







一:前言
在正式学习神经网络之前,我们需要对一些必要的知识有一个具体的认识。
Q:Tensorflow是什么?我们为什么要使用Tensorflow?
A:TensorFlow是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。
Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究。
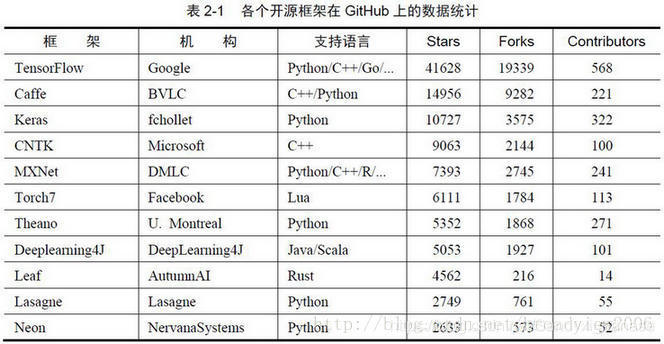
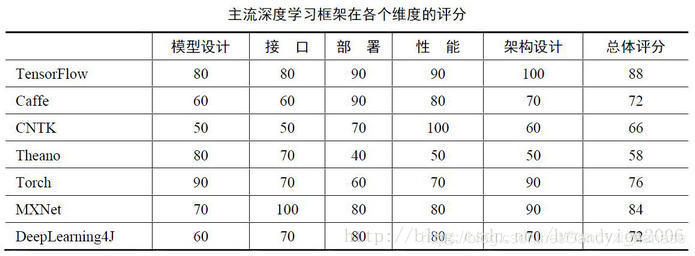
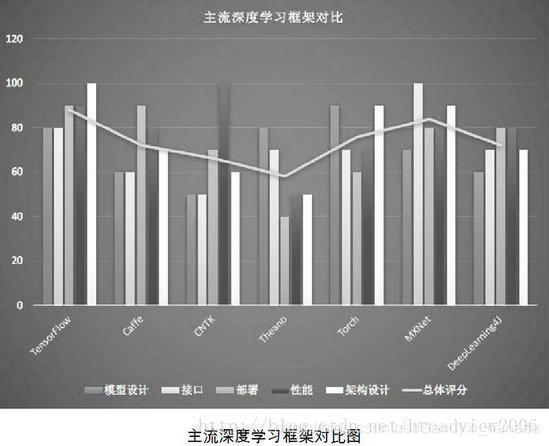
Q:MNIST数据集是什么?我们为什么要使用MNIST数据集?
A:MNIST是一个手写数字图像的数据集,每幅图像都由一个整数标记。它主要用于机器学习算法的性能对标。深度学习算法处理MNIST的效果相当好,准确率可达到99.7%以上。

MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
当我们学习新的编程语言时,通常第一个程序就是打印输出著名的“Hello World!”。在深度学习中,MNIST数据集就相当于Hello World。
Q:这篇博客的最终的目的是什么?
A:为了更好的理解Neural Network,使用Tensorflow实现两个神经网络(CNN与LeNet-5),然后使用MNIST数据集进行测试。我们的任务是使用数据训练一个可以准确识别手写数字的神经网络模型,并使用Tensorflow对训练过程各个参数的变化进行可视化(说简单点就是能对你训练的整个过程有一个清晰的掌控,并且能让你看到)。
相信你已经有了一个最基本的认识。知道学习的目的,来源以及最终想要达成什么结果才会在学习中途始终保持头脑清醒,知道自己在做什么,才能对深入学习保持长期的动力。 接下来让我们进入本篇吧。
二:具体步骤及代码
注意:接下来的所有步骤,我们使用的是Python编程语言进行操作,并且是在你已经在某个版本的Python下安装好Tensorflow框架的前提下进行的,如果你还没有安装好Tensorflow,你可以到以下的博客中去学习:
https://blog.csdn.net/cs_hnu_scw/article/details/79695347
一:下载MNIST 数据集
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
- Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
- Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
- Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
- Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
四个文件的作用:
train-images-idx3-ubyte.gz 训练图像数据(训练集)
train-labels-idx1-ubyte.gz 训练图像标签
t10k-images-idx3-ubyte.gz 验证图像数据
(测试集,测试的结果能得到一个数字来体现你训练的结果)
t10k-labels-idx1-ubyte.gz 验证图像标签
gz格式文件:是一种压缩文件,在Linux和macOS下常见,Linux和macOS都可以直接解压使用这种压缩文件。如果你使用的是Windows系统,那么我建议之间用代码对文件进行操作,如果你是在Linux和macOS系统下运行,那么你可以解压具体看下里面有哪些内容。
代码:
# 从tensorflow.examples.tutorials.mnist引入模块。
from tensorflow.examples.tutorials.mnist import input_data
# 从MNIST_data/中读取MNIST数据。这条语句在数据不存在时,会自动执行下载
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
请注意你的py文件是否与MNIST_data文件夹处于同一目录下,以及文件夹的名字有无错误。下面的代码也是如此,在此不过多赘述。
导入数据集后,在刚才的代码下添加下列代码:
# 查看训练数据的大小
print(mnist.train.images.shape) # (55000, 784)
print(mnist.train.labels.shape) # (55000, 10)
# 查看验证数据的大小
print(mnist.validation.images.shape) # (5000, 784)
print(mnist.validation.labels.shape) # (5000, 10)
# 查看测试数据的大小
print(mnist.test.images.shape) # (10000, 784)
print(mnist.test.labels.shape) # (10000, 10)
你可以得到如下的结果:

MNIST 数据集中的每张图片由 28 x 28 个像素点构成, 每个像素点用一个灰度值表示.它的大小则为784个像素.
二:将数据集读取保存成图片
这里我们以保存20张图片为例
from tensorflow.examples.tutorials.mnist import input_data
import scipy.misc
import os
# 读取MNIST数据集。如果不存在会事先下载。
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 我们把原始图片保存在MNIST_data/raw/文件夹下
# 如果没有这个文件夹会自动创建
save_dir = 'MNIST_data/raw/'
if os.path.exists(save_dir) is False:
os.makedirs(save_dir)
# 保存前20张图片
for i in range(20):
# 请注意,mnist.train.images[i, :]就表示第i张图片(序号从0开始)
image_array = mnist.train.images[i, :]
# TensorFlow中的MNIST图片是一个784维的向量,我们重新把它还原为28x28维的图像。
image_array = image_array.reshape(28, 28)
# 保存文件的格式为 mnist_train_0.jpg, mnist_train_1.jpg, ... ,mnist_train_19.jpg
filename = save_dir + 'mnist_train_%d.jpg' % i
# 将image_array保存为图片
# 先用scipy.misc.toimage转换为图像,再调用save直接保存。
scipy.misc.toimage(image_array, cmin=0.0, cmax=1.0).save(filename)
print('Please check: %s ' % save_dir)
保存完图片后,你就能在raw这个文件夹里看到那20张图片了
三:图像标签的one-hot表示
one-hot向量将类别变量转换为机器学习算法易于利用的一种形式的过程,这个向量的表示为一项属性的特征向量,也就是同一时间只有一个激活点(不为0),这个向量只有一个特征是不为0的,其他都是0,特别稀疏。
举个例子:一个特征“性别”,性别有“男性”、“女性”,这个特征有两个特征值,也只有两个特征值,如果这个特征进行one-hot编码,则特征值为“男性”的编码为“10”,“女性”的编码为“01”,如果特征值有m个离散特征值,则one-hot后特征值的表示是一个m维的向量,每个样本的特征只能有一个值,这个值的向量坐标上就是1,其他都是0,如果有多个特征,“性别”有两个特征,“尺码”:M、L、XL三个值,我们用“01”表示男性,M为“100”,L为“010”,XL为“001”,所以一个样本,【“男性”、“L”】 one-hot编码为[10 010],一个样本也就是5维的向量,这就是one-hot形式。
具体代码:
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
# 读取mnist数据集。如果不存在会事先下载。
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 看前20张训练图片的label
for i in range(20):
# 得到one-hot表示,形如(0, 1, 0, 0, 0, 0, 0, 0, 0, 0)
one_hot_label = mnist.train.labels[i, :]
# 通过np.argmax我们可以直接获得原始的label
# 因为只有1位为1,其他都是0
label = np.argmax(one_hot_label)
print('mnist_train_%d.jpg label: %d' % (i, label))
你可以得到每张图片的label(标签个数)

四:Softmax回归的实现
Softmax 可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于 10 个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被 Softmax 函数转换成为一个概率值。
比如判断一张图片中的动物是什么,可能的结果有三种,猫、狗、鸡,假如我们可以经过计算得出它们分别的得分为 3.2、5.1、-1.7,Softmax 的过程首先会对各个值进行次幂计算,分别为 24.5、164.0、0.18,然后计算各个次幂结果占总次幂结果的比重,这样就可以得到 0.13、0.87、0.00 这三个数值,所以这样我们就可以实现差别的放缩,即好的更好、差的更差。
如果要进一步求损失值可以进一步求对数然后取负值,这样 Softmax 后的值如果值越接近 1,那么得到的值越小,即损失越小,如果越远离 1,那么得到的值越大。
具体代码:
# 导入tensorflow。
# 这句import tensorflow as tf是导入TensorFlow约定俗成的做法,请大家记住。
import tensorflow as tf
# 导入MNIST教学的模块
from tensorflow.examples.tutorials.mnist import input_data
# 与之前一样,读入MNIST数据
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 创建x,x是一个占位符(placeholder),代表待识别的图片
x = tf.placeholder(tf.float32, [None, 784])
# W是Softmax模型的参数,将一个784维的输入转换为一个10维的输出
# 在TensorFlow中,变量的参数用tf.Variable表示
W = tf.Variable(tf.zeros([784, 10]))
# b是又一个Softmax模型的参数,我们一般叫做“偏置项”(bias)。
b = tf.Variable(tf.zeros([10]))
# y=softmax(Wx + b),y表示模型的输出
y = tf.nn.softmax(tf.matmul(x, W) + b)
# y_是实际的图像标签,同样以占位符表示。
y_ = tf.placeholder(tf.float32, [None, 10])
# 至此,我们得到了两个重要的Tensor:y和y_。
# y是模型的输出,y_是实际的图像标签,不要忘了y_是独热表示的
# 下面我们就会根据y和y_构造损失
# 根据y, y_构造交叉熵损失
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y)))
# 有了损失,我们就可以用随机梯度下降针对模型的参数(W和b)进行优化
train_step=tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# 创建一个Session。只有在Session中才能运行优化步骤train_step。
sess = tf.InteractiveSession()
# 运行之前必须要初始化所有变量,分配内存。
tf.global_variables_initializer().run()
print('start training...')
# 进行1000步梯度下降
for _ in range(1000):
# 在mnist.train中取100个训练数据
# batch_xs是形状为(100, 784)的图像数据,batch_ys是形如(100, 10)的实际标签
# batch_xs, batch_ys对应着两个占位符x和y_
batch_xs, batch_ys = mnist.train.next_batch(100)
# 在Session中运行train_step,运行时要传入占位符的值
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
# 正确的预测结果
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
# 计算预测准确率,它们都是Tensor
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 在Session中运行Tensor可以得到Tensor的值
# 这里是获取最终模型的正确率
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) # 0.9185
训练后,你会得到一个数字,这个数字就是Softmax回归后得到的概率。
五:测试模型的准确率
这里我们使用两种网络,一个是CNN,一个是LeNet-5。
CNN
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
if __name__ == '__main__':
# 读入数据
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# x为训练图像的占位符、y_为训练图像标签的占位符
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
# 将单张图片从784维向量重新还原为28x28的矩阵图片
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 第一层卷积层
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 第二层卷积层
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
# 全连接层,输出为1024维的向量
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# 使用Dropout,keep_prob是一个占位符,训练时为0.5,测试时为1
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 把1024维的向量转换成10维,对应10个类别
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
# 我们不采用先Softmax再计算交叉熵的方法,而是直接用tf.nn.softmax_cross_entropy_with_logits直接计算
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
# 同样定义train_step
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 定义测试的准确率
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 创建Session和变量初始化
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
# 训练20000步
for i in range(20000):
batch = mnist.train.next_batch(50)
# 每100步报告一次在验证集上的准确度
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g" % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
# 训练结束后报告在测试集上的准确度
print("test accuracy %g" % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
这里我们训练了20000步,也花费了博主较长的时间,你可以选择减少训练的步数,但相应的准确率就会降低。博主训练了20000步后的结果如下
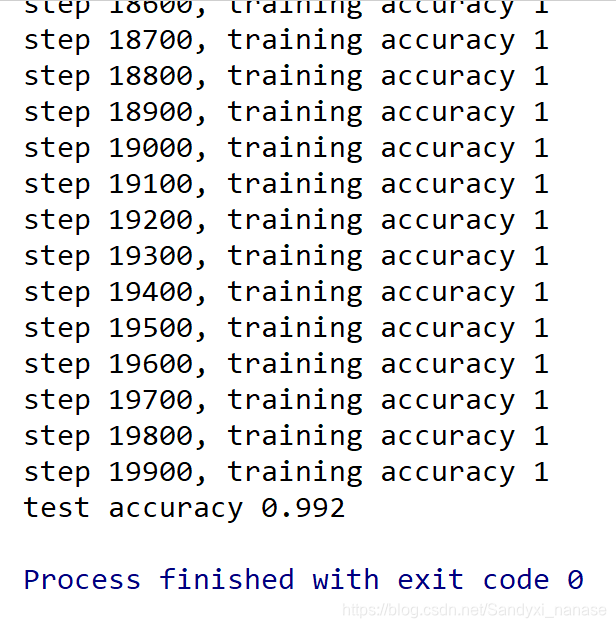
是一个相当可观的数字了。
如果使用LeNet-5的话,代码如下(为了节约时间,这里我们训练1001步):
# 使用LeNet-5实现mnist手写数字分类识别
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import os.path as ops
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
tf.reset_default_graph()
# 获取mnist数据
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # 一定要加 one_hot
# 注册默认session 后面操作无需指定session 不同sesson之间的数据是独立的
sess = tf.InteractiveSession() # 创建一个session对象,之后的运算都会跑在这个session里
## 参数初始化
# 构造参数W函数 给一些偏差0.1防止死亡节点,标准差为0.1
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1) # 权重在初始化时应该加入少量的噪声来打破对称性以及避免0梯度 truncated_normal函数产生正态分布
return tf.Variable(initial)
# 构造偏差b函数 ,给偏置加了一个正值0.1来避免死亡节点
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
## 定义卷积层和池化层函数
# x是输入,W为卷积参数 如[5,5,1,30] 前两个表示卷积核的尺寸
# 第三个表示通道channel 第四个表示提取多少类特征
# strides 表示卷积模板移动的步长,中间两个参数都是1代表不遗漏的划过图片每一个点
# padding 表示边界处理方式这里的SAME代表给边界加上padding让输出和输入保持相同尺寸
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# ksize 使用2x2最大池化即将一个2x2像素块变为1x1 最大池化保持像素最高的点
# stride也横竖两个方向为2歩长,如果步长为1 得到尺寸不变的图片
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
## 定义张量流输入格式
# reshape变换张量shape 2维张量变4维 [None, 784] to [-1,28,28,1] 784=28*28
# [-1, 28, 28, 1] -1表示样本数量不固定 28 28为尺寸 1为通道
x = tf.placeholder(tf.float32, [None, 784],
name='x') # placeholder 占位符 此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值 [None, 784]表示列是784,行不定
y_ = tf.placeholder(tf.float32, [None, 10], name='y_') # 来自MNIST的训练集,每一个图片所对应的真实值
x_image = tf.reshape(x, [-1, 28, 28, 1]) # 第2、第3维对应图片的宽、高,最后一维代表图片的颜色通道数(因为是灰度图所以这里的通道数为1,如果是rgb彩色图,则为3)
## 构建模型
# 第一次卷积池化 卷积层用ReLU激活函数
# 权重这个值很重要,因为我们深度学习的过程,就是发现特征,经过一系列训练,从而得出每一个特征对结果影响的权重,我们训练,就是为了得到这个最佳权重值
W_conv1 = weight_variable([5, 5, 1, 32]) # 前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目
b_conv1 = bias_variable([32]) # 对于每一个输出通道都有一个对应的偏置量 这里定义32维常量为0.1
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # 把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数 32*28*28
h_pool1 = max_pool_2x2(h_conv1) # 最后进行max pooling 32*14*14
# 第二次卷积池化 卷积层用ReLU激活函数
W_conv2 = weight_variable([5, 5, 32, 64]) # 每个5x5的patch会得到64个特征
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # 64*14*14
h_pool2 = max_pool_2x2(h_conv2) # 64*7*7
# 全连接层使用ReLU激活函数 reshape改变张量结构 变成一维
W_fc1 = weight_variable([7 * 7 * 64, 1024]) # 图片尺寸减小到7x7,我们加入一个有1024个神经元的全连接层,用于处理整个图片
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # tf.matmul 矩阵乘法,表示全连接,而不是conv2d
# 为了减轻过拟合使用一个Dropout层,随机丢掉一些神经元不参与运算
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# softmax层 第二个全连接层 分为十类数据 softmax后输出概率最大的数字
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2, name="y_conv") # tf.nn.softmax 而不是 tf.nn.relu, y_conv是概率
## 保存模型
# 创建saver的时候可以指明要存储的tensor,如果不指明,就会全部存下来
saver = tf.train.Saver(max_to_keep=2) # 指定保存最后2个
# saver = tf.train.Saver() # 默认保存最后5个
# 保存模型的路径
ckpt_file_path = "./models/" # models是文件夹,mnist是文件命名使用的
path = os.path.dirname(os.path.abspath(ckpt_file_path))
if os.path.isdir(path) is False:
os.makedirs(path)
# loss函数 模型预测的类别概率输出与真实类别的one hot形式进行cross entropy损失函数的计算。
cross_entropy = tf.reduce_mean(
-tf.reduce_sum(y_ * tf.log(y_conv), reduction_indices=[1])) # 交叉熵 reduction_indices参数,表示函数的处理维度
# 优化算法Adam函数
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # 这里用Adam优化器优化 也可以使用随机梯度下降 1e-4表示学习率
# cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv),reduction_indices=[1]) #交叉熵
# train_step = tf.train.GradientDescentOptimizer(0.5*1e-4).minimize(cross_entropy) # 梯度下降法
# accuracy函数 tf.equal(A, B)是对比这两个矩阵或者向量的相等的元素,如果是相等的那就返回True,反之返回False
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) # tf.argmax()返回最大数值的下标, 第二个参数 0按列找,1按行找
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 准确率 tf.cast是类型转换函数,tf.float32是转换目标类型,返回Tensor
tf.global_variables_initializer().run() # 使用全局参数初始化器 并调用run方法 来进行参数初始化
# 训练1001次 每次大小为50的mini-batch 每100次训练查看训练结果 用以实时监测模型性能 1001次是iteration,其实只有1个epoch???
for i in range(1001):
batch = mnist.train.next_batch(50)
# batch[0] [1] 分别指数据维度 和标记维度 将数据传入定义好的优化器进行训练
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) # train_step是定义好的优化器
if i % 100 == 0: # 每100次验证一下准确率
# feed_dict:一个字典,用来表示tensor被feed的值(联系placeholder一起看)
train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0}) # 评估模型,得出训练的准确率
print("step %d, train_accuracy %g" % (i + 1, train_accuracy)) # %g 指数(e) 或浮点数(根据显示长度)
if i % 100 == 0:
model_name = 'mnist_{:s}'.format(str(i + 1))
model_save_path = ops.join(ckpt_file_path, model_name)
saver.save(sess, model_save_path, write_meta_graph=True) # 保存模型
print("test accuracy %g" % accuracy.eval(feed_dict={ # 评估模型,得出测试的准确率
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0
}))
得到的结果如下:
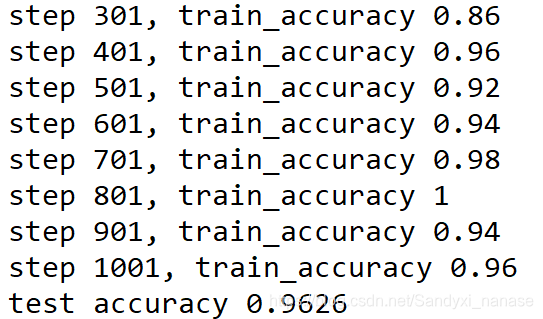
跟CNN相比,差距也不是太大,结果也是相当可观。
如果你对LeNet-5网络还不够熟悉,可以参考:
https://cuijiahua.com/blog/2018/01/dl_3.html
三:总结
这是新人第一次写博客,有什么问题欢迎指正,也希望能和大家一起进步。当然,今天我们只完成了测试集最后的准确率部分,最后真正能否分类出图片,还要进一步的操作才行。
参考blog
https://blog.csdn.net/simple_the_best/article/details/75267863
https://blog.csdn.net/randompeople/article/details/83244766
https://cuiqingcai.com/4898.html














 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









