







文章目录
刷题记录5.14-5.20
930.和相同的二元子数组
class Solution {
public:
int numSubarraysWithSum(vector<int>& nums, int goal) {
int sum = 0, res = 0;
unordered_map<int, int> hash;
for(int num : nums)
{
hash[sum]++;
sum += num;
res += hash[sum-goal];
}
return res;
}
};
这里是将前缀和与哈希表结合起来的应用,还是很有价值的一道题!这里hash是map类型的哈希表,我当时考虑下标越界的情况,实际上是不会的,它只是int到int类型的映射,只需要[]内的数值在int的范围内,都是能表示的,例如hash[-1]的值初始化就是0,所以根本不需要对hash进行判断溢出的操作。还有一个值得注意的点:循环里一定要是hash[sum]++这一条语句为先,因为最开始前缀和是为0的。每次res累加的是[0,i]的前缀和,goal用(i,j]来表示,sum值表示[0,j]的前缀和
1524.和为奇数的子数组数目
class Solution {
public:
int numOfSubarrays(vector<int>& arr) {
int sum = 0, res = 0, odd = 0, even = 1;
int mod = 1e9+7;
for(int num : arr)
{
sum += num;
res = (res + (sum%2 == 0 ? odd : even))%mod;
if(sum%2 == 0) even++;
else odd++;
}
return res;
}
};
这个题与前面的题还是少许有些不同,这里完全不需要哈希表来记录前缀和,由于只是要求符合条件的子数组数目,所以这里只是定义了两个变量分别记录前缀和为奇数的个数和前缀和为偶数的个数odd和even,这里odd初始化为0,而even初始化为1,因为前缀和0也是偶数,这样在后续遇到第一个前缀和为奇数的数组时res才能做到累加的效果。sum用来求前缀和,res用来记录符合条件的数量。我觉的吧,对于前缀和问题,下标还是很重要的,我的理解是:这里的odd和even其实也充当了数组下标的意思,如果此时sum累加到偶数,那么res就累加前面出现奇数子数组的数目,这样就求得了到当前下标符合和为奇数的子数组的数目,然后累加到res中,这一题的代码固然简单,我感觉主要是要理解它这个变量用到的妙处。
动态规划写法(很像前面刷过的买卖股票其中一个问题!):
class Solution {
public:
int numOfSubarrays(vector<int>& arr) {
//dp[i][0]---以i-1为结尾符合偶数的个数
//dp[i][1]---以i-1为结尾符合奇数的个数
vector<vector<int>> dp(arr.size()+1, vector<int>(2, 0));
int res = 0;
for(int i = 1; i <= arr.size(); i++)
{
if(arr[i-1]%2 == 0)
{
dp[i][0] = dp[i-1][0]+1;
dp[i][1] = dp[i-1][1];
}
else
{
dp[i][0] = dp[i-1][1];
dp[i][1] = dp[i-1][0]+1;
}
res = (res+dp[i][1])%1000000007;
}
return res;
}
};
974.和可被k整除的子数组
class Solution {
public:
int subarraysDivByK(vector<int>& nums, int k) {
unordered_map<int, int> hash;//key---前缀和%k value---次数
hash[0] = 1;//这里必须初始化为1
int res = 0, sum = 0;
for(int num : nums)
{
sum += num;
int temp = (sum%k+k)%k;
//一定不能写成res+=hash.count(temp),hash.count()只会返回0和1,
//代表哈希表键的个数,哈希表中一个键只能出现一次
if(hash.count(temp)) res += hash[temp];
hash[temp]++;
}
return res;
}
};
这个题其实和974很像很像,但是我就是写不出写不出!我感觉很妙的点都是在它求出符合条件的区间的方式!我不知道怎么来形容,可能是要根据题目的特点吧!感觉还是需要题量来增加这种认知范围的。与简单的前缀和不同,他们都不是单纯的前缀和下标相减求出区间前缀和。普通的前缀和:a[i,j] = a[j]-a[i-1],这两道题的方式呢我描述起来感觉也很晦涩,就是有种说不出的感觉,其实吧,这也和定义哈希表的含义有很大的关系!
此题哈希表代表的是key—前缀和%k value—次数的映射,这里的哈希表一定得初始化一下,hash[0]=1否则可能会与预期答案相差一,初始化为1的目的就是为了让第一个恰好模k为0的计数加一而不是0,其实930也有初始化,就是hash[sum]++;因为sum的初始化就为0,所以它是在循环开始的位置就初始化了,而这一题就不能交换顺序,temp和sum的顺序是有因果关系的。再就是求temp的细节,对于C++来说负数取模会导致结果为负数,所以当要考虑被除数为负数的时候取余的模板就是temp = (sum%k+k)%k;当然这对正数也适用。
举个哈希表在循环体里的例子吧:[4,5,0,-2,-3,1]中首先是hash[4]++,到下一个元素5的时候sum=9,temp=4,res +=1,res就变成了1,hash[4]++,即hash[4]=2;再到下一个元素0,sum=9,temp=4,res+=2即res=3,hash[4]=3。[4,5]和[4]的前缀和是同余的,这样就求出了区间[5],[4]、[4,5]、[4,5,0]是同余的,这样就求出了区间[5],[0],[5,0]也就是此时res=3的由来。关键就在于s[i]和s[j]同余,那么s[i,j]就是可被k整除的子数组,s[j]-s[i]就恰好将余数相减了!
1893.检查是否区域内所有整数都被覆盖
class Solution {
public:
bool isCovered(vector<vector<int>>& ranges, int left, int right) {
vector<int> diff(52);
for(auto q : ranges)
{
int l = q[0], r = q[1]+1;
diff[l]++;
diff[r]--;
}
int sum = 0;
for(int i = 0; i <= right; i++)
{
sum += diff[i];
if(i >= left && i <= right && sum == 0) return false;
}
return true;
}
};
这是一道差分数组的题目,与2848基本是一样的,都是解决区间是否覆盖的问题,具体解题步骤如下:首先定义一个差分数组,数组长度一定至少要比访问区间的长度大2,因为要空出一个diff[0]位和延申一个diff[n]位,然后就是遍历二维数组ranges,每次取出其左右边界[l,r],然后diff[l]++和diff[r+1]–,注意一定是diff[r+1],也就是diff数组要延申出最后一位的原因,这一步操作的目的是让覆盖的区域[l,r]都加上1,差分数组只需要在左边界l上和右边界+1r+1上的地方操作,diff[l]++和diff[r+1]–这两步是固定不变的,如果是想让区间加10就改写成diff[l]+=10和diff[r+1]-=10。sum用来表示差分数组的前缀和,不断的对差分数组求前缀和就求出了对应的原数组,这是前缀和、差分数组、原数组之间的转换关系。if判断语句就是当遇到访问区间时需要进行判断的,只要这个区间内有一个数是小于0的,那么就返回false,如果能遍历完整个区间就返回true。
2960.统计已测试设备
丑陋写法:
class Solution {
public:
int countTestedDevices(vector<int>& batteryPercentages) {
vector<int> diff(102);
int n = batteryPercentages.size();
int count = 0;
for(int i = 0; i < n; i++)
{
if(batteryPercentages[i] > 0)
{
count++;
for(int j = i+1; j < n; j++)
{
batteryPercentages[j] = max(0, batteryPercentages[j]-1);
}
}
}
return count;
}
};
高级写法:
class Solution {
public:
int countTestedDevices(vector<int>& batteryPercentages) {
int count = 0;
for(int x : batteryPercentages)
{
count += x > count;
}
return count;
}
};
丑陋写法也就是根据题意来写。。。写了覆盖问题之后就单纯只去考虑了diff数组,怎么用diff数组去求前缀和,当时在思考的时候就感觉这样挺复杂的,毕竟diff数组也不好初始化,所以一种题型还是仅适用一种题型,差分数组还能以不同的形式应用在不同的题型中。而对于这一题呢通过在[i+1,n-1]区间的元素都要-1这种字眼就能看出这是一个差分数组题,通常要对一个区间进行加减操作就是用到的差分数组。这里是用的count表示需要减一的次数,同时需要减一的次数也就对应的题干中对设备进行检查的次数,遍历x时如果大于count就表明这是符合条件的元素,计数++。关键是掌握这种巧妙的技巧吧,当数据很庞大的时候丑陋的写法肯定是过不了的,所以划星星,这个技巧重点掌握!
1094.拼车
class Solution {
public:
bool carPooling(vector<vector<int>>& trips, int capacity) {
vector<int> diff(1001);
for(auto q : trips)
{
diff[q[1]] += q[0];
diff[q[2]] -= q[0];
}
int sum = 0;
for(int s : diff)
{
sum += s;
if(sum > capacity) return false;
}
return true;
}
};
此题与1854很像,但是1854在题中具体给出了 x 在闭区间 [birthi, deathi - 1] 内。注意,人不应当计入他们死亡当年的人口中。 而这一题并没有给出当乘客到to的时候已经是下车状态,所以这两道题都有一个相同的特点就是都是左闭右开区间[i,j),这告诉我们什么?不能完全相信题目!当然这两题也给我了警告,就是对于差分数组右边界的开闭情况是一定要根据题目的意思来看的,有的案例是开闭情况都能通过的,在这两题中开闭都能通过示例样例但不能通过全部案例,这也是需要细心的地方。
1109.航班预定统计
class Solution {
public:
vector<int> corpFlightBookings(vector<vector<int>>& bookings, int n) {
vector<int> diff(n+2);
for(auto q : bookings)
{
diff[q[0]] += q[2];
diff[q[1]+1] -= q[2];
}
vector<int> res;
int sum = 0;
for(int i = 1; i < n+1; i++)
{
sum += diff[i];
res.push_back(sum);
}
return res;
}
};
总体性分析:差分问题,分析案例的答案得出这是一道左闭右闭区间的差分数组问题,所以diff定义的长度为n+2,与前面几题不同的是这里返回的答案是原数组,也就是需要经过差分数组求前缀和得到的数组。我觉得在求原数组的过程中重点关注的就是下标的问题,由于题中在对差分数组赋值的时候最小下标都是大于0的,这也便于我们求差分数组,换成ioi赛制时也最好养成这种习惯,所以我们原数组的下标也会是从1开始,当前的前缀和就是当前的原元素,不需要考虑其他的情况,原数组的长度是多少i就遍历到多少这样就不会为边界而烦恼了。累加到diff[1]就是原数组的a[1],起点是从1开始!不是从0开始!
547.省份数量
dfs写法:
class Solution {
public:
void dfs(vector<vector<int>>& isConnected, vector<int>& visited, int n, int i)
{
//深度往下搜索
for(int j = 0; j < n; j++)
{
//相连
if(isConnected[i][j] == 1 && !visited[j])
{
visited[j] = 1;//这里写i写j都是对的
dfs(isConnected, visited, n, j);
}
}
}
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size();
vector<int> visited(n);
int res = 0;
//遍历连通块
for(int i = 0; i < n; i++)
{
if(!visited[i])
{
dfs(isConnected, visited, n, i);
res++;
}
}
return res;
}
};
bfs写法:
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size();
int ans = 0;
vector<bool> visited(n, false);
deque<int> q;
//遍历连通块有多少个
for(int i = 0; i < n; i++)
{
//未被访问过 广度优先遍历
if(!visited[i])
{
q.push_back(i);
while(!q.empty())
{
//取出队首元素
int j = q.front();
q.pop_front();
visited[j] = 1;//一定要更改哈希数组,否则死循环
//遍历当前节点有多少需要入队的
for(int k = 0; k < n; k++)
{
//遍历这一层,将未被访问过的地方入队
if(!visited[k] && isConnected[j][k] == 1) q.push_back(k);
}
}
//将一个连通块遍历完之后计数器才累加1
ans++;
}
}
return ans;
}
};
细节都在注释上了,除了注释之外的,还需要加强的点就是要清晰明白每一个循环它的作用在哪
并查集写法:
class Solution {
public:
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size();
vector<int> uf(n);
iota(uf.begin(), uf.end(), 0);
function<int(int)> find = [&] (int x) -> int {
if(uf[x] != x) uf[x] = find(uf[x]);
return uf[x];
};
for(int i = 0; i < n; i++)
{
for(int j = i; j < n; j++)
{
if(isConnected[i][j] == 1) uf[find(i)] = find(j);
}
}
int ans = 0;
for(int i = 0; i < n; i++)
{
if(uf[i] == i) ans++;
}
return ans;
}
};
掌握了并查集模板之后难点就在于如何求出连通块的数量,这里只需要遍历一遍uf数组,查看一共有几个节点的父节点指向自己,这就是最后的答案ans。
1971.寻找图中是否存在路径
dfs写法:
class Solution {
public:
bool dfs(int source, int destination, vector<vector<int>>& graph, vector<bool>& visited)
{
if(source == destination) return true;
visited[source] = true;
for(int next : graph[source])
{
if(!visited[next] && dfs(next, destination, graph, visited)) return true;
}
return false;
}
bool validPath(int n, vector<vector<int>>& edges, int source, int destination) {
vector<vector<int>> graph(n);
for(auto q : edges)
{
graph[q[0]].push_back(q[1]);
graph[q[1]].push_back(q[0]);
}
vector<bool> visited(n, false);
return dfs(source, destination, graph, visited);
}
};
大致的思路还是能想到,唯一卡住我的点就在不知道怎么退出递归得到对应的bool值,感觉和之前的回溯章节很像,基本步骤都是确定函数参数、递归出口、for循环横向递归、要有哈希数组来保存已经访问过的节点。注意一下,这一题和547的dfs遍历方式其实有点区别的,isConnected数组和graph数组不是同一种类型的二维数组,但是整体来说是dfs,只是有些细节上有些差异。介绍一下两个邻接矩阵的差异:547中的iConnected数组在没有连接关系的时候isConnected[i] [j] = 0,而在1971中如果两个点没有关系是不会push_back到graph数组中,所以两个二维数组之间就存在不同,所以遍历方式也要有所不同。
bfs写法:
class Solution {
public:
bool validPath(int n, vector<vector<int>>& edges, int source, int destination) {
vector<bool> visited(n, false);
vector<vector<int>> graph(n);
deque<int> q;
//创建邻接表
for(auto q : edges)
{
graph[q[0]].push_back(q[1]);
graph[q[1]].push_back(q[0]);
}
//以source为起点广度优先搜索
q.push_back(source);
while(!q.empty())
{
//取出当前队首元素vertex
int vertex = q.front();
q.pop_front();
//如果vertex和destination一样那么表明已经能判断从source到destination了
if(vertex == destination) return true;
//如果队首节点已经访问过了 就无需再操作了,没有这句话会超时
if(!visited[vertex])
{
visited[vertex] = true;
for(auto next : graph[vertex])
{
if(!visited[next]) q.push_back(next);
}
}
}
return false;
}
};
并查集写法:
class Solution {
public:
bool validPath(int n, vector<vector<int>>& edges, int source, int destination) {
vector<int> uf(n);
//对应init()
iota(uf.begin(), uf.end(), 0);
//查找x的祖先 对应find(int x)
function<int(int)> find = [&](int x) -> int {
if(uf[x] != x) uf[x] = find(uf[x]);//状态压缩
return uf[x];
};
//合并操作对应unionuf
for(auto q : edges)
{
uf[find(q[0])] = find(q[1]);
}
return find(source) == find(destination);
}
};
这里是并查集和lambda表达式都用上了,就一起学吧!uf用来表达父子关系的并查集数组,iota(uf.begin(), uf.end(), 0)是数组的初始化操作,因为每个节点的父亲都是默认为自己,解释一下uf[i] = j:表示i的父亲为j这一点很重要。然后就是lambda表达式,function<int(int)> find定义了一个参数为int返回值为int的find函数,()里的类型代表的find的参数类型,下面给出lambda表达式的通式:

[]中填&表示按引用获取所有外部的变量,填=表示按值获取所有外部的变量
并查集模板:
//定义并查集数组
vector<int> uf(n);
//初始化每个节点 将其父节点指向自己
void init()
{
for(int i = 0; i < n; i++) uf[i] = i;
}
//初始化的另一种方式 表示从0开始给容器uf中的元素赋值
iota(uf.begin(), uf.end(), 0);
int find(int x)
{
//包含状态压缩
if(uf[x] != x) uf[x] = find(uf[x]);
return uf[x];
}
void unionuf(int i, int j)
{
int i_father = find(i);
int j_father = find(j);
uf[i] = j;
//这一句在联通问题时可以不写,如果涉及到集合大小的题就需要这一句,也不知道作用是啥,先记下来吧
size[j] += size[i];
}
1、dfs和bfs一定要在邻接表中遍历,所以,题中如果没有给出邻接表的话就需要自己初始化邻接表
2、dfs广度优先搜索可以从任意位置开始搜索,而dfs深度优先搜索只能从邻接表(0,0)开始搜索,例如1971先入队的时source节点
3、dfs和bfs无论如何都需要哈希数组来记录已经访问过的节点vector< bool > visited(n, false);n表示节点数量
797.所有可能的路径
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void dfs(vector<vector<int>>& graph, vector<bool>& visited, int cur)
{
//if(graph[cur].size() == 0)这个表示所有路径
//题干中明确了是节点0到节点n-1的路径
if(cur == graph.size()-1)
{
res.push_back(path);
}
for(int i = 0; i < graph[cur].size(); i++)
{
int temp = graph[cur][i];
if(!visited[temp])
{
visited[temp] = true;
path.push_back(temp);
dfs(graph, visited, temp);//是temp不是i
path.pop_back();
visited[temp] = false;
}
}
}
vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) {
path.push_back(0);
vector<bool> visited(graph.size(), false);
dfs(graph, visited, 0);
return res;
}
};
这一题与前面几题稍有不同,这一题只能用dfs来解决,求路径问题只能用dfs,更何况这一题要你求的是0-n-1的所有路径。注意哦,这里是0-n-1的所有路径,那么起点一定是0终点一定是n-1。这句话就对应的是dfs的退出条件,我最开始写的是if(graph[cur].size() == 0)从而导致的路径数在某些情况下会多余预期输出。还有这里可以不需要哈希数组visited来记录已经访问过的节点,回溯的过程中会自动弹出path。也从这个题的特点来看是否需要visited数组,这里的节点不可能存在闭环,也就不是一个联通图,正如题目所说它是一个有向无环图,那么就可以不使用visited数组,回顾前面几道题,它们都是无向图,如果不记录已经访问过的节点话会一直死循环地递归下去。
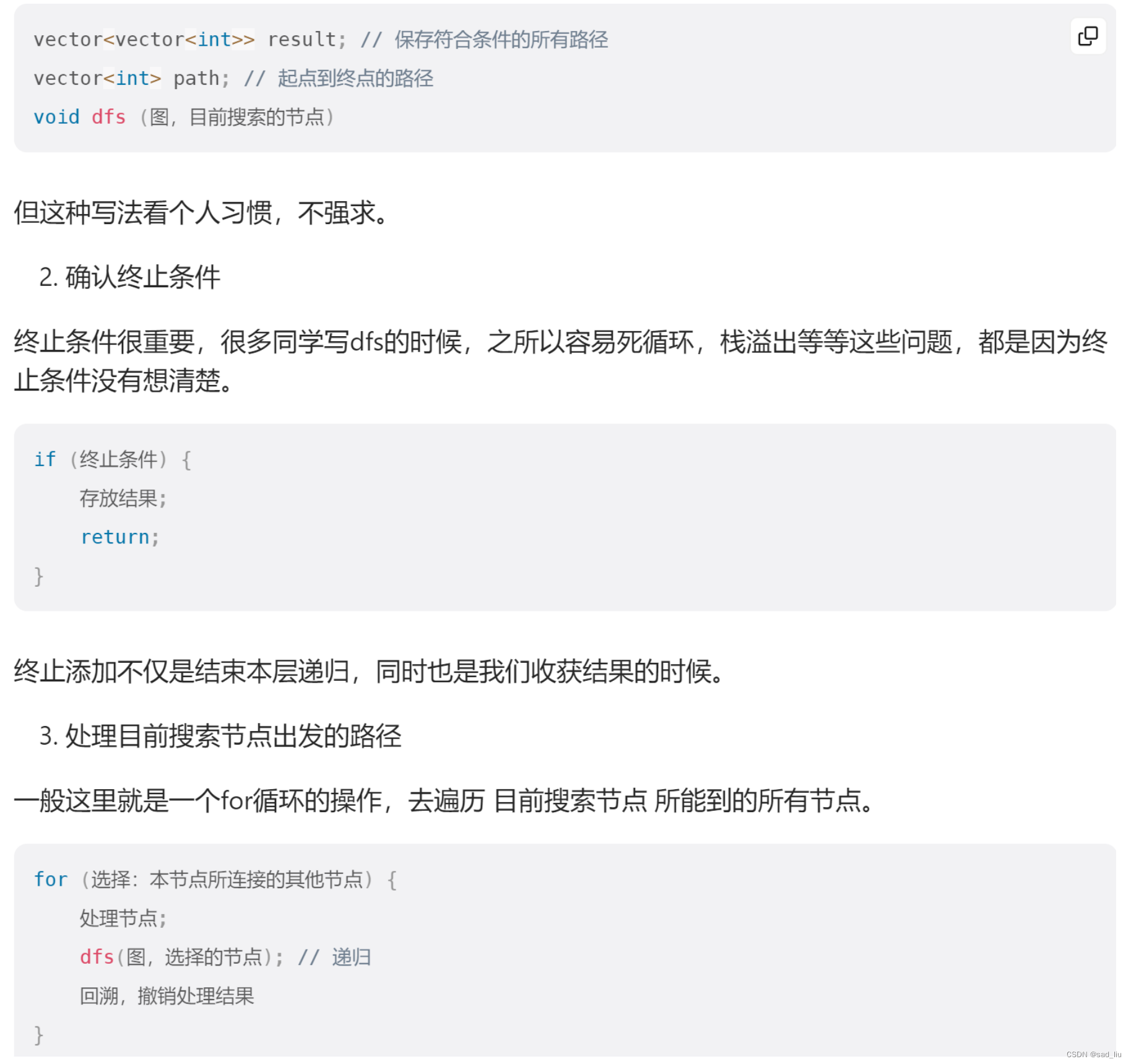
现在再来看dfs,其实和之前学过的递归模板很像,这里直接粘图了:
牛客周赛43
B.小红的完全平方数
#include <bits/stdc++.h>
using namespace std;
void solve()
{
long long x;
cin >> x;
long long ans = INT_MAX;
//枚举其完全平方数
for(long long i = 1; i < 1000000; i++)
{
long long j = i*i;
//奇偶性相同
if(j%2==x%2) ans = min(ans, abs(j-x)/2);
}
cout << ans;
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
//cin >> t;
while(t--) solve();
return 0;
}
介绍几个关于数字的特性:奇数的平方还是奇数,偶数的平方还是偶数,这里的x范围达到了10的12次方,所以这里都需要开long long,由于这里的操作数只有加2和减2,所以在每轮循环的时候只需要对j和x奇偶性的值进行操作即可,使用abs(j-x)求绝对值是对于假或减操作,每轮记录下最小的ans操作次数。对于牛客的练习赛吧,感觉还是该暴力的题就老老实实暴力,没有必要去追求极致的方法。
C.字符串变化
#include <bits/stdc++.h>
using namespace std;
//int pre[100000];
//int re[100000];
void solve()
{
string s;
cin >> s;
int n = s.size();
int pre[n], re[n];
memset(pre, 0, n);
memset(pre, 0, n);
if(s[0] >= 'a' && s[0] <= 'z') pre[0] = 1;
if(s[n-1] >= 'A' && s[n-1] <= 'Z') re[n-1] = 1;
for(int i = 1; i < n; i++)
{
if(s[i] >= 'a' && s[i] <= 'z') pre[i] = pre[i-1]+1;
else pre[i] = pre[i-1];
}
for(int j = n-2; j >= 0; j--)
{
if(s[j] >= 'A' && s[j] <= 'Z') re[j] = re[j+1]+1;
else re[j] = re[j+1];
}
int res = INT_MAX;
for(int k = 0; k < n-1; k++) res = min(res, pre[k]+re[k+1]);
cout << res;
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
//cin >> t;
while(t--) solve();
return 0;
}
我承认了!我确实菜啊!前缀和后缀和是我没想到的。。。前几天刷的前缀和感觉算是白写了。。。前缀和还是做的少了点,没想到它的运用场景,唉,对知识点的串联感还是小了点。这里的pre和re分别表示前缀和数组与后缀和数组,pre[i]用来计数该字符串的子串[0,i]修改成大写的次数。初始化完成之后就是求出到下标i时的最少操作次数,这里还是遍历一遍字符串,将操作数与pre[k]+re[k+1]进行取最小值,这里呢就需要自己举例子来进行通用性归纳,还有,题中明确给出不能全是小写或者大写,所以k遍历的区间在[0,n-2]。在求解过程中遇到了数组初始化的问题,int pre[n]我写在main函数之内作为局部变量它不一定初始化为0的,只有将这句话写在全局中所有元素才是初始化为0的。当数组定义在局部变量中时可以用memset(a, 0, n);来进行初始化,a表示数组,0表示初始化的值,n表示数组a的大小。
D.子数组排列判断
#include <bits/stdc++.h>
using namespace std;
int ha[100000];//num[i] 到个数的映射
void solve()
{
int n, k;
cin >> n >> k;
int num[n];
for(int i = 0; i < n; i++) cin >> num[i];
//count表示区间不重复的数字个数,ans表示答案
int count = 0, ans = 0;
//初始化[0,k]段
for(int i = 0; i < k; i++)
{
ha[num[i]]++;
if(ha[num[i]] == 1) count++;
if(ha[num[i]] > 2) count--;
}
if(count == k) ans++;
//双指针应用
for(int i = 1, j = k; j < n; i++, j++)
{
if(num[i] <= k)
{
ha[num[i-1]]--;
if(ha[num[i-1]] == 0) count--;
}
if(num[j] <= k)
{
ha[num[j]]++;
if(ha[num[j]] == 1) count++;
}
if(count == k) ans++;
}
cout << ans;
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
//cin >> t;
while(t--) solve();
return 0;
}
怎么说呢,这一题官方给的题解感觉就是一个暴力的模拟,但也用到了双指针,这个知识点也确实忘得差不多了,我双指针竟然想的是双层循环,我这记忆啊,双指针都不会用了,前面的知识也是忘得差不多了。。。牛客编译器不能起名hash数组,这里就用的ha,我也是无语了。。。这里的ha表示的是num[i]到它出现的个数的映射,首先初始化[0,k)段的哈希数组首先将这个数的个数累加一,如果当前次数为1,表明它是第一次出现,那么count++,这里的count用来表示这个区间出现的不重复的数字个数退出循环后如果count==k表明这个区间1-k都出现了一次,所以算一次排列的数量。接下来就是双指针的应用如果首先将刚踢出去的值的hash值减一,如果哈希值变为0了,让count减一;再就是对刚加进来的值hash值加一,再检查当前这个hash值是不是1,是1表明刚加进来的值是第一次出现,让count++,在循环末尾判断count是否和k相等,相等表明这个长度为k的子串是一个排列,ans++。
总结:基础还是很重要的,其实这一次的周赛怎么来说都得做完D,首先是浮躁的心态需要得到稳定,再就是对题目的感知还是不是很敏感,B的暴力完全可以自己推出来,懒惰导致放弃的B。C是前缀和后缀和问题,这两天做过这种题型的题,结果在这一题中没有分析出来。D是双指针的模拟,加上哈希表,都是学过的方法和数据结构没有串联起来,这一点也很不应该,总的来说菜是原罪!这一次的周赛题干很简短,相对于以前都没有题目背景的涉及,就是单纯的题干,读题来说容易了很多,但是欠缺在于方法的使用上和对暴力方法的胆怯。这次只做出来了A,积分也是越掉越低,从641到498
力扣周赛398
3152.特殊数组II
class Solution {
public:
vector<bool> isArraySpecial(vector<int>& nums, vector<vector<int>>& queries) {
vector<int> tmp(nums.size());
tmp[0] = 1;
for(int i = 1; i < nums.size(); i++)
{
if(nums[i]%2 != nums[i-1]%2) tmp[i] = tmp[i-1];
else tmp[i] = tmp[i-1]+1;
}
vector<bool> res;
for(auto q : queries)
{
if(tmp[q[0]] == tmp[q[1]]) res.push_back(true);
else res.push_back(false);
}
return res;
}
};
这一题我的方法大致和前缀和的思想一致,但又有一点创新的感觉,我这个tmp数组有那种区间染色的意思,就比如我将一种符合特殊数组的子数组染成一种颜色(这里是将tmp[i]的值赋值成相同的值),这是对其初始化的操作,再就是对每一次询问,如果tmp[from] != tmp[to]那么他们不是属于同一个染色区间的数组,那么这一次访问的值就为false,如果相等那么他们就是同一个染色区间的数组,值也就为true
1456.定长子串中元音的最大数目
class Solution {
public:
int istrue(char c)
{
return c == 'a' || c == 'e' || c == 'i' || c == 'o' || c == 'u';
}
int maxVowels(string s, int k) {
int cnt = 0, ans = 0;
for(int i = 0; i < s.size(); i++)
{
cnt += istrue(s[i]);
//当大于窗口范围的时候需要挪出元素了
if(i >= k) cnt -= istrue(s[i-k]);
ans = max(ans, cnt);
}
return ans;
}
};
模板题啊!这个滑动窗口的模板一定要记下来啊!当然,前提是这是一道定长的滑动窗口,这里都没有定义两个指针,妙就妙在if那一条语句,它模拟的是先加一个元素,然后再剔除最前面的元素,举个例子,当遍历到下标k的时候,我们先将下标k的值计入cnt中,然后剔除下标[k-k]也就是下标为0的那个cnt值,这样就达到了动态更新的效果了。
2269.找到一个数字的k美丽值
class Solution {
public:
int divisorSubstrings(int num, int k) {
string nums = to_string(num);
int ans = 0;
for(int i = 0; i+k-1 < nums.size(); i++)
{
int tmp = stoi(nums.substr(i, k));
if(tmp > 0 && num%tmp == 0) ans++;
}
return ans;
}
};
好吧模板归模板,有时还是不能生搬硬套的,这里利用了string中的substr做到了截取字符串的操作,也就达到了滑动窗口的效果,所以这里只需要枚举滑动窗口的左边界,这里需要注意的是右边界,首先获取右边界的下标为i+k-1,所以只需要i+k-1<k即可确定右边界的范围,然后就是获取每一个窗口的字符串同时转化成数字,stoi就是用来将字符串转化为数字的,它也能去除字符串的前导0,但是这个转化有个前提:这个字符串不能过于的长,可能会导致溢出异常,否则还是得逐个字符的进行转化
牛客—交换数字
#include <bits/stdc++.h>
using namespace std;
long long mod = 998244353;
void solve()
{
int n;
string a, b;
cin >> n >> a >> b;
for(int i = 0; i < n; i++)
{
if(a[i] < b[i]) swap(a[i], b[i]);
}
//字符串转数字操作,过程中需要不断取模
long long proa = 0, prob = 0;
for(int i = 0; i < n; i++)
{
proa = (proa*10+(a[i]-'0'))%mod;
prob = (prob*10+(b[i]-'0'))%mod;
}
cout << (proa*prob)%mod;
}
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int t = 1;
//cin >> t;
while(t--) solve();
return 0;
}
首先题干中的意思是可以交换若干次,想要求出若干次操作后a*b的值的最小值,那么abs(a-b)一定要最大,这里题解的意思是让a尽可能大,b尽可能小;相反若要求a * b的最大值,那么abs(a-b)一定要最小,也就是a和b尽可能相等,这就是用到的高中的不等式的一个结论。关键是要记下来字符串转换成数字的操作,同时也去掉了前导0
1984.学生分数的最小差值
class Solution {
public:
int minimumDifference(vector<int>& nums, int k) {
sort(nums.begin(), nums.end(), greater<int>());
int res = INT_MAX;
for(int i = 0; i+k-1 < nums.size(); i++)
{
res = min(res, nums[i]-nums[i+k-1]);
}
return res;
}
};
这一题没有明确的字眼告诉你这一题要用滑动窗口来写,但是需要将问题转化成用滑动窗口来写。首先是将nums数组排序,我这里是将其变成了降序的形式即[9,7,4,1],然后利用窗口大小k来遍历整个数组,左边界为最大值,右边界为最小值,每一次求得的差值与前面记录下来的差值取min,最终求得res就为答案。这里我当时在想难道不会出现少判断的情况吗?题中给出的示例2有6种情况,而这里遍历完数组只出现了3种情况。答案是不会产生误差的,排序好之后假如我记录了[7,4]后的res为3,我再比较[7,1]是不可能比[7,4]的情况要小的,因为数组是有序的!我在4的右边再取数一定会比4小,这样差值一定会比取4的时候大。
643.子数组最大平均数I
class Solution {
public:
double findMaxAverage(vector<int>& nums, int k) {
int sum = 0;
double res = -10009;
for(int i = 0; i < nums.size(); i++)
{
sum += nums[i];
if(i >= k-1)
{
res = max(res, 1.0*sum/k);
sum -= nums[i-k+1];
}
}
return res;
}
};
仔细观察和1256还是有一点差别的,模板虽然是模板,但是有些边界上和逻辑上的问题还是有细微的差异的,这里一定要是先求出平均值记录到res后再sum-=nums[i-k+1]。再对比一下2269,最大的不同就是在循环退出的条件上,从特点上来看我将它们分为两种滑动窗口:1、枚举左边界型(2269,1984) 2、枚举右边界型(1456,643),这一题是枚举右边界型,那么自然而然i的右边界就应该是小于nums.size(),当时这里就是写成了i+k-1<nums.size()导致结果不对。















 560
560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









