








这是NIPS2021的一篇论文。论文的主题是解决early exit失败的时候IC的运算被浪费掉的问题。
背景介绍
- early exit 是一个提高推理速度的研究方向。主要做法就是在网络的浅层特征上插入一些分支的分类器(Internal Classifier)。当以某个简单样本为输入的时候,如果其中某一层的分类器的置信度足够高,那么就无需继续前向传播到深层网络了,在此刻即可输出预测结果,从而加快推理了的速度。
- 但是,很明显 ,这样的做法存在缺陷,如果置信度不够高,主干网络需要继续前向传播,而前面IC的计算就是无效计算,被浪费掉了。
相关工作
- Yigitcan Kaya, Sanghyun Hong, and Tudor Dumitras. Shallow-deep networks: Understanding and mitigating network overthinking. In Proceedings of the International Conference on Machine Learning, ICML, pages 3301–3310, 2019.
- Wangchunshu Zhou, Canwen Xu, Tao Ge, Julian McAuley, Ke Xu, and Furu Wei. BERT loses patience: fast and robust inference with early exit. arXiv:2006.04152, 2020.
- Surat Teerapittayanon, Bradley McDanel, and Hsiang-Tsung Kung. Branchynet: Fast inference via early exiting from deep neural networks. In Proceedings of the International Conference on Pattern Recognition, ICPR, pages 2464–2469, 2016.
- Simone Scardapane, Michele Scarpiniti, Enzo Baccarelli, and Aurelio Uncini. Why should we add early exits to neural networks? arXiv:2004.12814, 2020.
- Konstantin Berestizshevsky and Guy Even. Dynamically sacrificing accuracy for reduced computation: cascaded inference based on softmax confidence. In Proceedings of the International Conference on Artificial Neural Networks, ICANN, pages 306–320. Springer, 2019.
正文
- 可以直接用一个训练好的不带 early exit 的模型,模型的参数fix,只训练往上面插入的ICs,所以其实有点类似即插即用的方法。
- 文章通过两个方式来重复利用前面的IC的计算:cascade connections 和 ensembling。网络结构如图所示
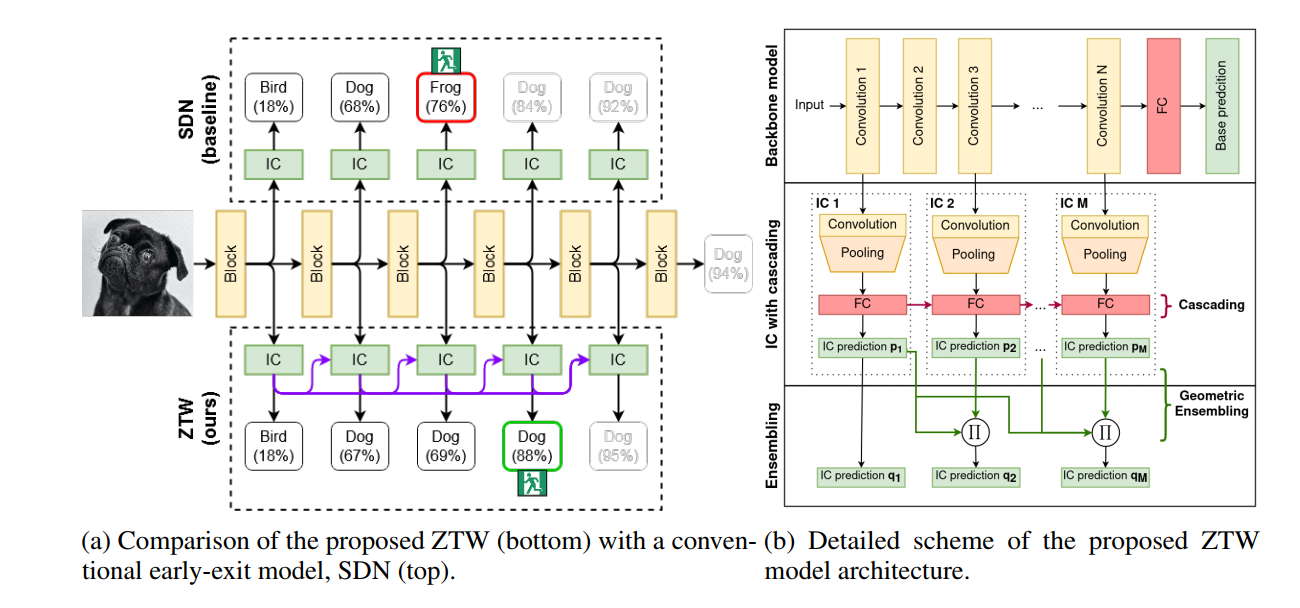
cascade connections
- 指的是上图右子图中的中间部分,即除了第一个IC外,每个IC的FC层的输入由前一个IC的FC层的输出和自身前面卷积层的输出拼接而成。这样的方式可以利用到前面IC的预测结果,从而实现没有浪费计算资源的目的(感觉很直观,不浪费就是在后面用上,用上的最简单方法就是concatenate到input中去,倒没有什么巧妙的感觉)
- 值得注意的是,文章指出,必须阻断梯度通过skip connection反向回传到前面的IC,否则性能会出现下降。这个我觉得倒挺重要的,通过这种回传得到的梯度是极其复杂的,受后面IC块预测值的影响,而前面IC块的预测结果本质上不应该受后面IC块预测结果的影响,学习也无法使得前面的IC块自动抵消这种影响,不如不要通过skip-connection 回传梯度,仅仅通过cross-entropy去训练每个IC块
ensembling
- ensemble其实指的是通过训练多个模型,融合多个模型的预测结果得到更加稳定的平均的预测结果这一trick。而既然ZTW模型自身已经能生成多个预测结果了,就可以直接对这些预测结果进行ensemble了。关键就是如何对这些从浅到深多个不同的预测结果进行合理的ensemble:
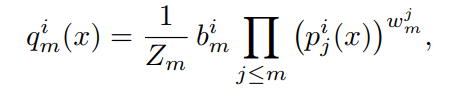
- 文章指出,使用几何平均比使用加权算术平均能够取得更好的效果。所以其实就是对多个IC的softmax输出做几何平均,几何平均的权重 w w w 是可学习的参数(文章指出可学习参数比人为定义取得了更好的效果);连乘外面的 b b b 是对不同类别的算数平均权重,也是可学习的参数; Z m Z_m Zm是归一化参数,使得某个IC的预测结果对各个类别的概率值加和为1
- 实际实现中,为了防止连乘下溢,将公式修改为如下形式:
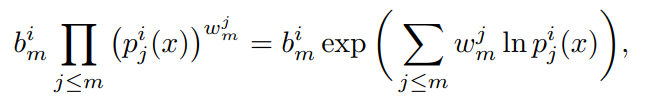
early exit 判断
- 简单的人为阈值判断:
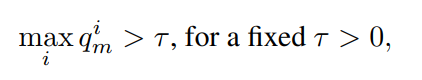
如果上述条件成立,那么不需要再继续前向传播,此时的IC的预测结果即为模型的预测结果。
实验结果
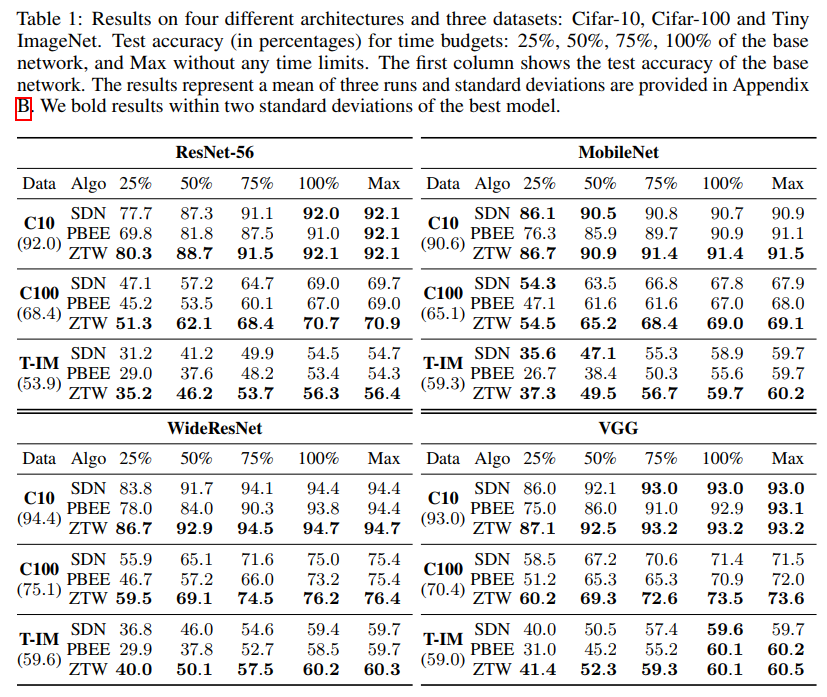
- 实验结果显示,模型在相当于原浮点计算量25% 50% 75%计算量的时候都取得了不太低的准确率,说明模型能够在大幅降低运算量的同时保持高水准的准确率。















 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









