







RDD、Shuffle、Broadcast均使用了Spark的存储子系统
1,Spark存储子系统的组成
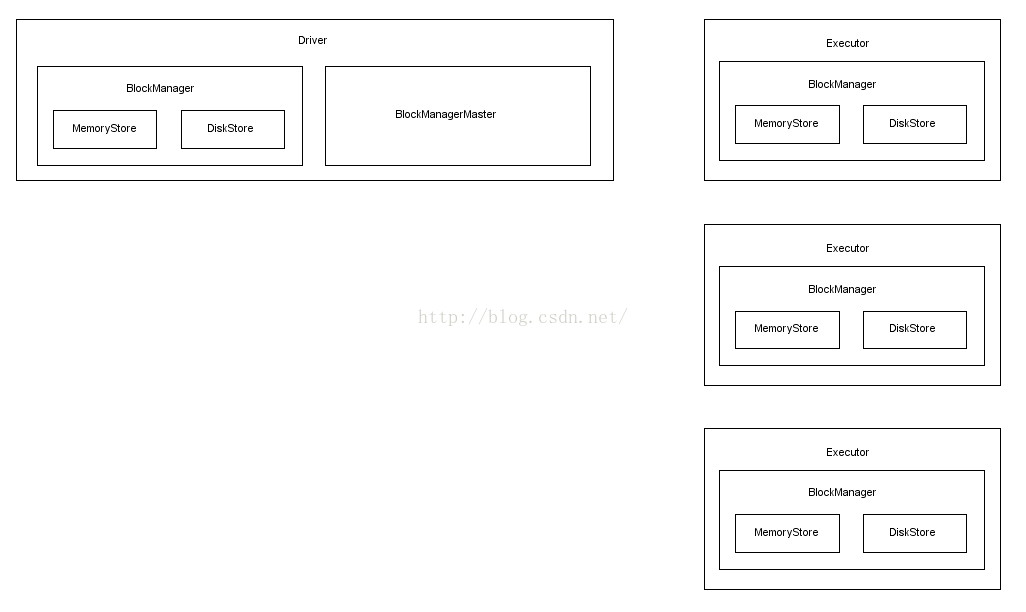
Spark的存储子系统也是一个Master-Slave架构,由BlockManagerMaster和BlockManager组成(这是到目前为止在Spark内发现的第三个Master-Slave架构,另外两个分别为:Standalone模式的Master-Worker,App执行过程中的Driver-Executor,与上面两个不同的是存储子系统的BlockManagerMaster和BlockManager都并不是单独的进程,而是依托Driver和Executor存在)
Driver进程内同时拥有BlockManagerMaster和BlockManager组件,而Executor进程内仅有BlockManager和一个BlockManagerMaster的EndpointRef
BlockManagerMaster和Blockmanager创建过程如下:
val blockTransferService = new NettyBlockTransferService(conf, securityManager, numUsableCores)
val blockManagerMaster = new BlockManagerMaster(registerOrLookupEndpoint(
BlockManagerMaster.DRIVER_ENDPOINT_NAME,
new BlockManagerMasterEndpoint(rpcEnv, isLocal, conf, listenerBus)),
conf, isDriver)
// NB: blockManager is not valid until initialize() is called later.
val blockManager = new BlockManager(executorId, rpcEnv, blockManagerMaster,
serializer, conf, memoryManager, mapOutputTracker, shuffleManager,
blockTransferService, securityManager, numUsableCores) def registerOrLookupEndpoint(
name: String, endpointCreator: => RpcEndpoint):
RpcEndpointRef = {
if (isDriver) {
logInfo("Registering " + name)
rpcEnv.setupEndpoint(name, endpointCreator)
} else {
RpcUtils.makeDriverRef(name, conf, rpcEnv)
}
}BlockManager内有两个重要的成员变量MemoryStore和DiskStore
private[spark] val memoryStore = new MemoryStore(this, memoryManager)
private[spark] val diskStore = new DiskStore(this, diskBlockManager) master.registerBlockManager(blockManagerId, maxMemory, slaveEndpoint) // Messages received from executors
case heartbeat @ Heartbeat(executorId, taskMetrics, blockManagerId) =>
if (scheduler != null) {
if (executorLastSeen.contains(executorId)) {
executorLastSeen(executorId) = clock.getTimeMillis()
eventLoopThread.submit(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
val unknownExecutor = !scheduler.executorHeartbeatReceived(
executorId, taskMetrics, blockManagerId)
val response = HeartbeatResponse(reregisterBlockManager = unknownExecutor)
context.reply(response)
}
})
} else {
// This may happen if we get an executor's in-flight heartbeat immediately
// after we just removed it. It's not really an error condition so we should
// not log warning here. Otherwise there may be a lot of noise especially if
// we explicitly remove executors (SPARK-4134).
logDebug(s"Received heartbeat from unknown executor $executorId")
context.reply(HeartbeatResponse(reregisterBlockManager = true))
}
} else {
// Because Executor will sleep several seconds before sending the first "Heartbeat", this
// case rarely happens. However, if it really happens, log it and ask the executor to
// register itself again.
logWarning(s"Dropping $heartbeat because TaskScheduler is not ready yet")
context.reply(HeartbeatResponse(reregisterBlockManager = true))
}
2,存储模块的写入和读取过程
1)数据写入过程
数据的写入通过调用BlockManager的putIterator(), putArray() 和putBytes()三个方法存储数据,需要传入StorageLevel
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(false, false, true, false) /**
* Put the given block according to the given level in one of the block stores, replicating
* the values if necessary.
*
* The effective storage level refers to the level according to which the block will actually be
* handled. This allows the caller to specify an alternate behavior of doPut while preserving
* the original level specified by the user.
*/
private def doPut(
blockId: BlockId,
data: BlockValues,
level: StorageLevel,
tellMaster: Boolean = true,
effectiveStorageLevel: Option[StorageLevel] = None)
: Seq[(BlockId, BlockStatus)] = {
require(blockId != null, "BlockId is null")
require(level != null && level.isValid, "StorageLevel is null or invalid")
effectiveStorageLevel.foreach { level =>
require(level != null && level.isValid, "Effective StorageLevel is null or invalid")
}
// Return value
val updatedBlocks = new ArrayBuffer[(BlockId, BlockStatus)]
/* Remember the block's storage level so that we can correctly drop it to disk if it needs
* to be dropped right after it got put into memory. Note, however, that other threads will
* not be able to get() this block until we call markReady on its BlockInfo. */
val putBlockInfo = {
val tinfo = new BlockInfo(level, tellMaster)
// Do atomically !
val oldBlockOpt = blockInfo.putIfAbsent(blockId, tinfo)
if (oldBlockOpt.isDefined) {
if (oldBlockOpt.get.waitForReady()) {
logWarning(s"Block $blockId already exists on this machine; not re-adding it")
return updatedBlocks
}
// TODO: So the block info exists - but previous attempt to load it (?) failed.
// What do we do now ? Retry on it ?
oldBlockOpt.get
} else {
tinfo
}
}
val startTimeMs = System.currentTimeMillis
/* If we're storing values and we need to replicate the data, we'll want access to the values,
* but because our put will read the whole iterator, there will be no values left. For the
* case where the put serializes data, we'll remember the bytes, above; but for the case where
* it doesn't, such as deserialized storage, let's rely on the put returning an Iterator. */
var valuesAfterPut: Iterator[Any] = null
// Ditto for the bytes after the put
var bytesAfterPut: ByteBuffer = null
// Size of the block in bytes
var size = 0L
// The level we actually use to put the block
val putLevel = effectiveStorageLevel.getOrElse(level)
// If we're storing bytes, then initiate the replication before storing them locally.
// This is faster as data is already serialized and ready to send.
val replicationFuture = data match {
case b: ByteBufferValues if putLevel.replication > 1 =>
// Duplicate doesn't copy the bytes, but just creates a wrapper
val bufferView = b.buffer.duplicate()
Future {
// This is a blocking action and should run in futureExecutionContext which is a cached
// thread pool
replicate(blockId, bufferView, putLevel)
}(futureExecutionContext)
case _ => null
}
putBlockInfo.synchronized {
logTrace("Put for block %s took %s to get into synchronized block"
.format(blockId, Utils.getUsedTimeMs(startTimeMs)))
var marked = false
try {
// returnValues - Whether to return the values put
// blockStore - The type of storage to put these values into
val (returnValues, blockStore: BlockStore) = {
if (putLevel.useMemory) {
// Put it in memory first, even if it also has useDisk set to true;
// We will drop it to disk later if the memory store can't hold it.
(true, memoryStore)
} else if (putLevel.useOffHeap) {
// Use external block store
(false, externalBlockStore)
} else if (putLevel.useDisk) {
// Don't get back the bytes from put unless we replicate them
(putLevel.replication > 1, diskStore)
} else {
assert(putLevel == StorageLevel.NONE)
throw new BlockException(
blockId, s"Attempted to put block $blockId without specifying storage level!")
}
}
// Actually put the values
val result = data match {
case IteratorValues(iterator) =>
blockStore.putIterator(blockId, iterator, putLevel, returnValues)
case ArrayValues(array) =>
blockStore.putArray(blockId, array, putLevel, returnValues)
case ByteBufferValues(bytes) =>
bytes.rewind()
blockStore.putBytes(blockId, bytes, putLevel)
}
size = result.size
result.data match {
case Left (newIterator) if putLevel.useMemory => valuesAfterPut = newIterator
case Right (newBytes) => bytesAfterPut = newBytes
case _ =>
}
// Keep track of which blocks are dropped from memory
if (putLevel.useMemory) {
result.droppedBlocks.foreach { updatedBlocks += _ }
}
val putBlockStatus = getCurrentBlockStatus(blockId, putBlockInfo)
if (putBlockStatus.storageLevel != StorageLevel.NONE) {
// Now that the block is in either the memory, externalBlockStore, or disk store,
// let other threads read it, and tell the master about it.
marked = true
putBlockInfo.markReady(size)
if (tellMaster) {
reportBlockStatus(blockId, putBlockInfo, putBlockStatus)
}
updatedBlocks += ((blockId, putBlockStatus))
}
} finally {
// If we failed in putting the block to memory/disk, notify other possible readers
// that it has failed, and then remove it from the block info map.
if (!marked) {
// Note that the remove must happen before markFailure otherwise another thread
// could've inserted a new BlockInfo before we remove it.
blockInfo.remove(blockId)
putBlockInfo.markFailure()
logWarning(s"Putting block $blockId failed")
}
}
}
logDebug("Put block %s locally took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))
// Either we're storing bytes and we asynchronously started replication, or we're storing
// values and need to serialize and replicate them now:
if (putLevel.replication > 1) {
data match {
case ByteBufferValues(bytes) =>
if (replicationFuture != null) {
Await.ready(replicationFuture, Duration.Inf)
}
case _ =>
val remoteStartTime = System.currentTimeMillis
// Serialize the block if not already done
if (bytesAfterPut == null) {
if (valuesAfterPut == null) {
throw new SparkException(
"Underlying put returned neither an Iterator nor bytes! This shouldn't happen.")
}
bytesAfterPut = dataSerialize(blockId, valuesAfterPut)
}
replicate(blockId, bytesAfterPut, putLevel)
logDebug("Put block %s remotely took %s"
.format(blockId, Utils.getUsedTimeMs(remoteStartTime)))
}
}
BlockManager.dispose(bytesAfterPut)
if (putLevel.replication > 1) {
logDebug("Putting block %s with replication took %s"
.format(blockId, Utils.getUsedTimeMs(startTimeMs)))
} else {
logDebug("Putting block %s without replication took %s"
.format(blockId, Utils.getUsedTimeMs(startTimeMs)))
}
updatedBlocks
}首先,根据putLevel获取到BlockStore
val (returnValues, blockStore: BlockStore) = {
if (putLevel.useMemory) {
// Put it in memory first, even if it also has useDisk set to true;
// We will drop it to disk later if the memory store can't hold it.
(true, memoryStore)
} else if (putLevel.useOffHeap) {
// Use external block store
(false, externalBlockStore)
} else if (putLevel.useDisk) {
// Don't get back the bytes from put unless we replicate them
(putLevel.replication > 1, diskStore)
} else {
assert(putLevel == StorageLevel.NONE)
throw new BlockException(
blockId, s"Attempted to put block $blockId without specifying storage level!")
}
}<span style="white-space:pre"> </span>这里主要看一下ExternalBlockStore
externalBlockManager.get.putBytes(blockId, byteBuffer)在确定了BlockStore之后就开始真正Put数据了
// Actually put the values
val result = data match {
case IteratorValues(iterator) =>
blockStore.putIterator(blockId, iterator, putLevel, returnValues)
case ArrayValues(array) =>
blockStore.putArray(blockId, array, putLevel, returnValues)
case ByteBufferValues(bytes) =>
bytes.rewind()
blockStore.putBytes(blockId, bytes, putLevel)
}DiskStore.putBytes()过程相对简单,从DiskBlockManager获取路径,然后打开流写入即可
val file = diskManager.getFile(blockId)
val channel = new FileOutputStream(file).getChannel
Utils.tryWithSafeFinally {
while (bytes.remaining > 0) {
channel.write(bytes)
}
} {
channel.close()
} // We acquired enough memory for the block, so go ahead and put it
val entry = new MemoryEntry(value(), size, deserialized)
entries.synchronized {
entries.put(blockId, entry)
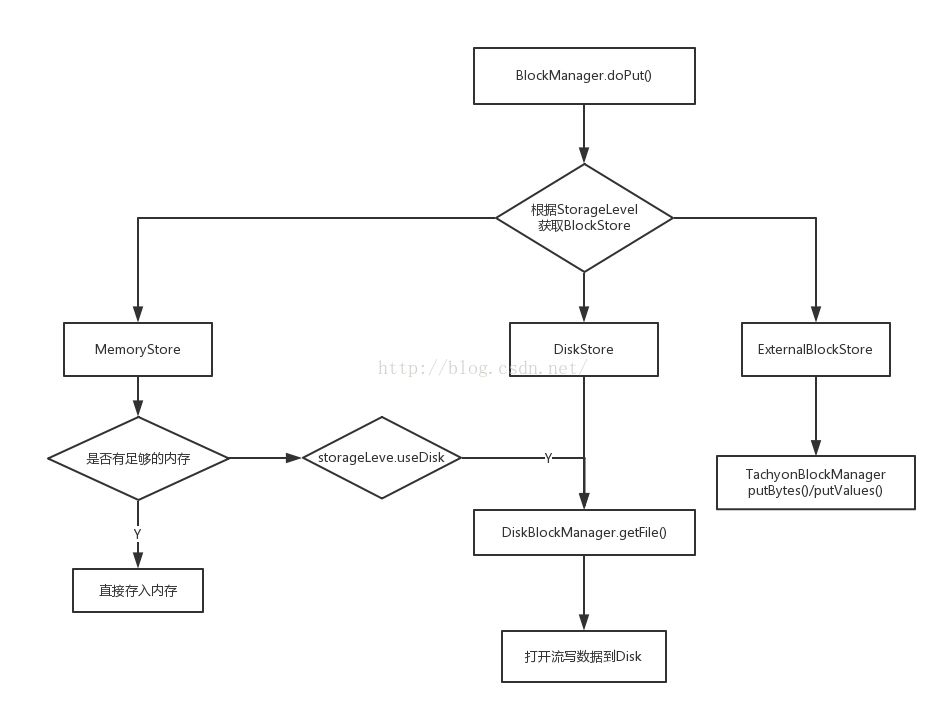
}下图是BlockManager存储的逻辑过程:
除了在本地存储,如果replication > 1 则需要存储一份在Remote端:
/**
* Replicate block to another node. Not that this is a blocking call that returns after
* the block has been replicated.
*/
private def replicate(blockId: BlockId, data: ByteBuffer, level: StorageLevel): Unit = {
val maxReplicationFailures = conf.getInt("spark.storage.maxReplicationFailures", 1)
val numPeersToReplicateTo = level.replication - 1
val peersForReplication = new ArrayBuffer[BlockManagerId]
val peersReplicatedTo = new ArrayBuffer[BlockManagerId]
val peersFailedToReplicateTo = new ArrayBuffer[BlockManagerId]
val tLevel = StorageLevel(
level.useDisk, level.useMemory, level.useOffHeap, level.deserialized, 1)
val startTime = System.currentTimeMillis
val random = new Random(blockId.hashCode)
var replicationFailed = false
var failures = 0
var done = false
// Get cached list of peers
peersForReplication ++= getPeers(forceFetch = false)
// Get a random peer. Note that this selection of a peer is deterministic on the block id.
// So assuming the list of peers does not change and no replication failures,
// if there are multiple attempts in the same node to replicate the same block,
// the same set of peers will be selected.
def getRandomPeer(): Option[BlockManagerId] = {
// If replication had failed, then force update the cached list of peers and remove the peers
// that have been already used
if (replicationFailed) {
peersForReplication.clear()
peersForReplication ++= getPeers(forceFetch = true)
peersForReplication --= peersReplicatedTo
peersForReplication --= peersFailedToReplicateTo
}
if (!peersForReplication.isEmpty) {
Some(peersForReplication(random.nextInt(peersForReplication.size)))
} else {
None
}
}
// One by one choose a random peer and try uploading the block to it
// If replication fails (e.g., target peer is down), force the list of cached peers
// to be re-fetched from driver and then pick another random peer for replication. Also
// temporarily black list the peer for which replication failed.
//
// This selection of a peer and replication is continued in a loop until one of the
// following 3 conditions is fulfilled:
// (i) specified number of peers have been replicated to
// (ii) too many failures in replicating to peers
// (iii) no peer left to replicate to
//
while (!done) {
getRandomPeer() match {
case Some(peer) =>
try {
val onePeerStartTime = System.currentTimeMillis
data.rewind()
logTrace(s"Trying to replicate $blockId of ${data.limit()} bytes to $peer")
blockTransferService.uploadBlockSync(
peer.host, peer.port, peer.executorId, blockId, new NioManagedBuffer(data), tLevel)
logTrace(s"Replicated $blockId of ${data.limit()} bytes to $peer in %s ms"
.format(System.currentTimeMillis - onePeerStartTime))
peersReplicatedTo += peer
peersForReplication -= peer
replicationFailed = false
if (peersReplicatedTo.size == numPeersToReplicateTo) {
done = true // specified number of peers have been replicated to
}
} catch {
case e: Exception =>
logWarning(s"Failed to replicate $blockId to $peer, failure #$failures", e)
failures += 1
replicationFailed = true
peersFailedToReplicateTo += peer
if (failures > maxReplicationFailures) { // too many failures in replcating to peers
done = true
}
}
case None => // no peer left to replicate to
done = true
}
}
val timeTakeMs = (System.currentTimeMillis - startTime)
logDebug(s"Replicating $blockId of ${data.limit()} bytes to " +
s"${peersReplicatedTo.size} peer(s) took $timeTakeMs ms")
if (peersReplicatedTo.size < numPeersToReplicateTo) {
logWarning(s"Block $blockId replicated to only " +
s"${peersReplicatedTo.size} peer(s) instead of $numPeersToReplicateTo peers")
}
} // Get cached list of peers
peersForReplication ++= getPeers(forceFetch = false) blockManagerIds.filterNot { _.isDriver }.filterNot { _ == blockManagerId }.toSeq blockTransferService.uploadBlockSync(
peer.host, peer.port, peer.executorId, blockId, new NioManagedBuffer(data), tLevel) if (peersReplicatedTo.size == numPeersToReplicateTo) {
done = true // specified number of peers have been replicated to
}
/**
* Get a block from the block manager (either local or remote).
*/
def get(blockId: BlockId): Option[BlockResult] = {
val local = getLocal(blockId)
if (local.isDefined) {
logInfo(s"Found block $blockId locally")
return local
}
val remote = getRemote(blockId)
if (remote.isDefined) {
logInfo(s"Found block $blockId remotely")
return remote
}
None
}和写入过程对应,从本地获取的过程中也是依次判断能否从Memory、ExternalBlockStore、Disk中读取
private def doGetLocal(blockId: BlockId, asBlockResult: Boolean): Option[Any] = {
val info = blockInfo.get(blockId).orNull
if (info != null) {
info.synchronized {
// Double check to make sure the block is still there. There is a small chance that the
// block has been removed by removeBlock (which also synchronizes on the blockInfo object).
// Note that this only checks metadata tracking. If user intentionally deleted the block
// on disk or from off heap storage without using removeBlock, this conditional check will
// still pass but eventually we will get an exception because we can't find the block.
if (blockInfo.get(blockId).isEmpty) {
logWarning(s"Block $blockId had been removed")
return None
}
// If another thread is writing the block, wait for it to become ready.
if (!info.waitForReady()) {
// If we get here, the block write failed.
logWarning(s"Block $blockId was marked as failure.")
return None
}
val level = info.level
logDebug(s"Level for block $blockId is $level")
// Look for the block in memory
if (level.useMemory) {
logDebug(s"Getting block $blockId from memory")
val result = if (asBlockResult) {
memoryStore.getValues(blockId).map(new BlockResult(_, DataReadMethod.Memory, info.size))
} else {
memoryStore.getBytes(blockId)
}
result match {
case Some(values) =>
return result
case None =>
logDebug(s"Block $blockId not found in memory")
}
}
// Look for the block in external block store
if (level.useOffHeap) {
logDebug(s"Getting block $blockId from ExternalBlockStore")
if (externalBlockStore.contains(blockId)) {
val result = if (asBlockResult) {
externalBlockStore.getValues(blockId)
.map(new BlockResult(_, DataReadMethod.Memory, info.size))
} else {
externalBlockStore.getBytes(blockId)
}
result match {
case Some(values) =>
return result
case None =>
logDebug(s"Block $blockId not found in ExternalBlockStore")
}
}
}
// Look for block on disk, potentially storing it back in memory if required
if (level.useDisk) {
logDebug(s"Getting block $blockId from disk")
val bytes: ByteBuffer = if (diskStore.contains(blockId)) {
// DiskStore.getBytes() always returns Some, so this .get() is guaranteed to be safe
diskStore.getBytes(blockId).get
} else {
// Remove the missing block so that its unavailability is reported to the driver
removeBlock(blockId)
throw new BlockException(
blockId, s"Block $blockId not found on disk, though it should be")
}
assert(0 == bytes.position())
if (!level.useMemory) {
// If the block shouldn't be stored in memory, we can just return it
if (asBlockResult) {
return Some(new BlockResult(dataDeserialize(blockId, bytes), DataReadMethod.Disk,
info.size))
} else {
return Some(bytes)
}
} else {
// Otherwise, we also have to store something in the memory store
if (!level.deserialized || !asBlockResult) {
/* We'll store the bytes in memory if the block's storage level includes
* "memory serialized", or if it should be cached as objects in memory
* but we only requested its serialized bytes. */
memoryStore.putBytes(blockId, bytes.limit, () => {
// https://issues.apache.org/jira/browse/SPARK-6076
// If the file size is bigger than the free memory, OOM will happen. So if we cannot
// put it into MemoryStore, copyForMemory should not be created. That's why this
// action is put into a `() => ByteBuffer` and created lazily.
val copyForMemory = ByteBuffer.allocate(bytes.limit)
copyForMemory.put(bytes)
})
bytes.rewind()
}
if (!asBlockResult) {
return Some(bytes)
} else {
val values = dataDeserialize(blockId, bytes)
if (level.deserialized) {
// Cache the values before returning them
val putResult = memoryStore.putIterator(
blockId, values, level, returnValues = true, allowPersistToDisk = false)
// The put may or may not have succeeded, depending on whether there was enough
// space to unroll the block. Either way, the put here should return an iterator.
putResult.data match {
case Left(it) =>
return Some(new BlockResult(it, DataReadMethod.Disk, info.size))
case _ =>
// This only happens if we dropped the values back to disk (which is never)
throw new SparkException("Memory store did not return an iterator!")
}
} else {
return Some(new BlockResult(values, DataReadMethod.Disk, info.size))
}
}
}
}
}
} else {
logDebug(s"Block $blockId not registered locally")
}
None
}从Remote获取过程中,首先需要获取当前block的location,而后依次尝试从每一个BlockManager获取数据,知道其中一个获取成功返回结果:
private def doGetRemote(blockId: BlockId, asBlockResult: Boolean): Option[Any] = {
require(blockId != null, "BlockId is null")
val locations = Random.shuffle(master.getLocations(blockId))
var numFetchFailures = 0
for (loc <- locations) {
logDebug(s"Getting remote block $blockId from $loc")
val data = try {
blockTransferService.fetchBlockSync(
loc.host, loc.port, loc.executorId, blockId.toString).nioByteBuffer()
} catch {
case NonFatal(e) =>
numFetchFailures += 1
if (numFetchFailures == locations.size) {
// An exception is thrown while fetching this block from all locations
throw new BlockFetchException(s"Failed to fetch block from" +
s" ${locations.size} locations. Most recent failure cause:", e)
} else {
// This location failed, so we retry fetch from a different one by returning null here
logWarning(s"Failed to fetch remote block $blockId " +
s"from $loc (failed attempt $numFetchFailures)", e)
null
}
}
if (data != null) {
if (asBlockResult) {
return Some(new BlockResult(
dataDeserialize(blockId, data),
DataReadMethod.Network,
data.limit()))
} else {
return Some(data)
}
}
logDebug(s"The value of block $blockId is null")
}
logDebug(s"Block $blockId not found")
None
}
从上文的分析可知Spark的存储系统主要分为两个部分BlockManagerMaster和BlockManager,其中具体的数据由BlockManager管理,而BlockManager主要管理Block-Location对应关系之类的的一些元信息
数据从Local-->Remote或者从Remote-->Local则依赖BlockTransferService,默认实现是NettyBlockTransferService,其中最主要的两个方法是:uploadBlock()和fetchBlocks()
1)fetchBlocks()过程
override def fetchBlocks(
host: String,
port: Int,
execId: String,
blockIds: Array[String],
listener: BlockFetchingListener): Unit = {
logTrace(s"Fetch blocks from $host:$port (executor id $execId)")
try {
val blockFetchStarter = new RetryingBlockFetcher.BlockFetchStarter {
override def createAndStart(blockIds: Array[String], listener: BlockFetchingListener) {
val client = clientFactory.createClient(host, port)
new OneForOneBlockFetcher(client, appId, execId, blockIds.toArray, listener).start()
}
}
val maxRetries = transportConf.maxIORetries()
if (maxRetries > 0) {
// Note this Fetcher will correctly handle maxRetries == 0; we avoid it just in case there's
// a bug in this code. We should remove the if statement once we're sure of the stability.
new RetryingBlockFetcher(transportConf, blockFetchStarter, blockIds, listener).start()
} else {
blockFetchStarter.createAndStart(blockIds, listener)
}
} catch {
case e: Exception =>
logError("Exception while beginning fetchBlocks", e)
blockIds.foreach(listener.onBlockFetchFailure(_, e))
}
} new OneForOneBlockFetcher(client, appId, execId, blockIds.toArray, listener).start() public void start() {
if (blockIds.length == 0) {
throw new IllegalArgumentException("Zero-sized blockIds array");
}
client.sendRpc(openMessage.toByteBuffer(), new RpcResponseCallback() {
@Override
public void onSuccess(ByteBuffer response) {
try {
streamHandle = (StreamHandle) BlockTransferMessage.Decoder.fromByteBuffer(response);
logger.trace("Successfully opened blocks {}, preparing to fetch chunks.", streamHandle);
// Immediately request all chunks -- we expect that the total size of the request is
// reasonable due to higher level chunking in [[ShuffleBlockFetcherIterator]].
for (int i = 0; i < streamHandle.numChunks; i++) {
client.fetchChunk(streamHandle.streamId, i, chunkCallback);
}
} catch (Exception e) {
logger.error("Failed while starting block fetches after success", e);
failRemainingBlocks(blockIds, e);
}
}
@Override
public void onFailure(Throwable e) {
logger.error("Failed while starting block fetches", e);
failRemainingBlocks(blockIds, e);
}
});
} client.fetchChunk(streamHandle.streamId, i, chunkCallback); public void fetchChunk(
long streamId,
final int chunkIndex,
final ChunkReceivedCallback callback) {
final String serverAddr = NettyUtils.getRemoteAddress(channel);
final long startTime = System.currentTimeMillis();
logger.debug("Sending fetch chunk request {} to {}", chunkIndex, serverAddr);
final StreamChunkId streamChunkId = new StreamChunkId(streamId, chunkIndex);
handler.addFetchRequest(streamChunkId, callback);
channel.writeAndFlush(new ChunkFetchRequest(streamChunkId)).addListener(
new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
if (future.isSuccess()) {
long timeTaken = System.currentTimeMillis() - startTime;
logger.trace("Sending request {} to {} took {} ms", streamChunkId, serverAddr,
timeTaken);
} else {
String errorMsg = String.format("Failed to send request %s to %s: %s", streamChunkId,
serverAddr, future.cause());
logger.error(errorMsg, future.cause());
handler.removeFetchRequest(streamChunkId);
channel.close();
try {
callback.onFailure(chunkIndex, new IOException(errorMsg, future.cause()));
} catch (Exception e) {
logger.error("Uncaught exception in RPC response callback handler!", e);
}
}
}
});
}将callBack传递给handler,等待fetchChunk成功之后由handler调用callback
handler.addFetchRequest(streamChunkId, callback); ChunkFetchSuccess resp = (ChunkFetchSuccess) message;
ChunkReceivedCallback listener = outstandingFetches.get(resp.streamChunkId);
if (listener == null) {
logger.warn("Ignoring response for block {} from {} since it is not outstanding",
resp.streamChunkId, remoteAddress);
resp.body().release();
} else {
outstandingFetches.remove(resp.streamChunkId);
listener.onSuccess(resp.streamChunkId.chunkIndex, resp.body());
resp.body().release();
} override def uploadBlock(
hostname: String,
port: Int,
execId: String,
blockId: BlockId,
blockData: ManagedBuffer,
level: StorageLevel): Future[Unit] = {
val result = Promise[Unit]()
val client = clientFactory.createClient(hostname, port)
// StorageLevel is serialized as bytes using our JavaSerializer. Everything else is encoded
// using our binary protocol.
val levelBytes = serializer.newInstance().serialize(level).array()
// Convert or copy nio buffer into array in order to serialize it.
val nioBuffer = blockData.nioByteBuffer()
val array = if (nioBuffer.hasArray) {
nioBuffer.array()
} else {
val data = new Array[Byte](nioBuffer.remaining())
nioBuffer.get(data)
data
}
client.sendRpc(new UploadBlock(appId, execId, blockId.toString, levelBytes, array).toByteBuffer,
new RpcResponseCallback {
override def onSuccess(response: ByteBuffer): Unit = {
logTrace(s"Successfully uploaded block $blockId")
result.success((): Unit)
}
override def onFailure(e: Throwable): Unit = {
logError(s"Error while uploading block $blockId", e)
result.failure(e)
}
})
result.future
}














 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









