







DETR:End-to-End Object Detection with Transformers
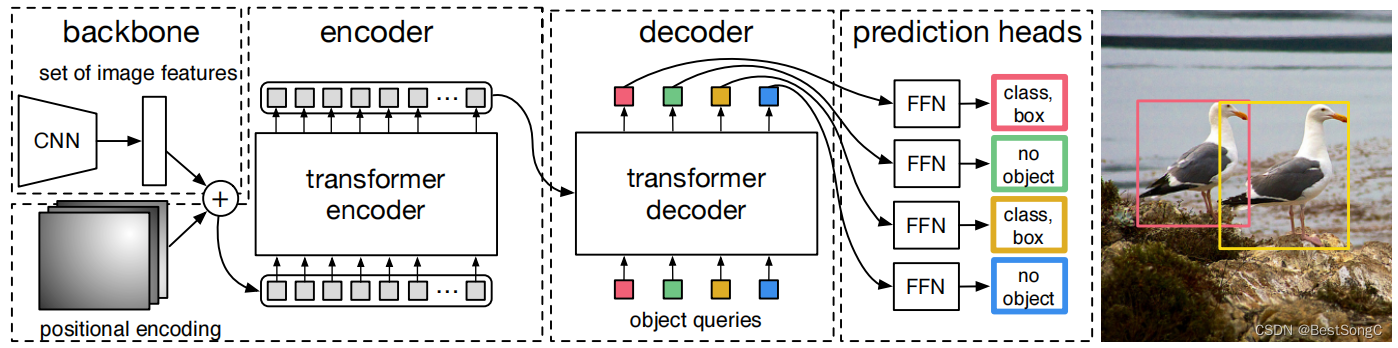
- Encoder:Transformer encoder
- Decoder:Transformer decoder
- GT与预测Queries匹配:匈牙利匹配算法
- 损失计算:分类 + L1边框回归 + GIoU边框回归
- 源码地址:https://github.com/facebookresearch/detr
1. 训练参数配置
parser = argparse.ArgumentParser('Set transformer detector', add_help=False)
parser.add_argument('--lr', default=1e-4, type=float)
parser.add_argument('--lr_backbone', default=1e-5, type=float)
parser.add_argument('--batch_size', default=5, type=int)
parser.add_argument('--weight_decay', default=1e-4, type=float)
parser.add_argument('--epochs', default=300, type=int)
parser.add_argument('--lr_drop', default=200, type=int)
parser.add_argument('--clip_max_norm', default=0.1, type=float,
help='gradient clipping max norm')
# Model parameters
parser.add_argument('--frozen_weights', type=str, default=None,
help="Path to the pretrained model. If set, only the mask head will be trained")
# * Backbone
parser.add_argument('--backbone', default='resnet50', type=str,
help="Name of the convolutional backbone to use")
parser.add_argument('--dilation', action='store_true',
help="If true, we replace stride with dilation in the last convolutional block (DC5)")
parser.add_argument('--position_embedding', default='sine', type=str, choices=('sine', 'learned'),
help="Type of positional embedding to use on top of the image features")
# * Transformer
parser.add_argument('--enc_layers', default=6, type=int,
help="Number of encoding layers in the transformer")
parser.add_argument('--dec_layers', default=6, type=int,
help="Number of decoding layers in the transformer")
parser.add_argument('--dim_feedforward', default=2048, type=int,
help="Intermediate size of the feedforward layers in the transformer blocks")
parser.add_argument('--hidden_dim', default=256, type=int,
help="Size of the embeddings (dimension of the transformer)")
parser.add_argument('--dropout', default=0.1, type=float,
help="Dropout applied in the transformer")
parser.add_argument('--nheads', default=8, type=int,
help="Number of attention heads inside the transformer's attentions")
parser.add_argument('--num_queries', default=100, type=int,
help="Number of query slots")
parser.add_argument('--pre_norm', action='store_true')
# * Segmentation
parser.add_argument('--masks', action='store_true',
help="Train segmentation head if the flag is provided")
# Loss
parser.add_argument('--no_aux_loss', dest='aux_loss', action='store_false',
help="Disables auxiliary decoding losses (loss at each layer)")
# * Matcher
parser.add_argument('--set_cost_class', default=1, type=float,
help="Class coefficient in the matching cost")
parser.add_argument('--set_cost_bbox', default=5, type=float,
help="L1 box coefficient in the matching cost")
parser.add_argument('--set_cost_giou', default=2, type=float,
help="giou box coefficient in the matching cost")
# * Loss coefficients
parser.add_argument('--mask_loss_coef', default=1, type=float)
parser.add_argument('--dice_loss_coef', default=1, type=float)
parser.add_argument('--bbox_loss_coef', default=5, type=float)
parser.add_argument('--giou_loss_coef', default=2, type=float)
parser.add_argument('--eos_coef', default=0.1, type=float,
help="Relative classification weight of the no-object class")
# dataset parameters
parser.add_argument('--dataset_file', default='coco')
parser.add_argument('--coco_path', default='/home/enbo/sc/Public_dataset/coco2017', type=str)
parser.add_argument('--coco_panoptic_path', type=str)
parser.add_argument('--remove_difficult', action='store_true')
parser.add_argument('--output_dir', default='train',
help='path where to save, empty for no saving')
parser.add_argument('--device', default='cuda',
help='device to use for training / testing')
parser.add_argument('--seed', default=42, type=int)
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start_epoch', default=0, type=int, metavar='N',
help='start epoch')
parser.add_argument('--eval', action='store_true')
parser.add_argument('--num_workers', default=2, type=int)
# distributed training parameters
parser.add_argument('--world_size', default=1, type=int,
help='number of distributed processes')
parser.add_argument('--dist_url', default='env://', help='url used to set up distributed training')
本文重要参数配置:
- batch_size: 5
- backbone: resnet50
- position_embedding: sine
- dec_layers: 6
- hidden_dim: 256
- num_queries: 100
- 匹配系数:set_cost_class:1 set_cost_bbox:5 set_cost_giou:2
- 损失系数:dice_loss_coef:1 bbox_loss_coef:5 giou_loss_coef:2 eos_coef:0.1















 2655
2655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









