






Meta AI
概要
这篇论文《LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding》提出了一种名为LayerSkip的方法,旨在端到端的加速大型语言模型(LLMs)的推理过程。研究的背景在于尽管大型语言模型在众多应用中展现出卓越性能,但它们在部署时所需的高计算量和内存资源导致了显著的经济与能源成本。
LayerSkip方法包括两个核心部分:首先,在训练阶段应用层次dropout技术,其中较早层的dropout率较低,而较晚层的dropout率较高,并引入早期退出损失,使得所有Transformer层共享相同的出口点。这一策略旨在提升模型在早期层的推理准确性。其次,在推理阶段,该方法无需添加任何辅助层或模块即可提高早期退出层的准确度。此外,论文还介绍了一种新颖的自我推测解码方案,能够在早期层退出并利用模型剩余层进行验证和修正。这种方法相较于其他推测性解码方法具有更小的内存占用,并且能从草案和验证阶段的共享计算与激活中获益。
实验结果显示,在不同类型的训练(如从头预训练、持续预训练、特定数据领域上的微调以及针对特定任务的微调)以及不同规模的Llama模型上,LayerSkip能够显著提升推理速度,例如在CNN/DM文本摘要任务上达到2.16倍速度提升,在编程任务上达到1.82倍,在TOPv2语义解析任务上达到2.0倍。
综上所述,该研究通过结合层dropout和早期退出损失,辅以创新的自我推测解码策略,有效解决了大型语言模型推理效率的问题,为降低部署成本和环境影响提供了可行方案。
三个核心
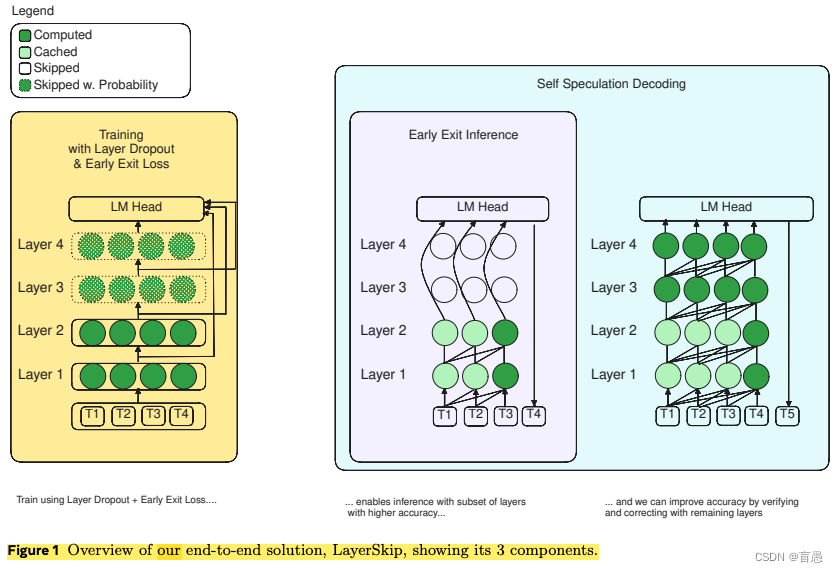
LayerSkip方法包含三个关键组件来实现大型语言模型的高效推理:
-
训练使用层dropout和早期退出损失:
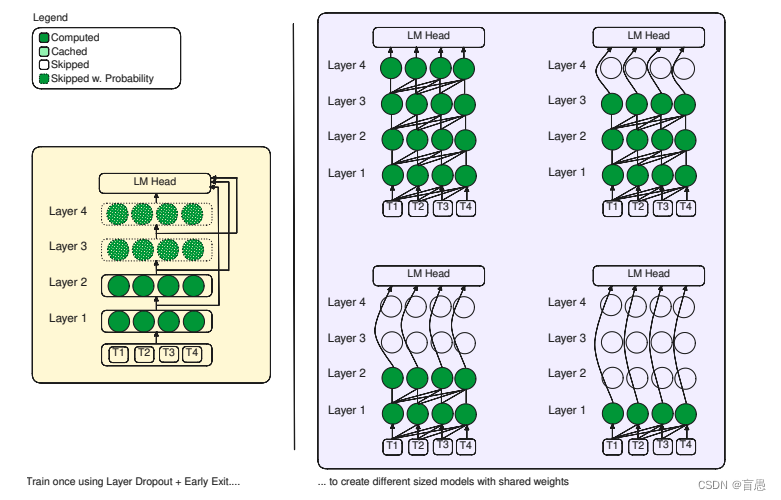
在训练过程中,LayerSkip引入了层dropout技术,这是一种改进的正则化手段。与传统dropout随机丢弃神经元不同,它依据层的位置动态调整dropout率,即对模型早期层施加较低的dropout率,而对后期层施加较高的dropout率。这样做的目的是鼓励模型在早期层学习更多通用特征,同时保持后期层的复杂性和多样性。此外,模型还被训练以支持早期退出,通过在所有Transformer层共享一个退出点并计算相应的损失(早期退出损失),促使模型即使在浅层也能够给出准确的预测。
-
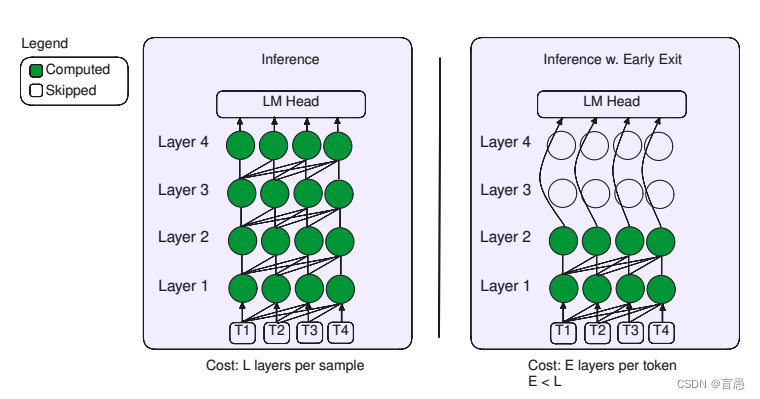
推理使用早期退出:
在推理阶段,由于模型在训练时已经适应了早期层的准确预测,因此可以直接在输入序列处理到某一层时作出决策并退出,而无需遍历所有层。这种机制减少了不必要的计算,加快了推理速度。重要的是,这种策略不依赖于额外的辅助层或模块,保持了模型架构的简洁性。
-
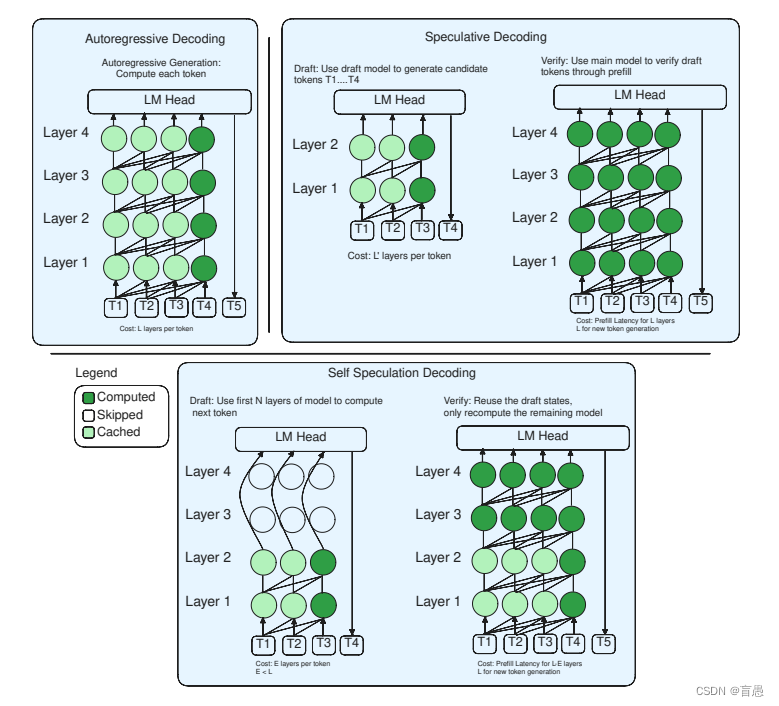
验证与修正的自我推测解码:
LayerSkip还包括一个创新的自我推测解码策略,它允许模型在早期层做出初步预测(草案),然后利用模型剩余的层对这些预测进行验证和必要时的修正。与以往的推测性解码方法相比,该策略能够重用草案阶段的激活和键值缓存(KV缓存),因为草案和修正阶段执行的是相同的早期层且顺序一致,从而减少内存消耗并提高计算效率。这与之前一些工作中的做法不同,那些工作可能需要跳过中间层,无法直接复用缓存资源。
这三个组件共同作用,既提高了模型在早期层的预测准确性,又显著加速了推理过程,同时保持了良好的资源利用率。LayerSkip方案通过在训练和推理两端的优化,为大型语言模型的快速、高效部署提供了一种综合解决方案。
实验部分
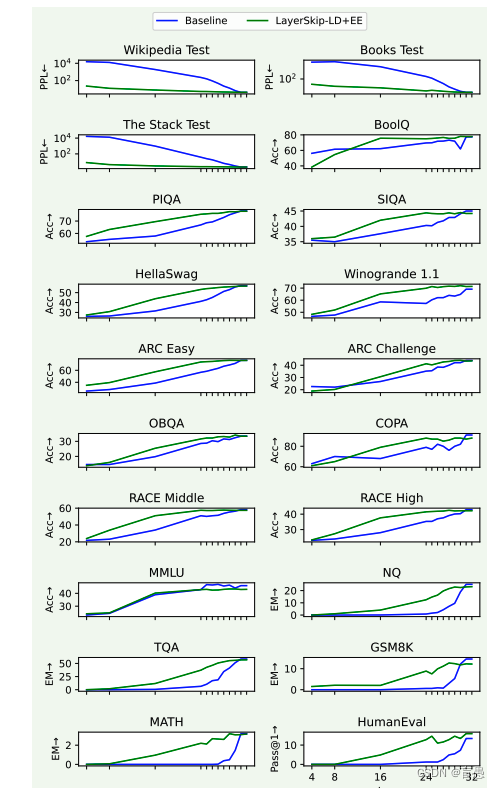
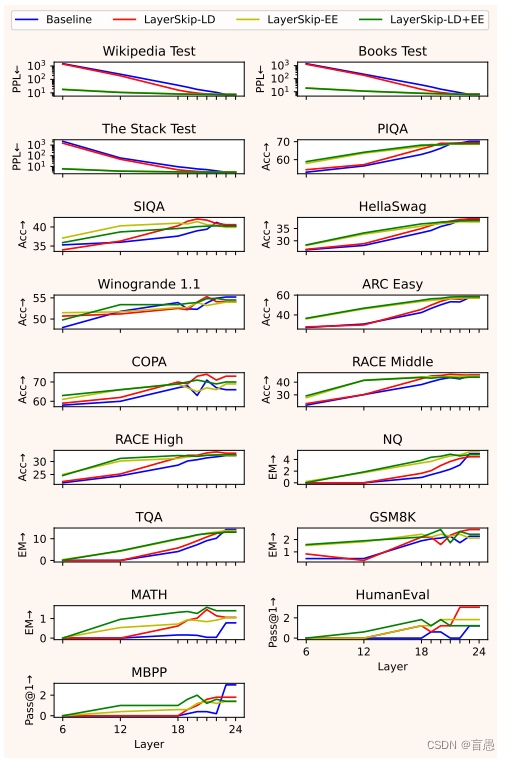
消融实验
局限性
这个提出的解码方法需要微调或者继续预训练模型,
参数影响巨大,但是调参成本高。

















 5719
5719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









