



 本文围绕阿里天池宠物年龄识别比赛展开,采用resnet18模型,经5轮优化使MAE得分从33提升到24。优化方法包括数据增强、回归模型调整、loss函数优化、数据清理、狗头检测和增加注意力机制等,最后提出迁移学习方案但未实现。
本文围绕阿里天池宠物年龄识别比赛展开,采用resnet18模型,经5轮优化使MAE得分从33提升到24。优化方法包括数据增强、回归模型调整、loss函数优化、数据清理、狗头检测和增加注意力机制等,最后提出迁移学习方案但未实现。
摘要
本次参加的比赛是阿里天池举办2023年举办的金融数据理解-赛题3 宠物年龄识别,参加比赛历时半个月,采用的模型最终决定是resnet18,前后经过了5轮优化,MAE最终得分从最开始的33,提升到了24。
采用的优化方法
数据增强
数据增强利用的是imgaug中的数据增强方法,我们通过观察宠物狗的图片,发现宠物狗图片的模糊度差别比较大,我们对图片增加了模糊。

又因为宠物狗一些图片会出现颗粒等噪声,于是我们对图像随机增加高斯噪声。

再对亮度进行调节,用来处理图像亮度不一的问题。

由于宠物狗在图片中的位置不确定,模型的预处理再添加镜像翻转和仿射变换。处理代码如下。
class imague_transforms():
def __init__(self):
self.seq = iaa.Sequential([
iaa.Fliplr(0.5),
iaa.Sometimes(
0.5,
iaa.GaussianBlur(sigma=(0, 1.5))
),
iaa.LinearContrast((0.75, 1.5)),
iaa.AdditiveGaussianNoise(scale=(0.0, 0.05 * 255)),
iaa.Multiply((0.8, 1.2), per_channel=0.2),
iaa.Affine(
scale=(0.5,1.5),
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)},
rotate=(-25, 25),
shear=(-8, 8)
)
])
def __call__(self,images):
images = self.seq(images=images)
return images
回归模型
经过两天的尝试后,实验后发现分类模型的处理效果并不好,经常会发生模型预测图片集中在同一个值,原因可能是因为分类模型的loss函数并不能很好的处理预测临近时的预测结果,这会让预测相近的错误分类和预测较远的预测分类的模型loss的值相近。
于是对模型进行调整,模型由最开始的192分类转成值为[0,1]的1分类回归模型,0-1对应宠物狗中0-191的年龄。
loss函数优化
loss函数在最开始的分类模型阶段,采用的是交叉熵损失函数。

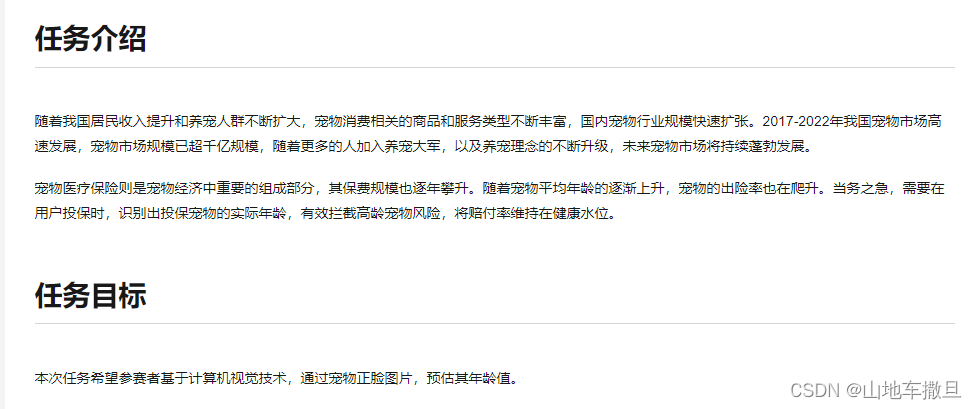
在采用回归模型后,实验将loss函数进行了替换,替换成了MSEloss。
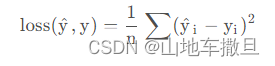
尝试后得分从原来的33提升到了25。
之后将loss替换为MAEloss,但得分无明显的增长。
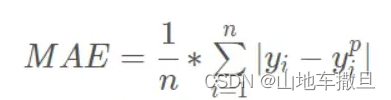
最终在经过多轮调试后我们最终运用的loss是Huberloss,并将超参数设置为1。
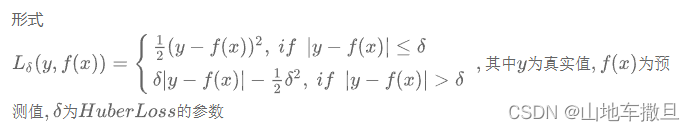

采用Huberloss的原因是因为我们发现宠物狗的年龄以70为限呈现正态分布。这就使得在150以上的数据非常的少,仅占总数据的1.5%。而Huberloss相较MSEloss可以增强MSE的离群点的鲁棒性,减小了对离群点的敏感度问题。且Huberloss下降速度介于MAE与MSE之间,弥补了MAE在Loss下降速度慢的问题 而更接近MSE。所以用Huberloss更加的合理。
数据清理
由于赛题中提出了在训练集和验证集中给出了6%的噪声图片,于是我们对训练集和验证集的图片进行了两轮的筛选,将模糊不清的图片,重复的图片以及过小的图片一一剔除。(某些相同图片出现了5、6张)

狗头检测
在观测了宠物狗的图片之后,我们认为宠物狗的年龄特征应大部分都存在于宠物狗的脑袋上,且在一些图片中宠物狗的占比较小,场景杂乱,会对模型的学习造成不利的影响。
实验采用了yolov5进行宠物狗的脑袋检测。
首先利用labelimg对500张宠物狗的图片进行标注。

再利用yolov5对图片进行学习,标注剩下的未标注的图片。

此方法使得最终的得分从25步进到24分。
增加注意力机制
实验尝试采用SEresnet18对图片进行学习,但实验结果并未发生变化,也可能是由于学习的轮数不够,利用SEresnet18学习了300轮。
总结
在这个比赛中所有能利用的数据,训练集加验证集总数为23000张,分类为0-191的192分类,实验采用了resnet18,利用回归模型对结果进行预测,虽然和一开始相比,最终成绩已经有了较大的提升,但最终结果仍不行。比赛中存在的一些问题,如数据集太少,宠物狗年龄特征不够明显等,我想的是在比赛中利用已经训练好的多分类模型进行迁移学习,改变模型的最后的分类层,利用已经学习好基础特征的模型再对该问题进行学习预测。但这个方案当时已经没有时间去实现了,比较遗憾。
代码
运行代码
import torch
import numpy as np
from tqdm import tqdm
import torch
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
import cv2
from ResNet import resnet34, resnet18,resnet101,resnet50
from vgg import vgg11_bn
from PIL import Image, ImageDraw
from data import transforms_detect_train,transforms_detect_val
import imgaug.augmenters as iaa
def data_get(annotation_path):
with open(annotation_path) as f:
lines = f.readlines()
return lines
class data_Dataset(Dataset):
def __init__(self, train_root, img_root, transform=''):
self.data = data_get(train_root)
self.img_root = img_root
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, index):
image_line = self.data[index].strip().split('\t')
img_path = self.img_root + image_line[0]
label = float(image_line[1])
img = cv2.imread(img_path)
# img = cv2.resize(img, (224, 224))
img=cv2.resize(img,(224,224))
# a=iaa.Sequential([iaa.CropToFixedSize(width=160, height=160, position="center")])
# img=a(images=img[None])[0]
# img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# img = self.transform(img)
label = torch.tensor(label)
return img, label
data_transform_train = transforms_detect_train(224)
data_transform_val = transforms_detect_val(224)
def VOC_dataset_collate1(batch):
images = []
targets = []
for img, target in batch:
if target>1:
continue
images.append(img)
targets.append(target)
images=np.array(images)
images=data_transform_train(images)
return images, torch.stack(targets)
def VOC_dataset_collate2(batch):
images = []
targets = []
for img, target in batch:
if target>1:
continue
images.append(img)
targets.append(target)
images = np.array(images)
images = data_transform_val(images)
return images, torch.stack(targets)
def dog_loss(y, t):
loss = torch.abs(y - t).sum() / len(t)
return loss
def huber_loss(y,t):
a=dog_loss(y,t)
t=1
if a<t:
loss=(a**2)/2
else:
loss=t*(a-t/2)
return loss
def train():
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# device = torch.device('cpu')
print('using {} device.'.format(device))
annotations_train = r'./annotations/annotations/train.txt'
annotations_val = r'./annotations/annotations/val.txt'
train_root = r'/home/lpl/yy/dog_age/trainset/trainset/'
val_root = r'/home/lpl/yy/dog_age/valset/valset/'
train_dataset = data_Dataset(annotations_train, train_root)
val_dataset = data_Dataset(annotations_val, val_root)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=4,pin_memory=False,
drop_last=False,num_workers=8, collate_fn=VOC_dataset_collate1)
val_loader = DataLoader(val_dataset, shuffle=True, batch_size=32,pin_memory=True,
drop_last=False, collate_fn=VOC_dataset_collate2)
model = resnet50()
# loss_function = nn.CrossEntropyLoss()
# loss_function = nn.MSELoss()
loss_function = nn.SmoothL1Loss()
try:
model.load_state_dict(torch.load('./resnet50.pth'))
print('load model')
except:
pass
for param in model.parameters():
param.requires_grad = False
model.fc = torch.nn.Linear(2048, 1)
model.to(device)
with open('lr.txt', 'r') as f:
lr = float(f.readline())
optimizer = torch.optim.SGD(model.parameters(), lr=0.0001, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.95)
max_MAE = 100
for epoch in range(1000):
pbar = tqdm(total=len(train_loader), unit='batches')
pbar.set_description('Epoch {}/{}'.format(epoch, 1000))
model.train()
total_loss = 0
num = 0
for img, target in train_loader:
optimizer.zero_grad()
y = model(img.to(device))
# y = torch.max(y, dim=1)[1]?
loss = loss_function(torch.squeeze(y), target.to(device))
loss.backward()
total_loss += loss.item()
num += 1
batch_info = 'Loss {:.4f}'.format(total_loss / num)
pbar.set_postfix_str(batch_info)
pbar.update()
optimizer.step()
pbar.close()
torch.save(model.state_dict(), 'model_vesion1_latest.pth')
# pbar = tqdm(total=len(val_loader), unit='batches')
# pbar.set_description('Epoch val ')
# model.eval()
#
# num = 0
# MAE = 0
# acc=0
# with torch.no_grad():
# for img, target in val_loader:
# y = model(img.to(device))
#
# # predict_y = (torch.max(y, dim=1)[1]*20)+10
# # y = torch.max(y, dim=1)[1]
# y=torch.abs(torch.squeeze(y))
# # acc += torch.eq(y, target.to(device)).sum().item()
# MAE += torch.abs(y - target.to(device)).sum()
# num += len(target)
# pbar.update()
# print("pred", torch.squeeze(y))
# print("target", target)
# # val_accurate = acc / num
# # print('accurate:' + str(val_accurate))
#
# print('MAE:' + str(MAE / num * 192))
# if MAE < max_MAE:
# torch.save(model.state_dict(), 'model_vesion1_best.pth')
# max_MAE=MAE
scheduler.step()
print(optimizer.param_groups[0]['lr'])
with open('lr.txt', 'w') as f:
f.write(str(optimizer.param_groups[0]['lr']))
pbar.close()
if __name__ == '__main__':
train()
数据增强代码
import os
import random
import torch
from torch import nn,Tensor
from PIL import Image,ImageDraw
from torchvision.transforms import functional as F
import numpy as np
import cv2
import imgaug.augmenters as iaa
class Compose(object):
def __init__(self,transforms):
self.transforms=transforms
def __call__(self, image):
for t in self.transforms:
image=t(image)
return image
class ToTensor(object):
def __call__(self,images):
images=torch.tensor(images,dtype=torch.float)
images = images.permute((0,3, 1, 2)).contiguous()
return images
class Normalize(object):
def __init__(self,mean,std,inplace=False):
self.std=std
self.mean=mean
self.inplace = inplace
def __call__(self, images):
for i in range(len(images)):
images[i]=F.normalize(images[i], self.mean, self.std, self.inplace)
return images
#随机水平翻转
class RandomHorizontalFlip(object):
def __init__(self,prob=0.5):
self.prob=prob
def __call__(self, image):
if random.random()<self.prob:
image=image.flip(-1)
return image
#填充图片在设定好的全黑图片上,然后摆放在随机位置
class Resize_Pad(object):
def __init__(self,img_size,randing=True):
self.img_size=img_size
self.randing=randing
def __call__(self, image):
#不摆放在随机位置,左上角摆放图片
image=self.Resize_LocLeft(image)
image=self.Pad(image)
return image
def Pad(self,image,dx=0,dy=0):
# type: (List[Tensor], int) -> Tensor
# 创建shape为batch_shape且值全部为0的tensor
batched_img=image.new_full([1,3,self.img_size,self.img_size],0)
batched_img[:,:image.shape[0],dy:image.shape[1]+dy,dx:image.shape[2]+dx].copy_(image)
return batched_img
def Resize_LocLeft(self, image):
im_shape = torch.tensor(image.shape[-2:])
max_size = float(torch.max(im_shape)) # 获取高宽中的最大值
size=float(self.img_size)# 指定输入图片的最长边长,注意是self.min_size不是min_size
scale_factor=size/max_size # 根据指定最小边长和图片最小边长计算缩放比例
# interpolate利用插值的方法缩放图片
# image[None]操作是在最前面添加batch维度[C, H, W] -> [1, C, H, W]
# bilinear只支持4D Tensor
image = torch.nn.functional.interpolate(
image[None], scale_factor=scale_factor, mode='bilinear', recompute_scale_factor=True,
align_corners=False)[0]
return image
#将图片转为HSV图像,改变其色调(Hue),饱和度(Saturation),亮度(Value)
#输入为PIL格式,不能是tensor
class distort_image(object):
def __init__(self,hue=.1,sat=1.5,val=1.5):
self.hue =hue
self.sat =sat
self.val =val
def __call__(self,image):
hue = self.rand(-self.hue, self.hue)
sat = self.rand(1, self.sat) if self.rand() < .5 else 1 / self.rand(1, self.sat)
val = self.rand(1, self.val) if self.rand() < .5 else 1 / self.rand(1, self.val)
x = cv2.cvtColor(np.array(image, np.float32) / 255, cv2.COLOR_RGB2HSV)
x[..., 0] += hue*360
x[..., 0][x[..., 0]>1] -= 1
x[..., 0][x[..., 0]<0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x[:,:, 0]>360, 0] = 360
x[:, :, 1:][x[:, :, 1:]>1] = 1
x[x<0] = 0
image = cv2.cvtColor(x, cv2.COLOR_HSV2RGB)*255 # numpy array, 0 to 1
return image
def rand(self,a=0,b=1):
return np.random.rand()*(b-a)+a
class imague_transforms():
def __init__(self):
self.seq = iaa.Sequential([
iaa.Fliplr(0.5),
iaa.Sometimes(
0.5,
iaa.GaussianBlur(sigma=(0, 1.0))
),
iaa.LinearContrast((0.75, 1.5)),
iaa.AdditiveGaussianNoise(scale=(0.0, 0.05 * 255)),
iaa.Multiply((0.8, 1.2), per_channel=0.2),
iaa.Affine(
scale=(0.5,1.5),
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)},
rotate=(-25, 25),
shear=(-8, 8)
)
])
def __call__(self,images):
images = self.seq(images=images)
return images
class transforms_detect_train(nn.Module):
def __init__(self,img_size,mean=(0.406,0.456,0.485),std=(0.225,0.224,0.229)):
self.img_size=img_size
self.mean=mean
self.std=std
self.augment=Compose([
# distort_image(),
# RandomHorizontalFlip(),
# Resize_Pad(img_size=img_size),
imague_transforms(),
ToTensor(),
Normalize(mean=mean,std=std)
])
def __call__(self, img):
return self.augment(img)
class transforms_detect_val(nn.Module):
def __init__(self,img_size,mean=(0.406,0.456,0.485),std=(0.225,0.224,0.229)):
self.img_size=img_size
self.mean=mean
self.std=std
self.augment=Compose([
# distort_image(),
ToTensor(),
# RandomHorizontalFlip(),
# Resize_Pad(img_size=img_size),
Normalize(mean=mean,std=std)
])
def __call__(self, img):
return self.augment(img)
if __name__ == '__main__':
dir='./trainset/trainset/'
name_list=os.listdir(dir)
import torchvision.transforms as transforms
transform=transforms_detect(224)
for name in name_list:
image=Image.open(dir+name)
image=transform(image)
image = transforms.ToPILImage()(image[0])
image.show()
resnet模型代码
import torch.nn as nn
import torch
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channel * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=width,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, groups=groups,
kernel_size=3, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
# -----------------------------------------
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channel*self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,
block,
blocks_num,
num_classes=1000,
include_top=True,
groups=1,
width_per_group=64):
super(ResNet, self).__init__()
self.include_top = include_top
self.in_channel = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
layers.append(block(self.in_channel,
channel,
downsample=downsample,
stride=stride,
groups=self.groups,
width_per_group=self.width_per_group))
self.in_channel = channel * block.expansion
for _ in range(1, block_num):
layers.append(block(self.in_channel,
channel,
groups=self.groups,
width_per_group=self.width_per_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet18(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [2,2,2,2], num_classes=num_classes, include_top=include_top)
def resnet34(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet50(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet50-19c8e357.pth
return ResNet(Bottleneck, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)
def resnet101(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnet101-5d3b4d8f.pth
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes=num_classes, include_top=include_top)
def resnext50_32x4d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth
groups = 32
width_per_group = 4
return ResNet(Bottleneck, [3, 4, 6, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)
def resnext101_32x8d(num_classes=1000, include_top=True):
# https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth
groups = 32
width_per_group = 8
return ResNet(Bottleneck, [3, 4, 23, 3],
num_classes=num_classes,
include_top=include_top,
groups=groups,
width_per_group=width_per_group)


















 2813
2813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









