






2023年初随着chatgpt的盛行,以及llama\chatglm等开源LLM的公布,大模型成了nlp继bert之后的新流行趋势。而在LLM基础上额外增加其他模态理解能力的MLLM(Multimodal Large Language Model)也踊跃了许多优秀的工作:BLIP2、LlaVa、minigpt4等等。
除了这些增加rgb图像理解的MLLM,也有理解生物医学图像的llava-med/Xray-GPt,理解多种模态的imagebind_LLM\video-llama等等。后者在训练时由于其他模态数据的稀少,往往采用统一的编码器(languagebind\imagebind),并只利用可见光数据进行对齐和指令微调训练。
而我因为某种原因不得不用红外数据来微调MLLM,为此我进行了一些调研和探索。
红外领域数据集统计
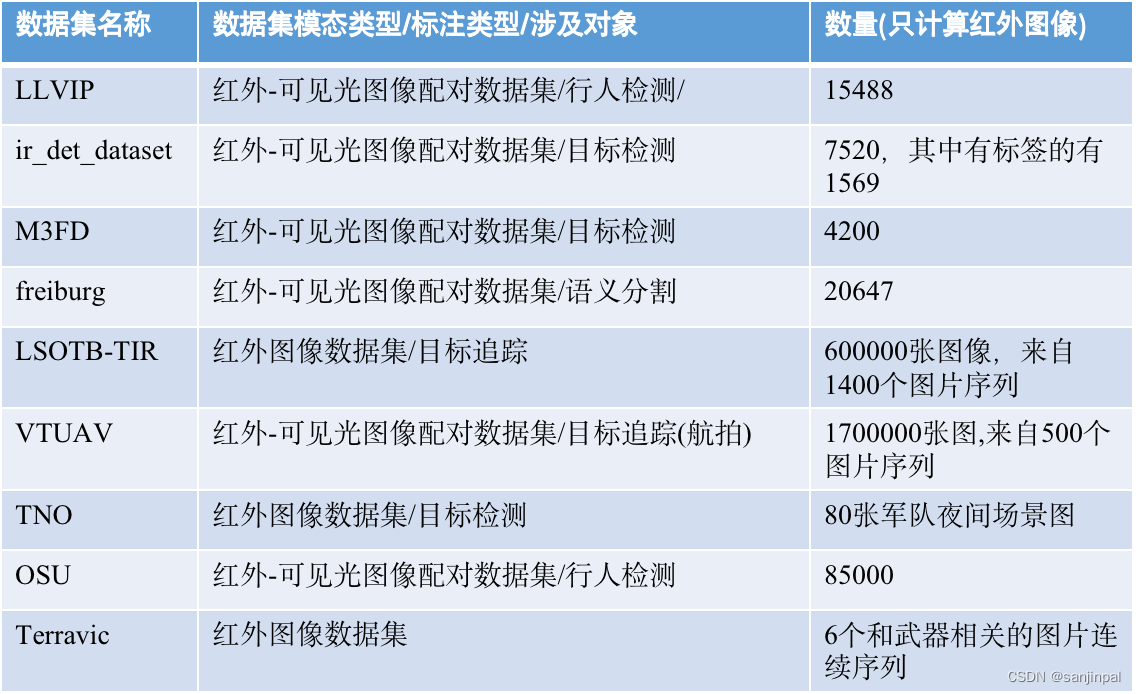
可见,传统红外数据有以下几个问题:
- 任务数量少:限于行人检测、目标检测、目标追踪等少数几个任务(无法像insruct-BLIP一样达到指令数据的多样性)
- 模态单一:限于红外单模态/红外-可见光融合
- 数据量少:相比于可见光数据集动辄M级的数据(cc12m/cc3m),红外的数据差了3-4个数量级
- 图像领域(场景)单一:相比COCO从web上收集并处理得到的多样数据,这些由专业设备采集的图像往往局限于某一个单一区域或是一段连续帧。例如LLVIP就是来自某一街道固定场景下的图像。
因此,采用BLIP2/LLava的二阶段训练,如果只利用红外数据,难以有很好的效果。
version 1.0:参考llava构造指令数据集
benchmark:video-llava
【待补充】
思路
【待】















 1523
1523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









