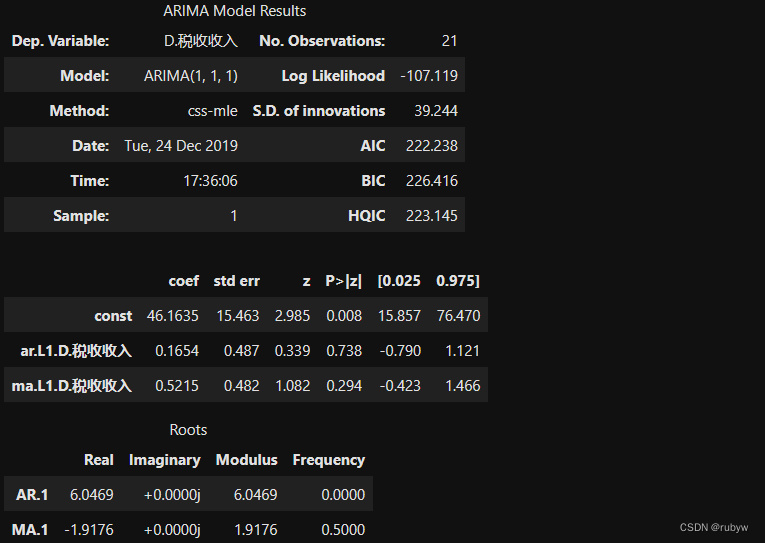
model = ARIMA(tf,(1,1,1)).fit()
model.summary()
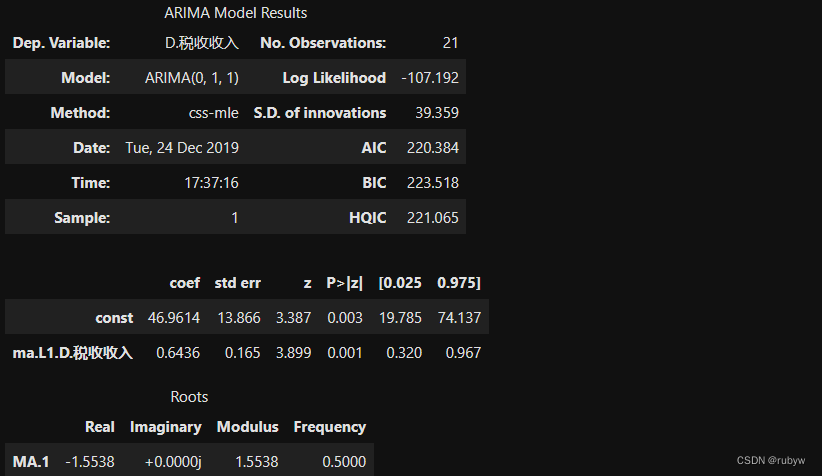
ARIMA(tf,(0,1,1)).fit().summary()
#预测未来5年
yp = model.forecast(5)
yp[0]

ARIMA(tf,(0,1,1)).fit().forecast(5)[0]

模型效果不好,时间序列分析方法不适用样本数据


















 2389
2389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











