






文章目录
一、Armstrong’s Axiom(阿姆斯特朗公理)
费曼理解:X→Y,X依赖Y,就是可以由X推出Y
Inclusion rule(包含规则): if Y ⊆ X, then X→Y(X包含Y,那么X可以推出Y)
A2: Transitivity rule(传递规则): if X → Y and Y → Z , then X → Z
A3: Augmentation rule(增广规则): if X → Y, then XZ → YZ
Union rule(合并规则): if X → Y and X →Z, then X → YZ
Decomposition rule(分解规则): if X → YZ, then X → Y and X → Z
二、函数依赖集的闭包
1.概念
The set of all functional dependencies logically implied by F is the closure of F (函数依赖集的闭包), denoted by F +.
2.求α的函数依赖集的闭包的算法
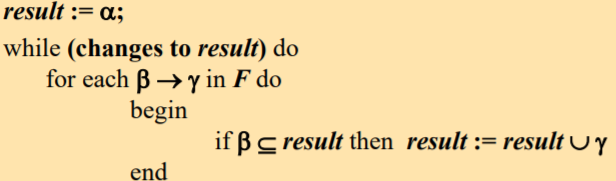
如果左边的在结果中,那么右边的就可以并入到结果中。不断循环,直到循环一遍后没有新的加入。
Example: Given R<U, F>, U = (A, B, C, D, E), F={B→CD, AD→E, B→A}, 那么(BC)+ = ?
- result = BC
- result = BCD (B→CD)
- result = BCDA (B→A)
- result = BCDAE (AD→E)
(BC)+ = BCDAE
3.用处
To check if a functional dependency α → β \alpha→\beta α→β holds (or, in other words, is in F+), just check if β ⊆ α + \beta \subseteq \alpha^+ β⊆α+
如果想看看 α → β \alpha→\beta α→β依赖是否成立,那么只要求出 α \alpha α的函数依赖集闭包 α + \alpha^+ α+,只要看看 β \beta β在不在其中。
例子:Example: for relation R<U, F>, U = {A, B, C, D, E}, F = {AB→C, B→D, C→E, EC→B, AC→B }。IS BE→CD implied by F?
For (BE)F+={BED} , not include CD, so not implied.
二、覆盖Cover
1. 最小Minimal Cover
就是覆盖掉多余的函数依赖。(多余是指可以由多个依赖的推断出新的依赖)
-
传递性多余:
{A → B, B → C,A → C}can be simplified to {A → B, B → C}。
解释:为什么不留A→C,因为A→C不能显示A→B和B→C,而A → B, B → C可以推断出A→C。 -
右多余RHS: 将右边的使用分解规则,然后判断是否是传递性多余
{A → B, B → C, A → CD}can be simplified to{A → B, B → C, A → D}
解释:A → CD可以分解为A→C和A→D,而A→C是传递性多余。 -
左多余LHS:
- 方法1(快速判断):将左边的AC判断其各个元素的依赖关系,可以推出的元素就是多余的。
{A → B, B → C, AC → D}can be simplified to {A → B, B → C, A → D}
解释:{A → B, B → C}推出A→C,A可以推出C,那么C就是多余的。 - 方法2(书面写法):对左边的AC求其各个元素的函数依赖性闭包(其他元素就遮住),如果其结果等于U(包含所有的元素),那么只保留其。
解释:对于A,{A → B, B → C, A→ D}, A + A^+ A+={ABCD};对于C,{A → B, B → C, C→ D}, C + C^+ C+={CD} - For
α
\alpha
α →
β
\beta
β in F, Attribute A is extraneous in
α
\alpha
α if F logically implies
{
F
–
(
α
→
β
)
}
∪
{
(
α
−
A
)
→
β
}
\{F – (\alpha → \beta)\} \cup \{(\alpha -A) → \beta\}
{F–(α→β)}∪{(α−A)→β}.
Then replace α → β \alpha → \beta α→β with ( α – A ) → β (\alpha – A) → \beta (α–A)→β
- 方法1(快速判断):将左边的AC判断其各个元素的依赖关系,可以推出的元素就是多余的。
Example: for relation R<U, F>, U = {A, B, C}, F={A → BC, B → C, A → B, AB → C}
compute the minimal cover of F.
-
右部分为单属性
F 1 F_1 F1= {A → B, A → C, B → C, AB → C} -
去掉左部冗余属性
对AB → C, ( A ) F 1 + (A)F_1^+ (A)F1+= {ABC}, 包含C,故用A → C替换之。
F2 = {A → B, A → C, B → C} -
去掉多余函数依赖
对A → C是多余,去掉,得Fmin = {A → B, B → C}
2.正则覆盖Canonical Cover
Example: for relation R<U, F>, U = {A, B, C, D, E}, F = {A→BC, BCD→E, B→D, A→D, E→A}, compute the canonical cover of F.
-
右部化为单一属性
F 1 F_1 F1={A→B, A→C, BCD→E, B→D, A→D, E→A} -
去掉左部冗余属性
( B C ) F + (BC)F^+ (BC)F+={BCDEA}=U
F 2 F_2 F2={A→B, A→C, BC→E, B→D, A→D, E→A} -
去掉多余函数依赖
for A→D because of (A)+F2-(A→D )=ABCED, is redundancy
F3 = {A→B, A→C, BC→E, B→D, E→A} -
合并函数依赖,得Fc = {A→BC, BC→E, B→D, E→A}
三、候选码Candidate Key
1.四种类型的属性
For given relation schema R<U, F>, attributes canbe:
- LHSA: attributes only appear in left hand side in FDS.(只出现在左边)
- RHSA: attributes only appear in right hand side in FDS.(只出现在右边)
- LRHSA: attributes appear in two sides in FDS.(两边都出现)
- NONA: attributes do NOT appear in FDS.(两边都没有出现)
可以作为候选码的是LHSA和NONA
2.算法
Algorithm to compute Candidate Key
-
Step1: for LHSA and NONA, noted X.
if X F + X_F^+ XF+= U, then X is the only CK, end. -
Step2: for LRHSA, noted Y
(对每个)for each attribute A in Y, if ( A X ) F + (AX)F^+ (AX)F+ = U, then (AX) is a Cankidate Key, let Y = Y - { A }, goto step3.(到这里如果Y空了就结束了) -
Step3:
(对每两个)for each pair of attributes Z in Y, if ( Z X ) F + (ZX)F^+ (ZX)F+ = U, then (ZX) is a
Cankidate Key, goto step4. -
Step4:
(对每三个)for each three, four,…. Attributes Z in Y, if (ZX) do not include any Cankidate Key, if ( Z X ) F + (ZX)F^+ (ZX)F+ = U, then (ZX) is a Cankidate Key. Until
Z is all of the attributes in Y
Example: U = {A, B, C, D, E }, F = { AE→BC, AC→E, B→C, C→D, CE→B }
- Step1: X = {A} , Y = { B, C, E}
- Step2: A + A^+ A+= {A}(看来不等于U要继续)
- Step3:
( A B ) + (AB)^+ (AB)+ = {ABCDE} = U, CK
( A C ) + (AC)^+ (AC)+ = {ACEDB} = U, CK
( A E ) + (AE)^+ (AE)+ = {AEBCD} = U, CK
Y = Φ - End. The CK of R is AB, AC, AE














 2303
2303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









