







1. AlexNet
1.1 AlexNet 原理描述
AlexNet 是 一个深度神经网络,AlexNet 共有 8 个层,5 个卷积层,2 个全连接隐藏层和 1 个全连接输出层。
1.2 AlexNet 图解描述

1.3 AlexNet 源码分析
- 代码
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: AlexNet
# @Create time: 2021/12/7 19:50
# 1. 导入相关数据库
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
# 2. 定义网络 AlexNet;
# 注意:相对于 LeNet:
# 2.1 激活函数由 Sigmoid 改成 ReLU();
# 2.2 引入 nn.Dropout ;
# 2.3 卷积核改成 11 X 11
net = nn.Sequential(
# 这里,我们使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
# 使用三个连续的卷积层和较小的卷积窗口。
# 除了最后的卷积层,输出通道的数量进一步增加。
# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合
nn.Linear(6400, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10))
# 3. 定义批量大小
batch_size = 128
# 4. 因为 ImageNet 数据集太大,所以我们还是用 Fashion_Mnist
# 为了保证数据大小一致,所以我们用transforms.Resize进行图片预处理
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
# 5. 定义超参数
lr, num_epochs = 0.01, 10
# 6. 开始训练
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# 7. 显示结果
plt.show()
- 结果
loss 0.324, train acc 0.882, test acc 0.885
897.5 examples/sec on cuda:0

1.4 AlexNet 优缺点分析
AlexNet 主要运用了 nn.Dropout,nn.Relu,图像预处理这三个优点,提高了模型的鲁棒性。
2. VGG
2.1 VGG 优点
对比于 AlexNet 网络来说,VGG 块的有点在于定义了一个 VGG 块,并在主干网络中进行重复的调用 VGG块进行网络层的设计,相对于 AlexNet 来说,VGG块更具有结构化的设计思路,为后续的深度神经网络提供的设计思路。VGG 大量使用了 3 X 3 的卷积神经网络,作者认为我们用更多的 3 X 3 进行堆积比用少量的 5 X 5 卷积更好。
2.2 VGG 块原理

对于 VGG 块来说,卷积层有三个参数 :
- num_covs: 3 X 3 卷积层的个数;因为 Padding 填充为1,所以图像大小不变
- in_channels: 输入的通道数
- out_channels: 输出的通道数
最后卷积层调用一个 nn.MaxPool2d(kernel_size=2,stride=2) 进行求解,最终高宽减半。
2.3 VGG 块代码
- VGG-block 代码
# 1. 导入数据库
import torch
from torch import nn
from d2l import torch as d2l
# 2. 定义 VGG 块,VGG 块有 num_convs 个 3X3 卷积和激活ReLU()组成, 最后是一个 nn.MaxPool2d 组成,
# a.我们新建一个空的列表,
# b.通过列表 append 进行添加
# c.将列表数据传入到 nn.Sequential 中
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
# 为了保证串联,所以我们希望上一个网络的输出通道数等于下一个网络的输入通道数
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
- VGG net
# 定义 5 个 VGG_block ,因为 224/2/2/2/2/2 = 7 ,所以我们定义 5 组 vgg_block.
conv_arch = ((1,64),(1,128),(2,256),(2,512),(2,512))
def vgg(conv_arch):
conv_block = []
in_channels = 1
for (num_convs,out_channels) in conv_arch:
conv_block.append(vgg_block(num_convs,in_channels,out_channels))
in_channels = out_channels
return nn.Sequential(*conv_block,nn.Flatten(),
nn.Linear(out_channels*7*7,4096),nn.ReLU(),nn.Dropout(0.5),
nn.Linear(4096,4096),nn.ReLU(),nn.Dropout(0.5),
nn.Linear(4096,1000))
2.4 VGG 小结
VGG 网络的意义在于它开启了模块化网络设计方法的时代。我们通过 list 进行构建链式结构。不足为,这个网络基本都是链式结构,是简单的串联。
3. NiN
3.1 NiN 原理描述
NiN 网络结构的意义在于两点
- 1 它完全摒弃了全连接层,用 1 X 1 的卷积核来替代全连接层,等效于将每个像素的通道进行全连接,本质上跟全连接层一样。
- 2 相对于 AlexNet 和 VGG,因为没有了全连接层,所以最后进行分类的时候是基于通道数的分类,最后使用了全局平局池化层输出
3.2 NiN 图解描述

3.3 NiN 源码分析
- nin_block NiN 块的定义
# 1.导入数据库
import torch
from torch import nn
from d2l import torch as d2l
# 2. 定义 NiN_block 块,组成为 1个卷积层和2个1x1卷积层
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
- 定义 NiN 网络
注意:NiN 网络用了三个卷积层 ;11 x 11, 5 x 5 , 3 x 3
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
3.4 NiN 优缺点分析
NiN使用一个 NiN块,其输出通道数等于标签类别的数量,最后放到一个全局平均汇聚层,生成一个多元逻辑向量,NiN设计的一个优点是,它显著减少了模型所需参数的数量。缺点是这种设计会增加训练模型的时间
4. GoogLeNet
4.1 GoogLeNet 原理描述
GoogLeNet 创造性的使用了 Inception块,对于以前的网络来说,我们一般要么选择使用 3X3的卷积,要么使用 5X5,要么使用11X11卷积,而Inception块在使用的过程中,我们就干脆将这些东西并联在一起,那么我们就可以用不同的卷积了,具体是我们在 Inception块 中进行并联不同的卷积网络,左后通过通道合并在一起输出
4.2 GoogLeNet 图解描述
- Inception块

- GoogLeNet

4.3 GoogLeNet 源码分析
- Inception 块
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
- GoogLeNet
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
4.4 GoogLeNet 优缺点分析
GoogLeNet 结构复杂,主要是有钱人的游戏,都是大量实验调参的出来的结果,不知道为什么会这样设计。能力有限,无法解析超参数的设计。
5. 批量规范化
5.1 训练中遇到的问题
我们在训练神经网络时候经常遇到如下问题:
- 在比较深的神经网络中,我们发现底层的训练非常的慢,而靠近输出的层训练速度快;简单来说,我们数据在forward传入是从底层向顶层传播的。在进行损失backward的时候,我们数据梯度更新是由顶层向底层传播的。
- 我们底部的层在进行数据更新的时候,会导致顶部输出层的更新,从而导致训练时间长;简单来说就是在上层的梯度比较大,容易更新,但是在底层梯度比较小,所以更新较慢。
- 很深的网络容易过拟合,所以需要正则化处理数据
5.2 解决方案
为了解决上述问题,我们希望将小批量的数据进行归一化处理,将数据经过处理后使得它们分布在均值为0,方差为1的分布中;为了使得数据更加平滑,我们引入可以学习的参数 γ , β \gamma,\beta γ,β,为了方差不为零,我们引入一个非常小的数值 ϵ \epsilon ϵ
- 固定小批量里面的均值和方差
μ B = 1 B ∑ i ∈ B x i ; σ B 2 = 1 B ∑ i ∈ B ( x i − μ B ) 2 + ϵ (1) \mu_B=\frac{1}{B}\sum_{i\in B}x_i ;\quad \sigma^2_B=\frac{1}{B}\sum_{i\in B}(x_i-\mu_B)^2+\epsilon\tag{1} μB=B1i∈B∑xi;σB2=B1i∈B∑(xi−μB)2+ϵ(1)
批量规范化在一开始设计时候,作者的意图是为了减少内部协变量偏移,但是由于这个批量规范化的效果实在太好了,后续人们在研究过程中发现,它的作用可能就是通过在每个小批量里加入噪音来控制模型复杂度
x
i
+
1
=
γ
x
i
−
μ
B
^
σ
B
^
+
β
(2)
x_{i+1} = \gamma \frac{x_i-\hat{\mu_B}}{\hat{\sigma_B}}+\beta\tag{2}
xi+1=γσB^xi−μB^+β(2)
- μ B ^ \hat{\mu_B} μB^:一个批量中的均值, σ B ^ \hat{\sigma_B} σB^:一个批量中的样本标准差。
- γ , β \gamma,\beta γ,β是需要通过样本学习的参数。
5.3 注意点
- 批量归一化层有可学习的参数 γ , β \gamma , \beta γ,β
- 作用在:
– 全连接层和卷积层输出上,激活函数前
– 全连接和卷积层输入上 - 对全连接层,作用在特征维
- 对于卷积层,作用在通道维
- 批量规范化图层在”训练模式“(通过小批量统计数据规范化)和“预测模式”(通过数据集统计规范
化)中的功能不同。在训练过程中,我们⽆法得知使⽤整个数据集来估计平均值和⽅差,所以只能根据每个小批次的平均值和⽅差不断训练模型。而在预测模式下,可以根据整个数据集精确计算批量规范化所需的平均值和⽅差。
5.4 batch_norm 函数
- batch_norm 函数图解

- batch_norm 代码
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: Batch_Norm2d
# @Create time: 2021/12/11 20:08
# 1. 导入数据库
import torch
from torch import nn
from d2l import torch as d2l
# 2. 定义批量规范化函数
"""
batch_norm 函数思路:详见图解
"""
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
"""
功能:将输入的数据经过归一化后得到均值为0,方差为1 的分布,通过 gamma,beta 来调整分布的形状
注意:1.训练用的是当前批量样本的均值和方差;2.预测用的是全局的均值和方差
:param X: 样本 X
:param gamma: 需要学习的参数 gamma
:param beta: 需要学习的参数 beta
:param moving_mean: 全局样本的均值
:param moving_var: 全局样本的方差
:param eps: 一个非常小的值,大概 le-5,防止除不尽
:param momentum: 动量值,默认为0.9
:return: Y-归一化后的值, moving_mean.data-全局均值的数值, moving_var.data-全局方差的数值
"""
if not torch.is_grad_enabled(): # 如果不算梯度,那么就进行预测
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps) # 计算X_hat,直接调用全局均值和方差
else:
assert len(X.shape) in (2, 4): # 仅限于二维的全连接层(样本,特征),四维卷积(batch_size,out_channels,h,w)
if len(X.shape) == 2: # 如果是全连接层,
mean = X.mean(dim=0) # 按行求均值,得到 (1,N)的行向量
var = ((X - mean) ** 2).mean(dim=0) # 按行求方差
else: # keepdim=True:表示最后得到的 mean 维度为 (1,N_mean,1,1)
mean = X.mean(dim=(0, 2, 3), keepdim=True) # 按通道数求均值,由于dim=1为输出通道数,所以dim=(0,2,3)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
X_hat = (X - mean) / torch.sqrt(var + eps) # 按照公式 X_hat = \frac{X-mean}{\sqrt{var+eps}},eps 为了防止除数为0
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean # 滑动平均法,用当前的均值来估计全局均值
moving_var = momentum * moving_var + (1.0 - momentum) * var # 滑动平均法,用当前的方差来估计全局方差
Y = gamma * X_hat + beta # gamma,beta 是要学习的参数
return Y, moving_mean.data, moving_var.data
- BatchNorm 批量规范层代码

class BatchNorm(nn.Module):
# num_features : 完全连接层的输出数量或卷积层的输出通道数
# num_dims : 2:表示完全连接层; 4:表示卷积层
def __init__(self, num_features, num_dims):
super().__init__() # 继承父类初始化
if num_dims == 2: # 完全连接层
shape = (1, num_features)
else: # 卷积层
shape = (1, num_features, 1, 1)
self.gamma = nn.Parameter(torch.ones(shape)) # 可学习参数用 nn.Parameter
self.beta = nn.Parameter(torch.zeros(shape)) # 可学习参数用 nn.Parameter
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device) # 如果有 GPU ,则需要将数据放到 GPU 上
self.moving_var = self.moving_var.to(X.device)
Y, self.moving_mean, self.moving_var = batch_norm( # 保存更新过的moving_mean和moving_var
X, self.gamma, self.beta, self.moving_mean,self.moving_var, eps=1e-5, momentum=0.9)
return Y
5.5 BatchNorm 简洁实现
直接调用 nn.BatchNorm2d(K),其中 K 表示的是通道数大小
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
5.6 小结
- 在模型训练过程中,批量规范化小批量的均值和方差,不断调整神经网络的中间输出,使整个神经网络的中间输出更加稳定
- 批量规范化在全连接层和卷积层的使用是不同的
- 批量规范化层和丢弃层一样,在训练模式和预测模式的表现是不相同的
- 皮脸规范化层会加快模型收敛的速度而不影响模型精度,故而经常在网络模型中使用
- 在后续的研究中,人们发现批量规范化的作用是在一个小批量的数据中随机增加了均值和方差的噪音,从而使得网络更加的泛化,而不是之前的减少内部协变量偏移的说法,也就是原来作者写的理由是瞎编的。但效果却非常的好。工程实践大于理论的研究
6. ResNet
6.1 训练面临的问题
深度学习一直在选择使用更深的神经网络,但是更深的网络就一定是能够获得更好的效果吗?
- 当模型有偏差时候
我们发现,随着模型的偏差,F6举例 f’ 的距离并不是最近的,在图上可以看出来,大概是在 F3处,最后得到的效果是浅层的网络居然比深的网络效果更好。 - 当模型用残差网络时候
如果我们的网络是相互嵌套的时候,我们的模型会有所改进,至少不会变差,聊胜于无吧。

6.2 残差块图解
- ResNet 块基本框架图
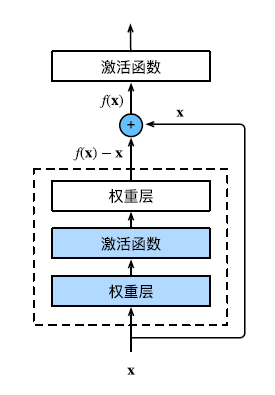
- ResNet 块的代码图
注意:在ResNet 块代码里面,用了 2 个3 X 3 的卷积核,2个batchNorm,1个激活函数,这里短路的导线X有两种方案,一种是直接跳跃过来,另一种是经过 1X1 的卷积层后过来,最后相加得到Y+=X.然后通过激活函数输出。
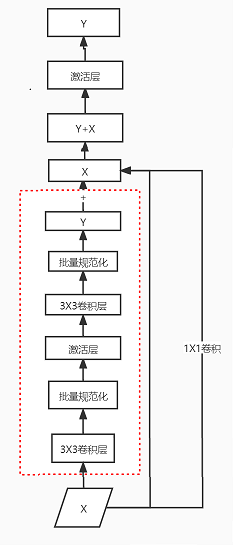
- ResNet 块代码
# -*- coding: utf-8 -*-
# @Project: zc
# @Author: zc
# @File name: ResNet
# @Create time: 2021/12/12 17:24
# 1. 导入相关库
import torch
from torch import nn
from d2l import torch
from torch.nn import functional as F
# 2. 定义残差块,继承自 nn.Module
class Residual(nn.Module):
def __init__(self, inputs_channels, num_channels, use_1x1conv=False, strides=1):
"""
功能:实现残差块操作
:param inputs_channels: 输入通道数
:param num_channels: 输出通道数
:param use_1x1conv: 是否用1X1卷积
:param strides: 步幅,默认为1
"""
super().__init__() # 初始化
self.conv1 = nn.Conv2d(inputs_channels, num_channels, # 初始化 3X3 卷积
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, # 初始化 3X3 卷积
kernel_size=3, padding=1)
if use_1x1conv: # 判断是否用 1X1 卷积
self.conv3 = nn.Conv2d(inputs_channels, num_channels, kernel_size=1, stride=strides) # 初始化 1X1卷积
else:
self.conv3 = None # 无
self.bn1 = nn.BatchNorm2d(num_channels) # 初始化批量规范化
self.bn2 = nn.BatchNorm2d(num_channels) # 初始化批量规范化
def forward(self, X): # 自定义前向算法
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
6.3 定义 ResNet 网络
# 3. 定义第一个stage,用的是 7x7的卷积层和 3X3的最大池化层
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.BatchNorm2d(64),
nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 4.定义残差块,调用 Residual 类
def resnet_block(input_channels, num_channels, num_residuals,
first_blocks=False):
"""
:param input_channels: 输入通道数
:param num_channels: 输出通道数
:param num_residuals: Residual 块的数量
:param first_blocks: 判断是否是第一个块
:return: 返回序列
注意:如果 stage 是 b2 就不减半了。因为b1已经进行了减半
"""
blk = []
for i in range(num_residuals):
if i == 0 and not first_blocks:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
6.4 ResNet 为什么能训练这么深
- ResNet 出现前网络梯度
z = g ( f ( x ) ) (1) z=g(f(x))\tag{1} z=g(f(x))(1) - 令 y = f(x); z = g(y)
- 我们对上述函数关于权重 w 求导
∂ z ∂ w = ∂ z ∂ y ⋅ ∂ y ∂ w (2) \frac{\partial z}{\partial w}=\frac{\partial z}{\partial y}·\frac{\partial y}{\partial w}\tag{2} ∂w∂z=∂y∂z⋅∂w∂y(2)
如果我们增加的层数越多,即使我们的梯度值 ∂ z ∂ y = 0.8 , 0. 8 100 = 2 × 1 0 − 10 \frac{\partial z}{\partial y}=0.8,0.8^{100}=2\times 10^{-10} ∂y∂z=0.8,0.8100=2×10−10,这样就会导致层数越多,梯度消失现象。为了解决上述问题,kaiming大神想出来了一个方式,既然梯度在相乘的过程中会消失,那就加起来把,我等菜鸡一看,我擦,真牛逼啊,思路奇特。 - ResNet的解决方案
-
y
=
f
(
x
)
;
z
=
g
(
f
(
x
)
)
y=f(x);z=g(f(x))
y=f(x);z=g(f(x))
m = f ( x ) + g ( f ( x ) ) (3) m = f(x)+g(f(x))\tag{3} m=f(x)+g(f(x))(3)
我们对上述函数关于权重 w 求导:
∂ m ∂ w = ∂ y ∂ w + ∂ z ∂ w (4) \frac{\partial m}{\partial w}=\frac{\partial y}{\partial w}+\frac{\partial z}{\partial w}\tag{4} ∂w∂m=∂w∂y+∂w∂z(4) - 注: 原来的梯度( ∂ y ∂ w \frac{\partial y}{\partial w} ∂w∂y)是没有变的,后面的梯度是和原来相加的,那么即使后面的梯度非常小,一个大数加小数是没问题的,不会影响这个和的值,所以就解决了梯度消失的问题,这样进行训练的时候,就没问题了。实在是太佩服 kaiming 大神了。
- 图解相关问题
- 注:数据在拟合中,按照两条通道执行,a 和 b 通道,当发现后面的参数拟合受到阻力的时候,我们就可以通过快速通道 b 来运行了,这样的话,我们可以保证网络运行的会比以前好,不至于比以前差。
















 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









