






摘要
本篇文章说明了如何利用爬虫批量拉取百度网盘的数据,尝试了两个方法,分别是实时的下载和先拉去再下载。最终实现是基于方法2进行操作。
版本1
我们首先对总网页的url进行提取网页地址

采用request就可以了
#获取urls
resp=requests.get(url='https://www.yingyanshe.cn/5275.html',headers=headers)
et=etree.HTML(resp.text)
url_list=et.xpath('//*[@id="post-5275"]/div[2]/div/div/section/div/div/div/div/div/table/tbody/tr')
urls = []
for url in url_list:
urls.append(url.xpath('./td[2]/a/text()')[0])
在获取每个要拉去资源的url后用selenium对网页去进行拉取。
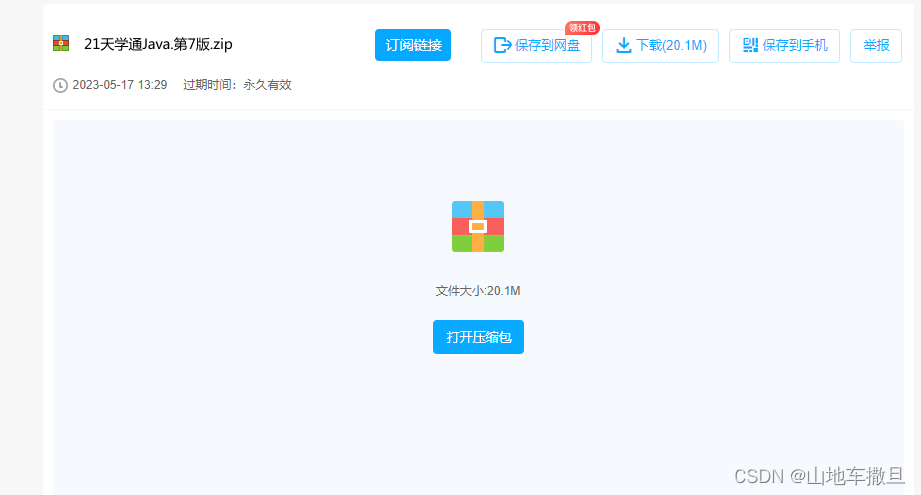
拉取的时候需要注意,不能直接使用selenium对网页进行操作,因为这样的话网盘这边会检测出我们是一个脚本,不会为我们登录已经保存的账户,所以我们需要先用程序打开一个空闲的网页。利用线程的方式让网页一直存在。
def open_chrome():
os.system(
r'c: && cd C:\Users\lenovo\AppData\Local\Google\Chrome\Application && chrome.exe --remote-debugging-port=9527 --user-data-dir=“./aut1”')
thread=Process(target=open_chrome,name='1')
thread.start()
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
b = webdriver.Chrome(options=options)
这样操作之后就不能检测到selenium自带的程序标志了。我们就可以直接对网页上的资源进行拉取下载了。但在拉取期间由于频繁的操作会出现验证码需要我们去填写。这里我们就利用超级鹰的识别工具去识别验证码。
for url in urls:
print(url)
#判断网页是否存在
try:
b.get(url)
time.sleep(3)
b.find_element_by_xpath('//*[@id="layoutMain"]/div[1]/div[1]/div/div[3]/div/div/div[2]/a[2]/span').click()
except:
print('网页错误')
continue
#判断是否需要验证码下载
try:
time.sleep(3)
while 1:
#验证码可能错误
try:
img_url = b.find_element_by_xpath('//*[@id="downloadVerify"]/div[1]/img').get_attribute('src')
print(img_url)
img_data = requests.get(url=img_url, headers=headers, verify=False)
img_data = img_data.content
with open('E:\程序\python\workplace\pa\实战\网盘爬取/code.jpg', 'wb') as fp:
fp.write(img_data)
im = open('code.jpg', 'rb').read()
info=chaojiying.PostPic(im, 1004)
pic_str=info['pic_str']
b.find_element_by_xpath('//*[@id="downloadVerify"]/div[1]/input').send_keys(pic_str)
b.find_element_by_xpath('//*[@id="dialog1"]/div[3]/a[1]/span').click()
except:
break
except:
pass
这样虽然能够正常下载了但是由于百度网盘的问题,使得下载链接的拉取和下载非常的慢,且经常会出现下图中的问题使得网页卡死不动。
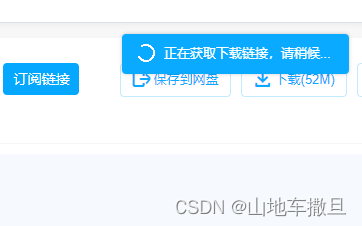
所以版本1的操作是有问题的,我们不应和其他网页一样进行实时下载。
版本2
在进入拉取页面之前我们的操作都和版本1相同,进入存储总url的网页,拉取所有要爬取的url,进入url。
但在这里我们不再对数据进行实时的一个下载,我们将所有的数据保存在我们的网盘中,再进行统一的下载。
进入网盘后,我们正常的操作是点击保存到网盘,再选择保存的位置。
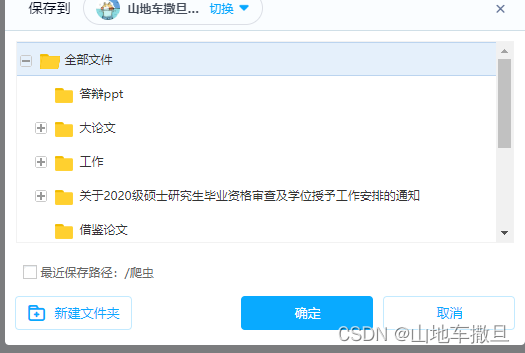
在这里我选择的是最近保存路径,所以正常的操作应该是把左下角的√给打上,再点击确定。
接下来我们用程序进行操作。
for url in urls:
print(url)
#判断网页是否存在
try:
b.get(url)
b.find_element_by_xpath('//*[@id="layoutMain"]/div[1]/div[1]/div/div[3]/div/div/div[2]/a[1]/span').click()
time.sleep(1)
except:
print('网页错误')
continue
try:
b.find_element_by_xpath('//*[@id="fileTreeDialog"]/div[3]/span').click()
b.find_element_by_xpath('//*[@id="fileTreeDialog"]/div[4]/a[2]/span/span').click()
time.sleep(1)
except:
print('点击失败')
至此我们就实现了百度网盘的批量拉取,之后再去百度云盘下载所有资源就可以了。


















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









