







支持向量机(svm)是一种二分类模型,目标是寻找一个标准(超平面)对样本数据进行分割,分割的原则是确保分类最优化(类别之间的间隔最大)。 它在分类时,把无法线性分割的数据映射到高维空间,然后在高维空间找到分类最优的线性分类器。当数据集较小时,使用支持向量机非常有效,它是最好的现成(不加修改即可直接使用)分类器之一。
一:理论

如上图所示,划分不同数据类型的直线即是分类器。

在已有数据中,找到离分类器最近的点,确保它们离分类器尽可能的远,而这些点到分类器的距离成为间隔,我们希望间隔尽可能的大,这样的分类器在处理数据时就会更加准确。离分类器最近的那些点叫作支持向量,正是这些支持向量决定了分类器所在的位置。
在实际中的大多数问题往往是比较复杂的,不可能像上图那样简单的完成划分,支持向量机将不那么容易分类的数据通过函数映射变为可分类的。它在处理数据时,如果在低维空间内无法完成分类,就会自动将数据映射到高维空间,使其变为(线性)可分。在低维到高维转换的过程中,支持向量机通过使用核函数有效降低计算复杂度。
二:SVM案例介绍
在使用支持向量机模块时,需要先使用函数cv2.ml.SVM_create()生成用于后续训练的空分类器模型,
svm=cv2.ml.SVM_create()
获得空模型后,针对该模型使用svm.train()函数对训练数据进行训练
result=svm.train(data,flage,label)
data:训练数据,用于训练分类
flage:训练数据排列格式,cv2.ml.ROW_SAMPLE表示按行排列,cv2.ml.COL_SAMPLE表示按列排列,使用时按照实际排列情况选择对应的参数即可。
label:原始数据的标签
result:训练结果的返回值
完成训练后,使用svm.predict()函数即可用训练好的模型对测试数据进行分类。
(返回值,返回结果)=svm.predict(test)
以上是支持向量机模块的基本使用方法,在实际使用时可以根据需要对其中的参数进行调整,如”通过svm.setType()函数设置svm类别,svm.setKernel()函数设置核函数类别,svm.setC()设置支持向量机的惩罚系数(对误差的容忍度,默认为0)
import cv2
import numpy as np
import matplotlib.pyplot as plt
#随机生成并合并训练数据
a=np.random.randint(95,100,(20,2)).astype(np.float32)
b=np.random.randint(90,95,(20,2)).astype(np.float32)
data=np.vstack((a,b))
data=np.array(data,dtype="float32")
#建立并合并标签
alabel=np.zeros((20,1))
blabel=np.ones((20,1))
label=np.vstack((alabel,blabel))
label=np.array(label,np.int32)
#创建svm
svm=cv2.ml.SVM_create()
#属性设置,直接采用默认即可
# svm.setType(cv2.ml.SVM_C_SVC)#svm type
# svm.setKernel(cv2.ml.SVM_LINEAR) #line
# svm.setC(0.01)
#训练
result=svm.train(data,cv2.ml.ROW_SAMPLE,label)
#测试
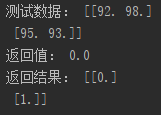
test=np.vstack([[92,98],[95,93]])
test=np.array(test,dtype=np.float32)
(p1,p2)=svm.predict(test)
plt.scatter(a[:,0],a[:,1],80,"g","o")
plt.scatter(b[:,0],b[:,1],80,"b","s")
plt.scatter(test[:,0],test[:,1],80,"r","*")
print("测试数据:",test)
print("返回值:",p1)
print("返回结果:",p2)
plt.show()















 1816
1816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









