










协同过滤的步骤是:
创建数据模型 —> 用户相似度算法 —>用户近邻算法 —>推荐算法。
基于用户的协同过滤算法在Mahout库中已经模块化了,通过4个模块进行统一的方法调用。首先,创建数据模型(DataModel),然后定义用户的相似度算法(UserSimilarity),接下来定义用户近邻算法(UserNeighborhood ),最后调用推荐算法(Recommender)完成计算过程。而基于物品的协同过滤算法(ItemCF)过程也是类似的,去掉第三步计算用户的近邻算法就行了。
软件环境:Win7 64位 + Eclipse4.4 +jdk1.6
使用Java语言,借用Mahout库里的API,实现基于用户的协同过滤算法,从而进行商品推荐。
1.数据集
//testCF.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0 该testCF.csv数据集中,第一列为用户号UserID,第二列为商品号ItemID,第三列为评分Preference Value.
2.借用Java里Mahout库,实现协同过滤算法。
//UserBased.java
package com.xie;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.file.*;
import org.apache.mahout.cf.taste.impl.neighborhood.*;
import org.apache.mahout.cf.taste.impl.recommender.*;
import org.apache.mahout.cf.taste.impl.similarity.*;
import org.apache.mahout.cf.taste.model.*;
import org.apache.mahout.cf.taste.recommender.*;
import org.apache.mahout.cf.taste.similarity.*;
import java.io.*;
import java.util.*;
public class UserBased {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws IOException, TasteException {
String file = "src/data/testCF.csv";
DataModel model = new FileDataModel(new File(file));
UserSimilarity user = new EuclideanDistanceSimilarity(model);
NearestNUserNeighborhood neighbor = new NearestNUserNeighborhood(NEIGHBORHOOD_NUM, user, model);
Recommender r = new GenericUserBasedRecommender(model, neighbor, user);
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List<RecommendedItem> list = r.recommend(uid, RECOMMENDER_NUM);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
} 效果如下:
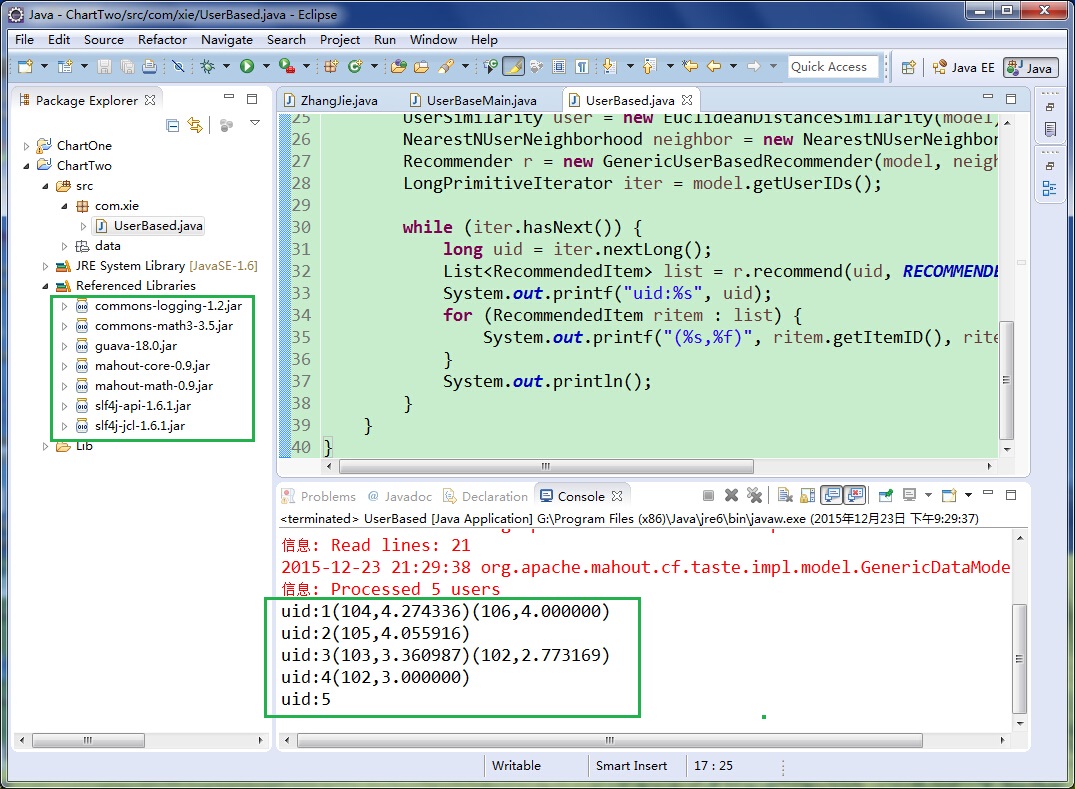
结果说明:
对于uid=1的用户,给他推荐计算得分最高的2个物品,104和106。
对于uid=2的用户,给他推荐计算得分最高的1个物品,105。
对于uid=3的用户,给他推荐计算得分最高的2个物品,103和102。
对于uid=4的用户,给他推荐计算得分最高的1个物品,102。
对于uid=5的用户,没有推荐。
用Java实现协同过滤的工程代码:
http://download.csdn.net/detail/sanqima/9374529
方法二:用R语言实现协同过滤算法
软件环境:win7 64位 + RStudio 0.99 + R3.2.3
//mahout1.R
# part1 -------------------------------------------------------------------
##加载arules包
library(arules)
##建立模型矩阵
FileDataModel <- function(file){
##读取CSV文件到内存
data <- read.csv(file,header = FALSE)
##增加列名
names(data) <- c("uid","iid","pref")
##计算用户数
user <- unique(data$uid)
##计算产品数
item <- unique(sort(data$iid))
uidx <- match(data$uid, user)
iidx <- match(data$iid, item)
##定义存储矩阵
M <- matrix(0, length(user),length(item))
i <- cbind(uidx, iidx, pref=data$pref)
##给矩阵赋值
for(n in 1:nrow(i)){
M[i[n,][1], i[n,][2]] <- i[n,][3]
}
dimnames(M)[[2]] <- item
##返回矩阵值
M
}
# part2 -------------------------------------------------------------------
##欧式距离相似度算法
EuclideanDistanceSimilarity <- function(M){
row <- nrow(M)
##相似度矩阵
s <- matrix(0,row,row)
for(z1 in 1:row){
for(z2 in 1:row){
if(z1 < z2){
##可计算的列
num <- intersect(which(M[z1,]!=0),which(M[z2,]!=0))
sum <- 0
for(z3 in num){
sum <- sum+(M[z1,][z3] - M[z2,][z3])^2
}
s[z2,z1] <- length(num)/(1+sqrt(sum))
##对算法的阈值进行限制
if(s[z2,z1] > 1) s[z2,z1] <- 1
if(s[z2,z1] < -1) s[z2,z1] <- -1
}
}
}
ts <- t(s) ##补全三角矩阵
w <- which(upper.tri(ts))
s[w] <- ts[w]
s ##返回用户相似度矩阵
}
# part3 -------------------------------------------------------------------
##用户近邻算法
NearestNUserNeigborhood <- function(S,n){
row <- nrow(S)
neighbor <- matrix(0,row,n)
for(z1 in 1:row){
for(z2 in 1:n){
m <- which.max(S[,z1])
neighbor[z1,][z2] <- m
S[,z1][m]=0
}
}
neighbor
}
# part4 -------------------------------------------------------------------
##推荐算法
UserBasedRecommender <- function(uid,n,M,S,N){
row <- ncol(N)
col <- ncol(M)
r <- matrix(0,row,col)
N1 <- N[uid,]
for(z1 in 1:length(N1)){
num <- intersect(which(M[uid,]==0),which(M[N1[z1],]!=0))
for(z2 in num){
r[z1,z2] = M[N1[z1],z2]*S[uid,N1[z1]]
}
}
##输出推荐矩阵
sum <- colSums(r)
s2 <- matrix(0,2,col)
for(z1 in 1:length(N1)){
num <- intersect(which(colSums(r)!=0),which(M[N1[z1],]!=0))
for(z2 in num){
s2[1,][z2] <- s2[1,][z2]+S[uid,N1[z1]]
s2[2,][z2] <- s2[2,][z2]+1
}
}
s2[,which(s2[2,]==1)]=10000
s2 <- s2[-2,]
r2 <- matrix(0,n,2)
rr <- sum/s2
item <- dimnames(M)[[2]]
for(z1 in 1:n){
w <- which.max(rr)
if(rr[w]>0.5){
r2[z1,1] <- item[which.max(rr)]
r2[z1,2] <- as.double(rr[w])
rr[w]=0
}
}
r2
}
# part5 -------------------------------------------------------------------
##调用算法
setwd("G:\\myProject\\RDoc\\Unit2\\rChap2")
myFile <- "testCF.csv"
NeighborHodd_num <- 2 ##取两个最大近邻
Recommender_num <- 3 ##保留最多3个推荐结果
myM <- FileDataModel(myFile)
myS <- EuclideanDistanceSimilarity(myM)
myN <- NearestNUserNeigborhood(myS,NeighborHodd_num)
##对用户user= 1的推荐结果
R1 <- UserBasedRecommender(1, Recommender_num,myM,myS,myN); R1
##对用户user= 2的推荐结果
R2 <- UserBasedRecommender(2, Recommender_num,myM,myS,myN); R2
##对用户user= 3的推荐结果
R3 <- UserBasedRecommender(3, Recommender_num,myM,myS,myN); R3
##对用户user= 4的推荐结果
R4 <- UserBasedRecommender(4, Recommender_num,myM,myS,myN); R4
##对用户user= 5的推荐结果
R5 <- UserBasedRecommender(5, Recommender_num,myM,myS,myN); R5
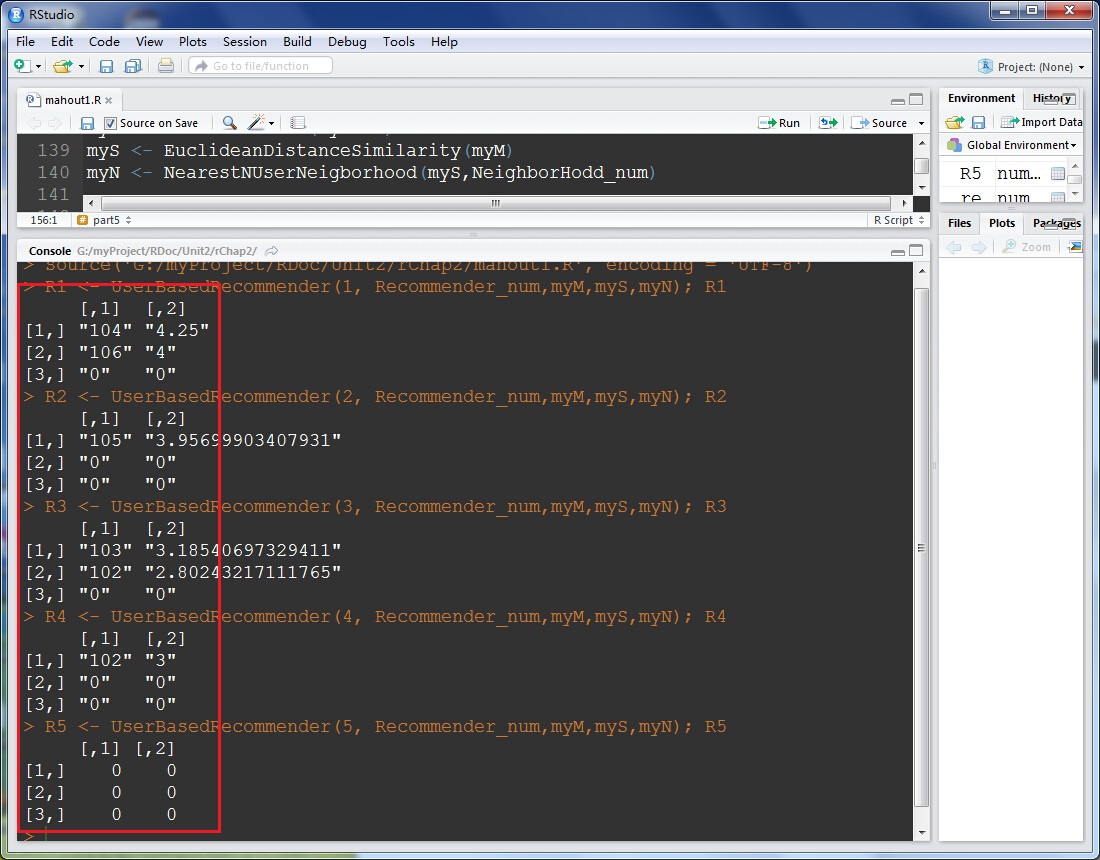
效果如下:
















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











