









本文要解决的问题:
通过Spark源码学习,进一步深入了解Shuffle过程。
Shuffle 介绍
在Map和Reduce之间的过程就是Shuffle,Shuffle的性能直接影响整个Spark的性能。所以Shuffle至关重要。
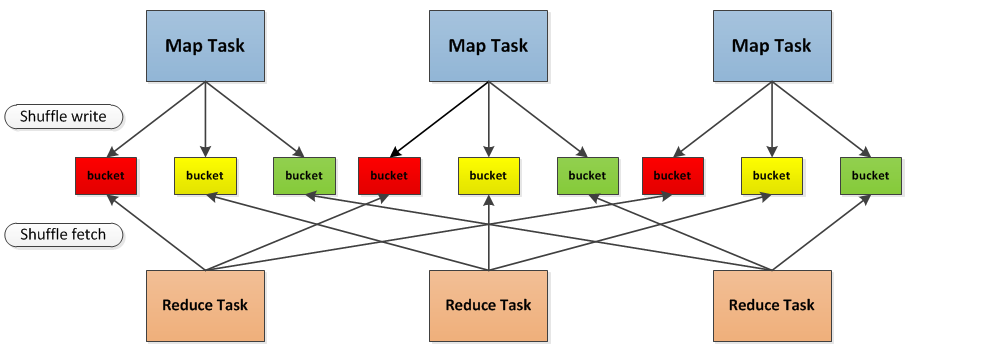
从图中得知,Map输出的结构产生在bucket中。而bucket的数量是map*reduce的个数。这里的每一个bucket都对应一个文件。Map对bucket书是写入数据,而reduce是对bucket是抓取数据也就是读的过程。
ShuffleManager
ShuffleManager中有五个方法:
registerShuffleShuffle:注册
getWriter:获得写数据的对象
getReader:获得读取数据的对象
unregisterShuffle:移除元数据
Stop :停止ShuffleManager
Shuffle Write
Shuffle写的过程需要落到磁盘。在参数consolidateShuffleFiles中可以配置。
如果consolidateShuffleFiles为true写文件,为false在completedMapTasks中添加mapId。
接下来看下recycleFileGroup这个方法。参数ShuffleFileGroup是一组shuffle文件,每一个特定的map都会分配一组ShuffleFileGroup写入文件。
SortShuffleManager中的读取对象调用了HashShuffleReader
源码中的ShuffleState是记录shuffle的一个特定状态。
ShuffleWrite有两个子类:
private[spark] abstract class ShuffleWriter[K, V] {
/** Write a sequence of records to this task's output */
@throws[IOException]
def write(records: Iterator[Product2[K, V]]): Unit
/** Close this writer, passing along whether the map completed */
def stop(success: Boolean): Option[MapStatus]
}SortShuffleWriter的write方法:
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
}ShuffleReader
HashShuffleReader
override def read(): Iterator[Product2[K, C]] = {
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024,
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue))
// Wrap the streams for compression based on configuration
val wrappedStreams = blockFetcherItr.map { case (blockId, inputStream) =>
serializerManager.wrapForCompression(blockId, inputStream)
}
val serializerInstance = dep.serializer.newInstance()
// Create a key/value iterator for each stream
val recordIter = wrappedStreams.flatMap { wrappedStream =>
// Note: the asKeyValueIterator below wraps a key/value iterator inside of a
// NextIterator. The NextIterator makes sure that close() is called on the
// underlying InputStream when all records have been read.
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
// Update the context task metrics for each record read.
val readMetrics = context.taskMetrics.createTempShuffleReadMetrics()
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// An interruptible iterator must be used here in order to support task cancellation
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) {
// We are reading values that are already combined
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else {
// We don't know the value type, but also don't care -- the dependency *should*
// have made sure its compatible w/ this aggregator, which will convert the value
// type to the combined type C
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
} else {
require(!dep.mapSideCombine, "Map-side combine without Aggregator specified!")
interruptibleIter.asInstanceOf[Iterator[Product2[K, C]]]
}SortShuffleManager中的读取对象调用了HashShuffleReader
override def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C] = {
new BlockStoreShuffleReader(
handle.asInstanceOf[BaseShuffleHandle[K, _, C]], startPartition, endPartition, context)
}Shuffle partition
在RDD API中当调用reduceByKey等类似的操作,则会产生Shuffle了。

根据不同的业务场景,reduce的个数一般由程序猿自己设置大小。可通过“spark.default.par allelism”参数设置。
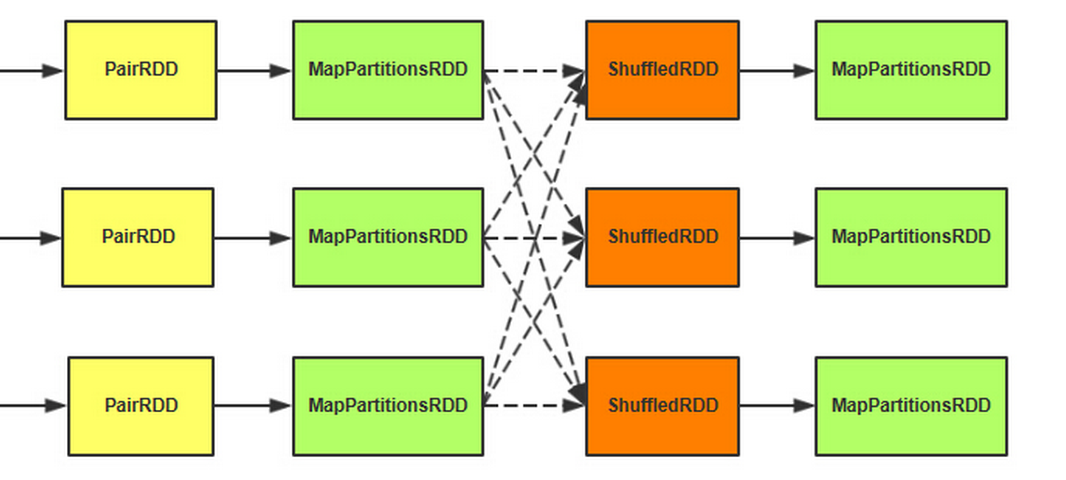
1、在第一个MapPartitionsRDD这里先做一次map端的聚合操作。
2、ShuffledRDD主要是做从这个抓取数据的工作。
3、第二个MapPartitionsRDD把抓取过来的数据再次进行聚合操作。
4、步骤1和步骤3都会涉及到spill的过程。
在作业提交的时候,DAGSchuduler会把Shuffle的成过程切分成map和reduce两个部分。每个部分的任务聚合成一个stage。
Shuffle在map端的时候通过ShuffleMapTask的runTask方法运行Task。
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
//使用广播变量反序列化RDD
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}ShuffleMapTask结束之后,最后走到DAGScheduler的handleTaskCompletion方法当中源码如下:
以下截取handleTaskCompletion方法的一部分源码。
case smt: ShuffleMapTask =>
val shuffleStage = stage.asInstanceOf[ShuffleMapStage]
updateAccumulators(event)
val status = event.result.asInstanceOf[MapStatus]
val execId = status.location.executorId
logDebug("ShuffleMapTask finished on " + execId)
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from executor $execId")
} else {
//把结果添加到OutputLoc数组里,他是按照数据的分区关系来存储数据的
shuffleStage.addOutputLoc(smt.partitionId, status)
}
if (runningStages.contains(shuffleStage) && shuffleStage.pendingPartitions.isEmpty) {
markStageAsFinished(shuffleStage)
logInfo("looking for newly runnable stages")
logInfo("running: " + runningStages)
logInfo("waiting: " + waitingStages)
logInfo("failed: " + failedStages)
// We supply true to increment the epoch number here in case this is a
// recomputation of the map outputs. In that case, some nodes may have cached
// locations with holes (from when we detected the error) and will need the
// epoch incremented to refetch them.
// TODO: Only increment the epoch number if this is not the first time
// we registered these map outputs.
mapOutputTracker.registerMapOutputs(
shuffleStage.shuffleDep.shuffleId,
shuffleStage.outputLocInMapOutputTrackerFormat(),
changeEpoch = true)
clearCacheLocs()
if (!shuffleStage.isAvailable) {
// Some tasks had failed; let's resubmit this shuffleStage
// TODO: Lower-level scheduler should also deal with this
logInfo("Resubmitting " + shuffleStage + " (" + shuffleStage.name +
") because some of its tasks had failed: " +
shuffleStage.findMissingPartitions().mkString(", "))
submitStage(shuffleStage)
} else {
// Mark any map-stage jobs waiting on this stage as finished
if (shuffleStage.mapStageJobs.nonEmpty) {
val stats = mapOutputTracker.getStatistics(shuffleStage.shuffleDep)
for (job <- shuffleStage.mapStageJobs) {
markMapStageJobAsFinished(job, stats)
}
}
submitWaitingChildStages(shuffleStage)
}
}
}这部分由于时间仓促,后续会完善补充。















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









