







文章目录
刷题记录5.22-5.27
17.电话号码的字母组合
class Solution {
public:
vector<string> letterCombinations(string digits) {
vector<string> lettermap = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
int n = digits.size();
if(n == 0) return {};
vector<string> res;
string path(n, 0);
function<void(int)> dfs = [&] (int i) -> void{
if(i == n)
{
res.push_back(path);
return;
}
for(char c : lettermap[digits[i]-'0'])
{
path[i] = c;
dfs(i+1);
}
};
dfs(0);
return res;
}
};
这一题属于是二刷了,最开始看灵神的讲解看不懂,就开始跟着卡尔的步伐了,现在回过头来看灵神的解法确实还是比卡尔的简洁很多,主要是省略的步骤我也能分析出来了,比如lambda表达式之类的,回过头来看确实容易理解了许多。这里的dfs其实就是充当了卡尔所讲的backtracking,这里的i表示的是i层递归,递归出口就是到达digits.size()的时候递归退出。由于这里的每个path都是等长的,所以它初始化path的时候固定为n,添加路径的时候也是直接path[i] = c覆盖掉,其实也就等价于之前所写的path.push_back©和在dfs(i+1)下一行的path.pop_back();
在devc++中使用c11特性:
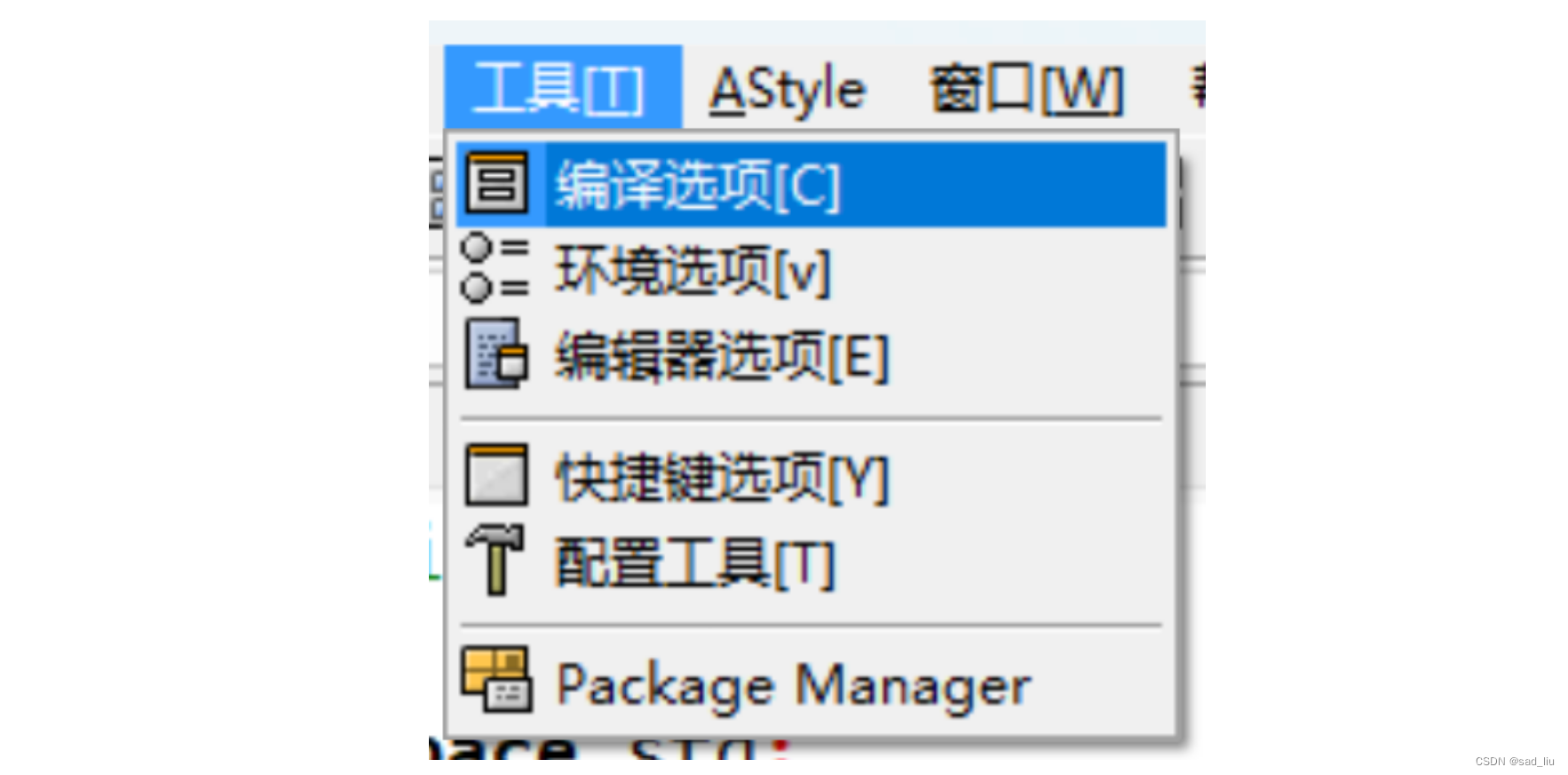
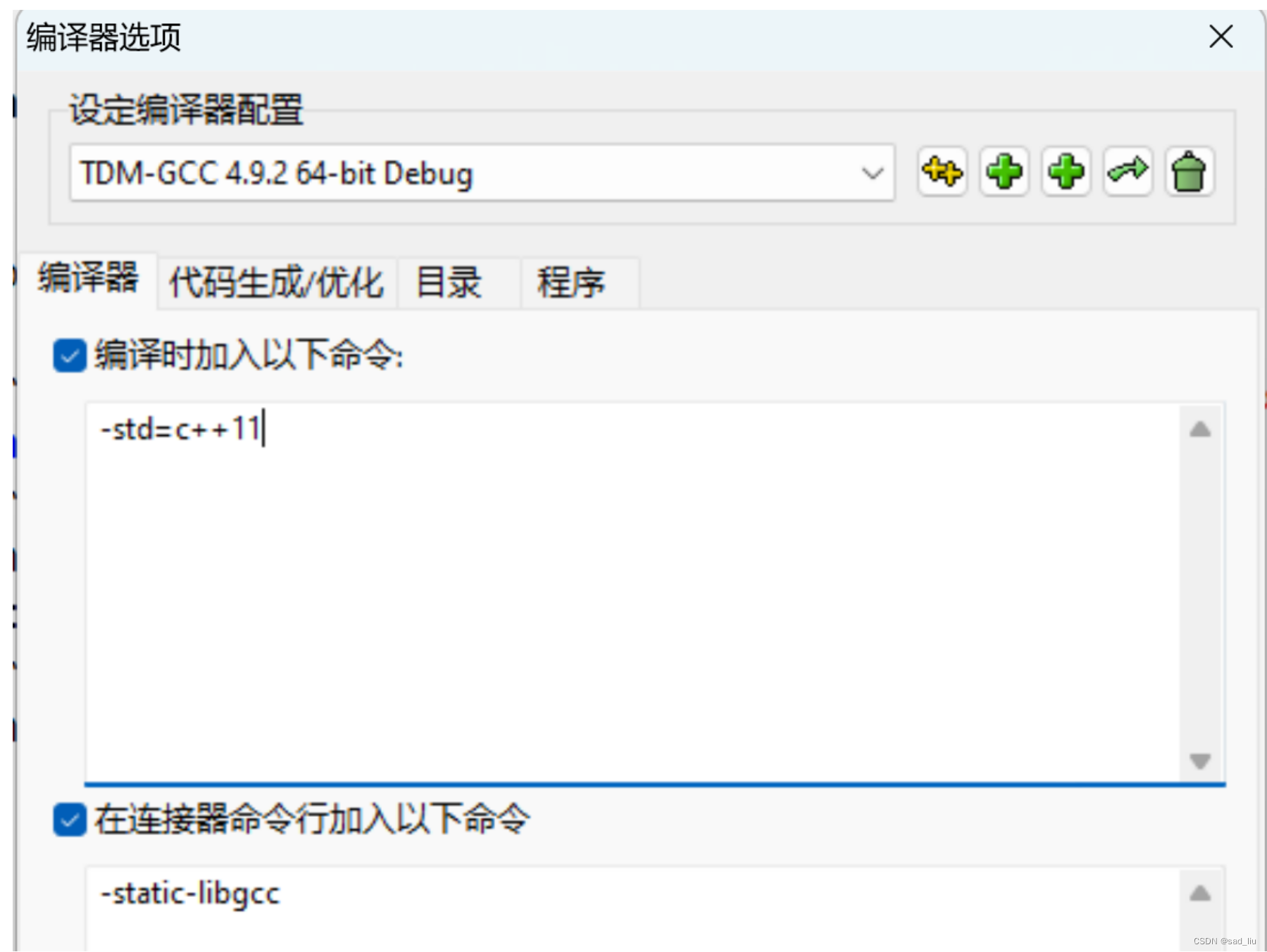
手动输入-std=c++11并按下确定就配置完成了,这样就能使用auto和lambda表达式了
78.子集
输入的视角(选与不选):
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<int> path;
vector<vector<int>> res;
int n = nums.size();
function<void(int)> dfs = [&] (int i) {
if(i == n)
{
res.push_back(path);
return;
}
//不选
dfs(i+1);
//选
path.push_back(nums[i]);
dfs(i+1);
path.pop_back();
};
dfs(0);
return res;
}
};
题中明确给出你可以按任意顺序返回解集,所以这种以输入为视角的方法是可行的,当你以这种方法画出的字典树会发现所有路径都是在树的叶子节点上。
答案的视角:
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<int> path;
vector<vector<int>> res;
int n = nums.size();
function<void(int)> dfs = [&] (int i) {
res.push_back(path);
if(i == n) return;
for(int j = i; j < n; j++)
{
path.push_back(nums[j]);
dfs(j+1);
path.pop_back();//回溯---恢复现场
}
};
dfs(0);
return res;
}
};
这个题解如果按照代码来画出字典树的话可以观察到它是在每个节点都会将path录入res中,这就把选与不选区分开了
131.分割回文串
答案视角:
class Solution {
public:
bool ispartition(string s, int l, int r)
{
while(l < r)
{
if(s[l++] != s[r--]) return false;
}
return true;
}
vector<vector<string>> partition(string s) {
vector<vector<string>> res;
vector<string> path;
int n = s.size();
function<void(int)> dfs = [&] (int i) {
if(i == n)
{
res.push_back(path);
return;
}
for(int j = i; j < n; j++)
{
if(ispartition(s, i, j))
{
path.push_back(s.substr(i, j-i+1));
dfs(j+1);
path.pop_back();
}
}
};
dfs(0);
return res;
}
};
个人觉得输入视角不是很好理解,什么选或不选逗号。。。判断是否回文就用相向双指针
77.组合
class Solution {
public:
vector<vector<int>> combine(int n, int k) {
vector<vector<int>> res;
vector<int> path;
function<void(int, int)> dfs = [&] (int i, int start) {
if(i == k)
{
res.push_back(path);
return;
}
for(int j = start; j <= n; j++)
{
path.push_back(j);
dfs(i+1, j+1);
path.pop_back();
}
};
dfs(0, 1);
return res;
}
};
emmm个人觉得灵神的后续遍历不太好理解,后续遍历仅仅只对代码来说比较好写,而我觉得从前往后遍历可能更符合常理思维,我这里的dfs包含了两个参数,层数i和当前访问的数start,其实这个方法没有做到完全的剪枝操作(仅仅只剪了层数不符合的情况),更完美的写法在for循环应该写成for(int j = start; k-path.size() <= n-j+1; j++)
更何况目前是准备蓝桥杯的阶段,更应该要与答案一致,题中给出可以按任意顺序返回答案这也仅是对方法上采取的策略更多了。
22.括号生成
class Solution {
public:
bool check(string path)
{
stack<char> s;
for(char a : path)
{
if(s.empty()) s.push(a);
else if(s.top() == '(' && a == ')') s.pop();
else s.push(a);
}
return s.empty();
}
vector<string> generateParenthesis(int n) {
vector<string> res;
string path;
char c[2] = {'(', ')'};
function<void(int)> dfs = [&] (int i) {
if(i == 2*n)
{
if(check(path)) res.push_back(path);
return;
}
for(char ch : c)
{
path.push_back(ch);
dfs(i+1);
path.pop_back();
}
};
dfs(0);
return res;
}
};
果然尝试还是会有结果的!最开始的2 * n写的是n也没写check函数,查看结果的时候发现path长度减半了,我就尝试着将n改成2 * n然后长度对了,但是n=3的样例多出了很多输出,我就在想:我是不是只要在每次在录入res之前判断一下path是否符合有效括号括号就行了?诶这样就联想到了之前写的括号匹配问题,也就是简单的栈的应用,然后我就试着用check函数来实现一下,样例过了之后我就试着提交吧,时间性能超过5%哈哈哈,好在还是n比较小吧没有超时!本来还想着肯定超时的,没想到给了我一个惊喜!
优化写法:
class Solution {
public:
vector<string> generateParenthesis(int n) {
vector<string> res;
int m = 2*n;
string path(m, 0);//初始化长度为m的空字符串
function<void(int, int)> dfs = [&] (int i, int open) {
if(i == m)
{
res.push_back(path);
return;
}
if(open < n)
{
path[i] = '(';
dfs(i+1, open+1);
}
if(i-open < open)
{
path[i] = ')';
dfs(i+1, open);
}
};
dfs(0, 0);
return res;
}
};
这个写法就是大致模拟的填充括号的过程,由于path的长度是确定的,所以这里直接将path的长度给初始化了string path(m, 0);的意思是初始化长度为m的空字符串,每次递归的时候只需要将其覆盖掉就行了。i表示递归的深度,open表示左括号的个数,i-open表示右括号的个数,所以优先填左括号,这样填右括号时才能确保生成的是有效的括号。
198.打家劫舍—从递归到记忆化搜索再到递推动态规划
递归:
class Solution {
public:
int rob(vector<int>& nums) {
int n = nums.size();
//dfs(i)表示nums[0]到nums[i]能偷的最大价值
function<int(int)> dfs = [&] (int i) -> int{
if(i < 0) return 0;//表明已经没有房子可偷了
return max(dfs(i-1), dfs(i-2)+nums[i]);
};
return dfs(n-1);
}
};
当n的长度达到20左右的时候就会时间超限,通过画出字典树可以知道期间有许多节点是重复访问的
添加记忆化剪枝:
class Solution {
public:
int rob(vector<int>& nums) {
int n = nums.size();
vector<int> visited(n, -1);//没访问过的房间值为-1,已访问过的房间值为0-i个房间可偷的最大值
//dfs(i)表示nums[0]到nums[i]能偷的最大价值
function<int(int)> dfs = [&] (int i) -> int{
if(i < 0) return 0;//表明已经没有房子可偷了
if(visited[i] != -1) return visited[i];//如果访问过就直接返回
return visited[i] = max(dfs(i-1), dfs(i-2)+nums[i]);//记录
};
return dfs(n-1);
}
};
转换成递推公式后直接使用动态规划:
class Solution {
public:
int rob(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n+2);
for(int i = 0; i < n; i++)
{
dp[i+2] = max(dp[i+1], dp[i]+nums[i]);
}
return dp.back();
}
};
如何从递归到递推的呢?就是max(dfs(i-1), dfs(i-2)+nums[i]);中的dfs函数用店铺数组来代替,递归用for循环来代替,然后对于数组dp[i-1]和dp[i-2]可能出现数组越界的问题,并且不易初始化。所以这里直接将dp数组都加上了2,那么递推公式从dp[i]=max(dp[i-1],dp[i-2]+nums[i])变成了dp[i+2] = max(dp[i+1], dp[i]+nums[i]),注意哈,这里nums数组下标是不能够改变的哈。就这样我们既不用对初始化而烦恼,也让代码变得简洁了。如果不这样改变的话dp[0]和dp[1]需要单独赋值并讨论循环开始的下标也要从2开始。
空间优化到O1
class Solution {
public:
int rob(vector<int>& nums) {
int f0 = 0, f1 = 0;
for(int x : nums)
{
int f2 = max(f1, f0+x);
f0 = f1;
f1 = f2;
}
return f1;
}
};
这个写法仅供观看吧,其实不是很利于理解,就是很高大上而已啦。。。f0,f1,f2分别充当dp[i],dp[i+1]和dp[i+2],由于dp[i+2]只会由前两个dp值所确定,所以就可以这样巧妙的来表达了,就可以想象出一个数组,f0和f1跟着游标一起向右移动,这个写法也很想斐波那契数列数列那一题的空间优化版本,就是递推公式不同而已,所以这个题就可以简化成斐波那契数列那一题了(就是改变了递推公式,这一题需要自己推出来,而斐波那契数列那一题已经告诉你了)
背包搜索模板
vector<vector<int>> visited(n, vector<int>(capacity+1, -1));
function<int(int, int)> dfs = [&] (int i, int c) {
//这里退出条件要因题目条件而变 对应dp数组的初始化
if(i < 0) return 0;
//记忆化搜索 剪枝操作
if(visited[i][c] != -1) return visited[i][c];
//weigith[i]和val[i]也要搞清楚,要依据题目中的信息而改变,max也是
if(c < nums[i]) return dfs(i-1, c);
return visited[i][c] = max(dfs(i-1, c), dfs(i-1, c-weight[i])+val[i])
};
return dfs(n-1, capacity);
494.目标和
记忆化搜索:
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
//求出sum+target,为奇数或者target+sum<0的话直接返回0不符合条件
target += accumulate(nums.begin(), nums.end(), 0);
if(target < 0 || target%2 == 1) return 0;
target /= 2;
int n = nums.size();
//这里要注意定义visited数组的大小visited[n][target+1],因为递归开始从dfs(n-1,target)开始的
vector<vector<int>> visited(n, vector<int>(target+1, -1));
function<int(int, int)> dfs = [&] (int i, int c) -> int{
//递归终点 从后往前下标为0时停止递归
if(i < 0) return c == 0;
//如果已经访问过 直接返回visited[i][c] 剪枝 类似于打家劫舍
if(visited[i][c] != -1) return visited[i][c];
//如果当前容量小于物品容量只能不选
if(c < nums[i]) return dfs(i-1, c);
//最后一种情况 选与不选 dfs(i, c) = max(dfs(i-1, c), dfs(i-1, c-weigh[i])+val[i])
//这里要求方案数,直接将max去掉,dfs之间变成加法即可实现
return visited[i][c] = dfs(i-1, c)+dfs(i-1, c-nums[i]);
};
return dfs(n-1, target);
}
};
1:1翻译成递推:
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
//求出sum+target,为奇数或者target+sum<0的话直接返回0不符合条件
target += accumulate(nums.begin(), nums.end(), 0);
if(target < 0 || target%2 == 1) return 0;
target /= 2;
int n = nums.size();
vector<vector<int>> dp(n+1, vector<int>(target+1, 0));
dp[0][0] = 1;//if(i < 0) return c == 0;
for(int i = 0; i < n; i++)
{
for(int c = 0; c <= target; c++)
{
if(c < nums[i]) dp[i+1][c] = dp[i][c];
else dp[i+1][c] = dp[i][c]+dp[i][c-nums[i]];//这里最开始少个else 找了很久。。
}
}
return dp[n][target];
}
};
这里避免dp[i][c] = dp[i-1][c]+dp[i-1][c-nums[i]];下标出现负数,所以就将i坐标都加了1,所以在定义数组长度的时候是定义了n+1行,但是哈,在第一层for循环是不需要进行改变的,当时我就想着循环条件可能也需要改变改成了i<=n,结果是错的会导致越界,这里跟visited数组是同一个道理
空间优化O(1):
class Solution {
public:
int findTargetSumWays(vector<int>& nums, int target) {
//求出sum+target,为奇数或者target+sum<0的话直接返回0不符合条件
target += accumulate(nums.begin(), nums.end(), 0);
if(target < 0 || target%2 == 1) return 0;
target /= 2;
int n = nums.size();
vector<int> dp(target+1);
dp[0] = 1;
for(int val : nums)
{
for(int c = target; c >= val; c--)
{
dp[c] = dp[c]+dp[c-val];
}
}
return dp[target];
}
};
回顾一下,01背包每个物品只能选一次,递推式具象成二维数组中可以看出当前的dp值取决于左上角的值,所以当优化空间为O(1)的时候内层循环只能从后往前遍历。先for物品后for容量
322.零钱兑换
记忆化搜索:
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
int n = coins.size();
vector<vector<int>> visited(n, vector<int>(amount+1, -1));
//前i个物品兑换容量c的最小价值(硬币个数)
function<int(int, int)> dfs = [&] (int i, int c) {
//修改这一行可以从dfs的定义下手 dfs定义通常问什么定义成什么
//能兑换amount返回0,不能兑换amount返回INT_MAX-1
if(i < 0) return c == 0 ? 0 : INT_MAX-1;//INT_MAX-1防止下面的dfs()+1溢出
if(visited[i][c] != -1) return visited[i][c];
//与01背包不同的地方只有在第二个dfs(i,c-nums[i])上,其他变化都在于题目的基础上
//表示我当前选了第i个物品,我还是能从前i个物品中选
if(c < coins[i]) return dfs(i-1, c);
return visited[i][c] = min(dfs(i-1, c), dfs(i, c-coins[i]) + 1);
};
int ans = dfs(n-1, amount);
return ans < INT_MAX-1 ? ans : -1;
}
};
这里的val[i]替换成了1,也就是价值替换成了1,无论选什么价值的硬币其个数都是1,可以从题目中定义dfs函数,要求最少硬币个数,那么我的递归结果就是个数,影响递归结果的也就是val[i],所以选的时候个数+1,不选的时候个数不变。要求最少个数就把max改为min
转化成递推:
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
int n = coins.size();
vector<vector<int>> dp(n+1, vector<int>(amount+1, INT_MAX-1));
dp[0][0] = 0;
for(int i = 0; i < n; i++)
{
for(int c = 0; c <= amount; c++)
{
if(c < coins[i]) dp[i+1][c] = dp[i][c];
else dp[i+1][c] = min(dp[i][c], dp[i+1][c-coins[i]]+1);
}
}
int ans = dp[n][amount];
return ans < INT_MAX-1 ? ans : -1;
}
};
空间优化成一个数组:
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
int n = coins.size();
//vector<vector<int>> dp(n+1, vector<int>(amount+1, INT_MAX-1));
//dp[0][0] = 0;
vector<int> dp(amount+1, INT_MAX-1);
dp[0] = 0;
for(int i = 0; i < n; i++)
{
for(int c = 0; c <= amount; c++)
{
if(c < coins[i]) dp[c] = dp[c];
else dp[c] = min(dp[c], dp[c-coins[i]]+1);
}
}
int ans = dp[amount];
return ans < INT_MAX-1 ? ans : -1;
}
};
牛客小白月赛—数字合并
#include <bits/stdc++.h>
using namespace std;
long long prefix[200020];
long long a[200020];
void solve()
{
int n;
cin >> n;
for(int i = 1; i <= n; i++)
{
cin >> a[i];
prefix[i] = prefix[i-1]+a[i];
}
long long maxans = 0;
for(int i = 1; i <= n; i++)
{
long long max1 = prefix[i-1];
long long max2 = prefix[n]-prefix[i];
maxans = max(maxans, max(max1, max2)-a[i]);
}
cout << maxans;
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
//cin >> t;
while(t--) solve();
return 0;
}
原来这一题用到的是前缀和!前缀和初始化prefix数组,然后枚举一遍数组就行了,哎呦比赛的时候没有想到,WA了两下还是急躁了一点。其他需要注意的就是要开long long防止int溢出,还有就是数组如果想让它初始化为0的话一定要定义在全局中,并且要注意题中允许开的最大范围,这一题前面一直开的1e5,结果n的范围在2e5我真服了我这审题。
再就是前缀和的初始化,这里还是不熟练,leetcode刷的都是和sum有关的,并没用到前缀数组。
前缀和初始化模板
int prefix[n+10];//n取决于题干中的范围 或vector<int> prefix(n+10);
int nums[n+10];
//下标一定从1开始 这要好遍历
for(int i = 1; i <= n; i++)
{
cin >> nums[i];
prefix[i] = prefix[i-1]+nums[i];
}
//求sum[i,j]i和j表示第i个数和第j个数,这里求的是i和j的左闭右闭区间 容易出错的地方还是在下标
sum = prefix[j]-prefix[i-1];
线性DP
1143.最长公共子序列
记忆化搜索:
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int s = text1.size(), t = text2.size();
//test1前i个字符与test2前t个字符最长公共子序列
vector<vector<int>> visited(s, vector<int>(t, -1));
function<int(int, int)> dfs = [&] (int i, int c) -> int {
//递归出口
if(i < 0 || c < 0) return 0;
//记忆化判断
if(visited[i][c] != -1) return visited[i][c];
//递推公式判断
if(text1[i] == text2[c]) return visited[i][c] = dfs(i-1, c-1)+1;
return visited[i][c] = max(dfs(i-1, c), dfs(i, c-1));
// return visited[i][c] = (text1[i] == text2[c] ? dfs(i-1, c-1)+1 : max(dfs(i-1, c), dfs(i, c-1)));
};
return dfs(s-1,t-1);
}
};
转化成递推dp
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int s = text1.size(), t = text2.size();
//test1前i个字符与test2前t个字符最长公共子序列
vector<vector<int>> dp(s+1, vector<int>(t+1));
for(int i = 0; i < s; i++)
{
for(int j = 0; j < t; j++)
{
if(text1[i] == text2[j]) dp[i+1][j+1] = dp[i][j]+1;
else dp[i+1][j+1] = max(dp[i][j+1], dp[i+1][j]);
}
}
return dp[s][t];
}
};
这一题吧,主要是想出递归公式有点费劲,想出了递推公式就顺着模板写就完事了。优化成一个数组的写法看不懂就不写了
72.编辑距离
记忆化搜索:
class Solution {
public:
int minDistance(string word1, string word2) {
int n1 = word1.size(), n2 = word2.size();
vector<vector<int>> visited(n1, vector<int>(n2, -1));
//dfs定义和dp定义优先!---将word1前i个字母转换成word2前c个字母单独最少操作数
function<int(int, int)> dfs = [&] (int i, int c) -> int {
//if(i < 0 || c < 0) return 1;
//注意这里的退出条件 假设word1为空 word2长为n
//那么需要操作n次才能转换成功由于下标从0开始 所以需要+1
if(i < 0) return c+1;
if(c < 0) return i+1;
if(visited[i][c] != -1) return visited[i][c];
if(word1[i] == word2[c]) return visited[i][c] = dfs(i-1, c-1);
return visited[i][c] = min(dfs(i-1,c), min(dfs(i,c-1), dfs(i-1,c-1)))+1;
};
return dfs(n1-1, n2-1);
}
};
递推:
class Solution {
public:
int minDistance(string word1, string word2) {
int n1 = word1.size(), n2 = word2.size();
vector<vector<int>> dp(n1+1, vector<int>(n2+1));
//扩充了数组就要初始化到位 但是dp递推里面的逻辑还是不能改变<n1和<n2
for(int i = 0; i <= n1; i++) dp[i][0] = i;
for(int j = 0; j <= n2; j++) dp[0][j] = j;
for(int i = 0; i < n1; i++)
{
for(int j = 0; j < n2; j++)
{
if(word1[i] == word2[j]) dp[i+1][j+1] = dp[i][j];
else dp[i+1][j+1] = min(min(dp[i][j+1],dp[i+1][j]), dp[i][j])+1;
}
}
return dp[n1][n2];
}
};
经典题目还是要多多推敲啊,难点在于递推式的理解,但是呢如果说要掌握递推式根源就回到了递推dfs的定义或者是dp的定义了。
总结一下这几天的动态规划回顾吧,结合之前的卡尔和灵神的讲解,其实发现各有好处:最开始0基础的时候确实不适合听灵神讲题,省略的东西确实是多,过于追求简洁了,卡尔更适合0基础去入门,它的动态规划5步曲确实有用。个人认为最有用的就是第一句:熟悉dp数组的定义,你的dp数组定义明白了才能更好地求出递推式,而对于递推式的讲解卡尔更倾向于经验,更多的是需要一步一步地尝试,而灵神在这一步我觉得做的更好,他能从熟悉的递归到递推,我个人觉得这样更适于理解。
从递归到递推,就是将dfs函数变成dp数组、递归变成循环,一个参数一个循环,两个参数两个循环。dp数组通常是要有+1操作,是为了不让数组越界,这样自然而然我们就需要定义的数组要比size大1,当然这要根据递推式来决定,灵神在递推的讲法是:选与不选思想,这个呢也只能和题型结合起来,01背包主要是先要记住结论。然后就是当递归转化成递推的时候哪个语句对应初始化,哪个语句对应dp的动态变化需要捋清楚。然后呢容易出现的几处错误:1、哪个坐标+1了就一定全都要+1,像72.编辑距离j坐标忘记+1导致数组越界,这地方太容易出错了。。。2、递归出口和dp数组初始化之间的转化不太好写,这主要是考验自己吧,也是需要因题而异的3、区分记忆化搜索和之前的排列型、组合型回溯。虽然都是用到的dfs函数,但是还是有细微区别的。首先是返回值,记忆化搜索的题目前遇到的都是有返回值的,因为它是自底向上的,需要子问题的返回值返回给根节点找答案,所以记忆化搜索的起始点通常是n-1开始,要理清这种层次关系。再就是回溯题:这种就类似于求出它的路径这种问题,需要不断地记录到数组里,并不是求值。而且从题目中问题也能看出,比如求什么最优解最小操作数这种也不可能是回溯问题。。。我的目前的理解也就到这啦!相比以前的一道动规写一天好多啦,只不过还是得先看题解才能写出,理解能力还是比以前强多了
300.最长递增子序列
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n = nums.size();
vector<int> dp(n, 1);
for(int i = 0; i < n; i++)
{
for(int j = i-1; j >= 0; j--)
{
if(nums[i] > nums[j])
{
dp[i] = max(dp[i], dp[j]+1);
}
}
}
return ranges::max(dp);
}
};
这一题与前面几题还是有一点区别的,这里用到递归方法是选哪个而不是选与不选,由于是限定的是递增的,所以向前递归的时候并不一定是前一个数或者前两个数,这样的话用选与不选是无法确定下一次递归的参数i的,所以这里用的是选哪个,就是以i-1为尾向前去找哪个是符合自增的,然后再递归,所以在递归中就用到了for循环。这么下来可算是明白了选与不选思想和选哪个思想的区别了。
状态机DP
122.买卖股票最佳时机II
class Solution {
public:
int maxProfit(vector<int>& prices) {
int n = prices.size();
vector<vector<int>> dp(n+1, vector<int>(2));
dp[0][1] = INT_MIN;
for(int i = 0; i < n; i++)
{
dp[i+1][0] = max(dp[i][0], dp[i][1]+prices[i]);
dp[i+1][1] = max(dp[i][1], dp[i][0]-prices[i]);
}
return dp[n][0];
}
};
现在总算知道这种dp模型称为状态机dp了,dp[i+1] [0]表示前i天未持有股票的最大利润,dp[i+1] [1]表示前i天持有股票的最大利润,那么返回的dp[n] [0]表示前n天未持有股票的最大利润了,我感觉吧dp有共性的特点,为了不防止数组越界,dp数组都可以开一个比目标数组大1的一个数组,当然这也取决于递推公式如果递推公式中有-2就开大2的数组,这要适情况而定。然后就是初始化,这里我感觉可以从两个方面来看,第一个是dp的定义然后通过常识来初始化,另一个就是通过递推式来初始化,因为只有合理的初始化才能得到想要的答案。
309.买卖股票最佳时机含冷冻期
class Solution {
public:
int maxProfit(vector<int>& prices) {
int n = prices.size();
vector<vector<int>> dp(n+2, vector<int>(2));
dp[1][1] = INT_MIN;
for(int i = 0; i < n; i++)
{
dp[i+2][0] = max(dp[i+1][0], dp[i+1][1]+prices[i]);
dp[i+2][1] = max(dp[i+1][1], dp[i][0]-prices[i]);
}
return dp[n+1][0];
}
};
果然每个人的做题方法都不一样,之前看卡尔的定义了4个状态,这会看灵神的任然是定义两个状态,在递推的时候只需要注意在持股的状态时是dp[i] [0]-prices[i],这就类似于打家劫舍那一题了,它是将冷冻期等价成了不能相邻的问题,所以在买入的那一天一定是前两天的未持有状态下-prices[i],题中也说了,尽可能多的交易,也就是冷冻期结束的后一天就会买入。
516.最长回文子序列
记忆化搜索:
class Solution {
public:
int longestPalindromeSubseq(string s) {
int n = s.size();
int visited[n][n];
memset(visited, -1, sizeof(visited));
function<int(int, int)> dfs = [&] (int i, int c) -> int {
if(i > c) return 0;
if(i == c) return 1;
if(visited[i][c] != -1) return visited[i][c];
if(s[i] != s[c]) return visited[i][c] = max(dfs(i,c-1), dfs(i+1,c));
return visited[i][c] = dfs(i+1,c-1)+2;
};
return dfs(0,n-1);
}
};
力扣周赛399优质数对的总数
枚举因子
class Solution {
public:
long long numberOfPairs(vector<int>& nums1, vector<int>& nums2, int k) {
unordered_map<int, int> hash;
for(int x : nums1)
{
//首先判断能否整除k,如果不能整除表明k不是x的因子,那么一定不能整除nums[2]*k
for(int i = 1; i*i <= x; i++)
{
if(x%i) continue;
hash[i]++;
if(i*i < x) hash[x/i]++;
}
}
long long ans = 0;
for(int x : nums2)
{
ans += hash.count(x*k) ? hash[x*k] : 0;
}
return ans;
}
};
优化:
class Solution {
public:
long long numberOfPairs(vector<int>& nums1, vector<int>& nums2, int k) {
unordered_map<int, int> hash;
for(int x : nums1)
{
//首先判断能否整除k,如果不能整除表明k不是x的因子,那么一定不能整除nums[2]*k
if(x%k) continue;
x /= k;
for(int i = 1; i*i <= x; i++)
{
if(x%i) continue;
hash[i]++;
if(i*i < x) hash[x/i]++;
}
}
long long ans = 0;
for(int x : nums2)
{
ans += hash.count(x) ? hash[x] : 0;
}
return ans;
}
};
这种题像是给我掌握了一个方法,就是枚举因子并存入哈希表中,这也是相对暴力的一个做法
牛客周赛44连锁进位
#include <bits/stdc++.h>
using namespace std;
void solve()
{
int n;
cin >> n;
for(int i = 0; i < n; i++)
{
string x;
cin >> x;
long long res = 0;
int len = x.size()-1;
while(x[len] == '0') len--;
int cnt = 0, flag = 0;
for(int i = len; i > 0; i--)
{
cnt += 10-((x[i]-'0')+flag);
flag = 1;
}
cout << cnt << '\n';
}
}
int main()
{
ios_base::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
int t = 1;
//cin >> t;
while(t--) solve();
return 0;
}
比赛的时候我感觉我就是错在了去除后缀0的地方,感觉还是急躁了点,得一步一步地来,我的源码是遇到0就continue,这个逻辑很复杂,因为进位的时候也会遇到9进位成0,所以不太严谨,最好的做法就是一步一步来,以后ACM赛制和IO赛制没结束之前一定不能看榜,每次看完榜就开始浮躁起来了,然后在Dev里写代码的时候如果输入复杂的时候建议还是一步一步验证,否则如果写完了还要从头检查输入输出起始也很麻烦,以后还是写一步检查一步吧。这就是一个签到题啊!我怎么就写不出,气死我了!
200.岛屿数量
dfs:
class Solution {
public:
int numIslands(vector<vector<char>>& grid) {
vector<vector<bool>> visited(grid.size(), vector<bool>(grid[0].size(), false));
function<void(int, int)> dfs = [&] (int i, int c){
grid[i][c] = '0';
if(i+1 < grid.size() && grid[i+1][c] == '1') dfs(i+1,c);
if(c+1 < grid[0].size() && grid[i][c+1] == '1') dfs(i,c+1);
if(i-1 >= 0 && grid[i-1][c] == '1') dfs(i-1,c);
if(c-1 >= 0 && grid[i][c-1] == '1') dfs(i,c-1);
};
int ans = 0;
for(int i = 0; i < grid.size(); i++)
{
for(int c = 0; c < grid[i].size(); c++)
{
if(grid[i][c] == '1')
{
dfs(i,c);
ans++;
}
}
}
return ans;
}
};
自己写的时候错在了四个if写成了if else if的的逻辑,因为如果是else if的话每次只会遍历一个方向,回溯的时候就不会再遍历其他方向了,这两者之间的差异还是很好理解的。
bfs:
class Solution {
public:
int numIslands(vector<vector<char>>& grid) {
//上左下右
int x[4] = {1, 0, -1, 0};
int y[4] = {0, -1, 0, 1};
deque<pair<int, int>> q;
int ans = 0;
for(int i = 0; i < grid.size(); i++)
{
for(int j = 0; j < grid[i].size(); j++)
{
if(grid[i][j] == '1')
{
q.push_back({i, j});
grid[i][j] = '0';//可以不加 入队之后立马修改成已访问
while(!q.empty())
{
auto t = q.front();
int mx = t.first, my = t.second;
//grid[mx][my] = '0';
q.pop_front();
//上左下右
for(int k = 0; k < 4; k++)
{
int nextx = mx+x[k], nexty = my+y[k];
//如果越界直接跳过
if(nextx >= 0 && nextx < grid.size() &&
nexty >= 0 && nexty < grid[0].size() && grid[nextx][nexty] == '1')
{
q.push_back({nextx, nexty});
//入队后立即修改标记位
grid[nextx][nexty] = '0';
}
}
}
ans++;
}
}
}
return ans;
}
};
个人感觉还是dfs好写一点,bfs要考虑的地方要稍微多一点,对于bfs在数组边界上、队列判空、标记位的修改这些地方经常出错,着重留意!数组边界:由于这一题涉及上下左右四个方向,所以在判断的时候就要注意四个边界,对于修改标记位的错误只要确保每次在入队的时候立马就进行修改标记位,这样就不会出错,否则会导致死循环的。
这里还有个非常重要的地方,也是我知识的漏洞吧,这里的deque队列要定义成pair<int,int>类型的,这也是我当时写题时没有想到的,最开始写的思路是将数组的字符串入队,我写到后面发现这好像并不对,每次我取出队首元素的时候并不能再向上下左右的方向去搜索了,就是因为我入队的元素并不是{x,y}下标这种形式,想到了这一点,但是我想不出用什么数据结构来维护这样一个集合,看了题解发现用到的是pair,确实是很久没有用到过这个了,我记着好像也就只有unordered_map初始化需要pair来着,就没有发现哪里用到过,然后就是取出这个x和y用的是.first和.second而不是.front()和.back()
695.岛屿的最大面积
dfs写法:
class Solution {
public:
int cnt = 0;
int maxAreaOfIsland(vector<vector<int>>& grid) {
function<int(int, int)> dfs = [&](int i, int c) -> int{
if(grid[i][c] == 0) return 0;
grid[i][c] = 0;
int up=0, left=0, down=0, right=0;
if(i-1 >= 0 && grid[i-1][c] == 1) up = dfs(i-1,c);
if(c-1 >= 0 && grid[i][c-1] == 1) left = dfs(i,c-1);
if(i+1 < grid.size() && grid[i+1][c] == 1) down = dfs(i+1,c);
if(c+1 < grid[0].size() && grid[i][c+1] == 1) right = dfs(i,c+1);
return up+left+down+right+1;
};
int ans = 0;
for(int i = 0; i < grid.size(); i++)
{
for(int j = 0; j < grid[i].size(); j++)
{
if(grid[i][j] == 1)
{
ans = max(ans, dfs(i,j));
}
}
}
return ans;
}
};
这一题还算是独立解决吧,与上一题不同的地方在这里求岛屿面积的最大值,我的思考是带返回值的dfs,当然期间也是有一点错误的,if里面的边界条件处理出错,还有就是这个grid数组是int型的,我还惯性思维认为这是上一题的char,这里dfs还是采用的选与不选的思想,像这种相邻的元素还是用选与不选的思想比较好。
bfs写法:
class Solution {
public:
int maxAreaOfIsland(vector<vector<int>>& grid) {
//上左下右方向
int x[4] = {1, 0, -1, 0};
int y[4] = {0, -1, 0, 1};
deque<pair<int, int>> q;
int ans = 0;
for(int i = 0; i < grid.size(); i++)
{
for(int j = 0; j < grid[i].size(); j++)
{
if(grid[i][j] == 1)
{
q.push_back({i, j});
grid[i][j] = 0;
int cnt = 1;
while(!q.empty())
{
auto t = q.front();
int mx = t.first, my = t.second;
q.pop_front();
for(int k = 0; k < 4; k++)
{
int nextx = mx+x[k], nexty = my+y[k];
if(nextx >= 0 && nextx < grid.size() && nexty >= 0 &&
nexty < grid[0].size() && grid[nextx][nexty] == 1)
{
q.push_back({nextx, nexty});
grid[nextx][nexty] = 0;
cnt++;
}
}
}
ans = max(ans, cnt);
}
}
}
return ans;
}
};















 5123
5123











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









