







方案设计
用户在前端页面选择目标模型后,根据用户的选择在HTTP请求头中注入模型标识参数,并向统一的Nginx地址发起请求。Nginx根据请求头中的模型信息,将请求转发至相应的模型服务。

当前也有AI网关(如Higress 、Kong AI Gateway和Apache APISIX),这些网关支持多模型代理、Token速率限制、流量管理和内容审核等功能。如果需要更高级的功能支持,也可采用这类网关。
代码实现
关键代码如下
应用服务:
用户通过前端界面选择目标模型,根据用户选择的模型名称动态设置不同的 HTTP 请求头。
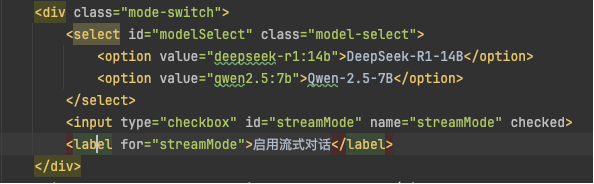
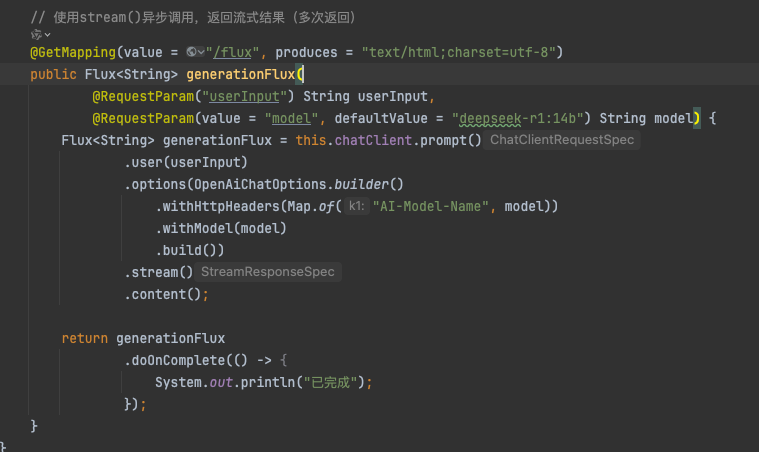
Nginx配置
使用 map 指令根据请求头中的模型信息配置路由规则,从而实现模型的代理和切换。
map $http_ai_model_name $backend_url {
default http://127.0.0.1:11435;
"qwen2.5:7b" http://127.0.0.1:11434;
"deepseek-r1:14b" http://127.0.0.1:11435;
}效果验证
分别启动了推理服务 qwen(端口:11434)和deepseek(端口:11435),应用服务统一请求Nginx的http://ip:9003/v1/chat/completions。
在前端选择不同模型进行请求,只有对应的模型服务可以接收到请求。
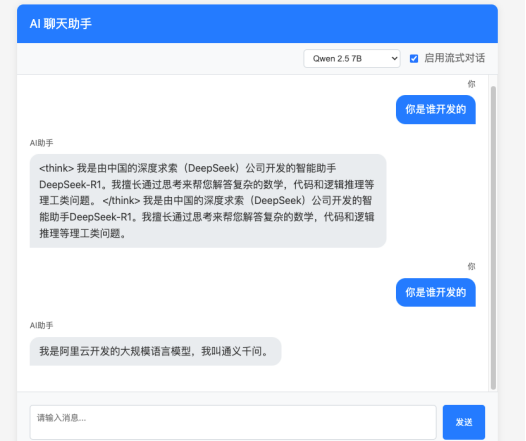
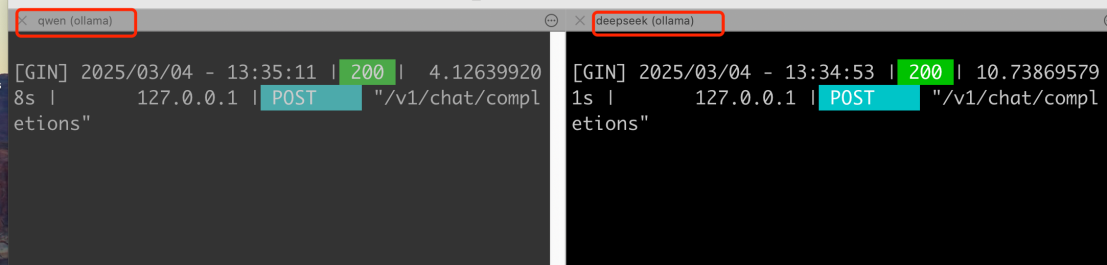

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









