







以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。
本节课程地址:无
本节教材地址:12.3. 自动并行 — 动手学深度学习 2.0.0 documentation
本节开源代码:...>d2l-zh>pytorch>chapter_optimization>auto-parallelism.ipynb
自动并行
深度学习框架(例如,MxNet、飞桨和PyTorch)会在后端自动构建计算图。利用计算图,系统可以了解所有依赖关系,并且可以选择性地并行执行多个不相互依赖的任务以提高速度。例如,12.2节 中的 图12.2.2 独立初始化两个变量。因此,系统可以选择并行执行它们。
通常情况下单个操作符将使用所有CPU或单个GPU上的所有计算资源。例如,即使在一台机器上有多个CPU处理器,dot操作符也将使用所有CPU上的所有核心(和线程)。这样的行为同样适用于单个GPU。因此,并行化对单设备计算机来说并不是很有用,而并行化对于多个设备就很重要了。虽然并行化通常应用在多个GPU之间,但增加本地CPU以后还将提高少许性能。例如, (Hadjis et al., 2016) 则把结合GPU和CPU的训练应用到计算机视觉模型中。借助自动并行化框架的便利性,我们可以依靠几行Python代码实现相同的目标。对自动并行计算的讨论主要集中在使用CPU和GPU的并行计算上,以及计算和通信的并行化内容。
请注意,本节中的实验至少需要两个GPU来运行。
import torch
from d2l import torch as d2l基于GPU的并行计算
从定义一个具有参考性的用于测试的工作负载开始:下面的run函数将执行 10 次矩阵-矩阵乘法时需要使用的数据分配到两个变量(x_gpu1和x_gpu2)中,这两个变量分别位于选择的不同设备上。
devices = d2l.try_all_gpus()
def run(x):
return [x.mm(x) for _ in range(50)]
x_gpu1 = torch.rand(size=(4000, 4000), device=devices[0])
x_gpu2 = torch.rand(size=(4000, 4000), device=devices[1])现在使用函数来处理数据。通过在测量之前需要预热设备(对设备执行一次传递)来确保缓存的作用不影响最终的结果。torch.cuda.synchronize()函数将会等待一个CUDA设备上的所有流中的所有核心的计算完成。函数接受一个device参数,代表是哪个设备需要同步。如果device参数是None(默认值),它将使用current_device()找出的当前设备。
run(x_gpu1)
run(x_gpu2) # 预热设备
torch.cuda.synchronize(devices[0])
torch.cuda.synchronize(devices[1])
with d2l.Benchmark('GPU1 time'):
run(x_gpu1)
torch.cuda.synchronize(devices[0])
with d2l.Benchmark('GPU2 time'):
run(x_gpu2)
torch.cuda.synchronize(devices[1])输出结果:
GPU1 time: 1.4571 sec
GPU2 time: 1.4560 sec
如果删除两个任务之间的synchronize语句,系统就可以在两个设备上自动实现并行计算。
with d2l.Benchmark('GPU1 & GPU2'):
run(x_gpu1)
run(x_gpu2)
torch.cuda.synchronize()输出结果:
GPU1 & GPU2: 1.5222 sec
在上述情况下,总执行时间小于两个部分执行时间的总和,因为深度学习框架自动调度两个GPU设备上的计算,而不需要用户编写复杂的代码。
并行计算与通信
在许多情况下,我们需要在不同的设备之间移动数据,比如在CPU和GPU之间,或者在不同的GPU之间。例如,当执行分布式优化时,就需要移动数据来聚合多个加速卡上的梯度。让我们通过在GPU上计算,然后将结果复制回CPU来模拟这个过程。
def copy_to_cpu(x, non_blocking=False):
return [y.to('cpu', non_blocking=non_blocking) for y in x]
with d2l.Benchmark('在GPU1上运行'):
y = run(x_gpu1)
torch.cuda.synchronize()
with d2l.Benchmark('复制到CPU'):
y_cpu = copy_to_cpu(y)
torch.cuda.synchronize()输出结果:
在GPU1上运行: 1.8508 sec
复制到CPU: 3.1686 sec
这种方式效率不高。注意到当列表中的其余部分还在计算时,我们可能就已经开始将y的部分复制到CPU了。例如,当计算一个小批量的(反传)梯度时。某些参数的梯度将比其他参数的梯度更早可用。因此,在GPU仍在运行时就开始使用PCI-Express总线带宽来移动数据是有利的。在PyTorch中,to()和copy_()等函数都允许显式的non_blocking参数,这允许在不需要同步时调用方可以绕过同步。设置non_blocking=True以模拟这个场景。
with d2l.Benchmark('在GPU1上运行并复制到CPU'):
y = run(x_gpu1)
y_cpu = copy_to_cpu(y, True)
torch.cuda.synchronize()输出结果:
在GPU1上运行并复制到CPU: 2.6157 sec
两个操作所需的总时间少于它们各部分操作所需时间的总和。请注意,与并行计算的区别是通信操作使用的资源:CPU和GPU之间的总线。事实上,我们可以在两个设备上同时进行计算和通信。如上所述,计算和通信之间存在的依赖关系是必须先计算y[i],然后才能将其复制到CPU。幸运的是,系统可以在计算y[i]的同时复制y[i-1],以减少总的运行时间。
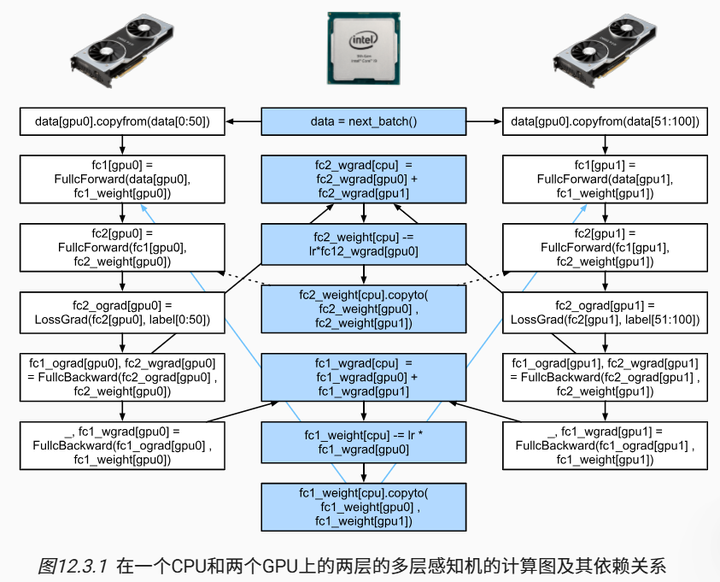
最后,本节给出了一个简单的两层多层感知机在CPU和两个GPU上训练时的计算图及其依赖关系的例子,如 图12.3.1 所示。手动调度由此产生的并行程序将是相当痛苦的。这就是基于图的计算后端进行优化的优势所在。
小结
- 现代系统拥有多种设备,如多个GPU和多个CPU,还可以并行地、异步地使用它们。
- 现代系统还拥有各种通信资源,如PCI Express、存储(通常是固态硬盘或网络存储)和网络带宽,为了达到最高效率可以并行使用它们。
- 后端可以通过自动化地并行计算和通信来提高性能。
练习
- 在本节定义的
run函数中执行了八个操作,并且操作之间没有依赖关系。设计一个实验,看看深度学习框架是否会自动地并行地执行它们。
解:
run函数实际是执行了50个矩阵乘法操作,设计实验比较单个矩阵乘法和用run函数执行50个矩阵乘法的时间,发现用run函数执行50个矩阵乘法的时间小于单个矩阵乘法执行50次的时间,证明深度学习框架会自动地并行地执行它们。
代码如下:
# 单个矩阵乘法时间基准
with d2l.Benchmark('Single matmul'):
x_gpu1.mm(x_gpu1)
torch.cuda.synchronize()
# 多个独立矩阵乘法时间
with d2l.Benchmark('Multiple matmuls'):
run(x_gpu1)
torch.cuda.synchronize()输出结果:
Single matmul: 0.0457 sec
Multiple matmuls: 1.4930 sec
2. 当单个操作符的工作量足够小,即使在单个CPU或GPU上,并行化也会有所帮助。设计一个实验来验证这一点。
解:
还是基于矩阵乘法,将x的尺寸设置为10×10的小尺寸,在单个CPU或GPU上,用run函数自动并行的计算时间都更少,说明当单个操作符的工作量足够小,即使在单个CPU或GPU上,并行化也会有所帮助。
代码如下:
def benchmark_matmul(size, device):
x = torch.randn(size, size, device=device)
# 顺序执行基准
with d2l.Benchmark(f'Size {size}x{size} (Sequential)'):
for _ in range(50):
_ = x.matmul(x)
if device.type == 'cuda':
torch.cuda.synchronize()
# 自动并行执行(框架隐式优化)
with d2l.Benchmark(f'Size {size}x{size} (Auto-Parallel)'):
run(x)
if device.type == 'cuda':
torch.cuda.synchronize()
# 单个CPU
device = torch.device('cpu')
benchmark_matmul(10, device)输出结果:
Size 10x10 (Sequential): 0.0518 sec
Size 10x10 (Auto-Parallel): 0.0005 sec
# 单个GPU
devices = d2l.try_all_gpus()
benchmark_matmul(10, devices[0])输出结果:
Size 10x10 (Sequential): 0.0025 sec
Size 10x10 (Auto-Parallel): 0.0010 sec
3. 设计一个实验,在CPU和GPU这两种设备上使用并行计算和通信。
解:
本节的12.3.2中的实验可以说明,在CPU和GPU这两种设备上可以同时进行并行计算和通信,减少总体运行时间。
4. 使用诸如NVIDIA的Nsight之类的调试器来验证代码是否有效。
解:
没有Nsight,改用Pytorch的Profiler验证,从Profiler打印的结果表格中可以看到,多个任务的Self CUDA %都是100%,说明确实进行了并行计算。
代码如下:
from torch.profiler import ProfilerActivity
with torch.profiler.profile(
activities=[ProfilerActivity.CUDA, ProfilerActivity.CPU],
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log')
) as prof:
for _ in range(5):
run(x_gpu1)
run(x_gpu2)
torch.cuda.synchronize()
prof.step()
print(prof.key_averages().table()
输出结果:
------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
ProfilerStep* 0.04% 1.745ms 100.00% 4.440s 1.480s 0.000us 0.00% 8.837s 2.946s 3
aten::mm 0.13% 5.705ms 0.17% 7.698ms 25.659us 8.837s 100.00% 8.837s 29.458ms 300
cudaOccupancyMaxActiveBlocksPerMultiprocessor 0.00% 202.240us 0.00% 202.240us 0.674us 0.000us 0.00% 0.000us 0.000us 300
cudaLaunchKernel 0.04% 1.790ms 0.04% 1.790ms 5.968us 0.000us 0.00% 0.000us 0.000us 300
ProfilerStep* 0.00% 0.000us 0.00% 0.000us 0.000us 8.838s 100.00% 8.838s 1.473s 6
volta_sgemm_128x64_nn 0.00% 0.000us 0.00% 0.000us 0.000us 8.837s 100.00% 8.837s 29.755ms 297
cudaDeviceSynchronize 99.79% 4.430s 99.79% 4.430s 1.108s 0.000us 0.00% 0.000us 0.000us 4
------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 4.440s
Self CUDA time total: 8.837s5. 设计并实验具有更加复杂的数据依赖关系的计算任务,以查看是否可以在提高性能的同时获得正确的结果。
解:
以下实验可以证明,在利用并行提高计算性能的同时,获得与串行一致的结果。
代码如下:
# 构建复杂依赖关系:
# A → B → C
# │ │
# ↓ ↓
# D → E → F
import time
def task(x, name):
"""模拟不同计算任务"""
if name == 'A': return x @ x.T
elif name == 'B': return x * x.sum()
elif name == 'C': return x.cos() + x.sin()
elif name == 'D': return x.pow(2).mean()
elif name == 'E': return x.norm(dim=1)
elif name == 'F': return x.softmax(dim=0)
def serial_execution(x):
"""串行执行(严格按依赖顺序)"""
a = task(x, 'A')
b = task(a, 'B')
d = task(a, 'D')
c = task(b, 'C')
e = task(b, 'E')
f = task(e, 'F')
return c, d, f
def parallel_execution(x):
"""并行执行(重叠无依赖任务)"""
# 第一层并行
stream1 = torch.cuda.Stream()
stream2 = torch.cuda.Stream()
with torch.cuda.stream(stream1):
a = task(x, 'A')
torch.cuda.synchronize() # 确保a完成
with torch.cuda.stream(stream1):
b = task(a, 'B')
with torch.cuda.stream(stream2):
d = task(a, 'D') # 与b无依赖,可并行
torch.cuda.synchronize() # 等待b,d完成
with torch.cuda.stream(stream1):
c = task(b, 'C')
with torch.cuda.stream(stream2):
e = task(b, 'E') # 依赖b,但c/e之间无依赖
torch.cuda.synchronize() # 等待e完成
f = task(e, 'F')
return c, d, f
def run_test(matrix_size=1000):
x = torch.randn(matrix_size, matrix_size, device='cuda')
# 串行执行
torch.cuda.synchronize()
start = time.time()
c_serial, d_serial, f_serial = serial_execution(x)
torch.cuda.synchronize()
serial_time = time.time() - start
# 并行执行
torch.cuda.synchronize()
start = time.time()
c_parallel, d_parallel, f_parallel = parallel_execution(x)
torch.cuda.synchronize()
parallel_time = time.time() - start
# 结果对比
def check_equal(t1, t2):
return torch.allclose(t1, t2, rtol=1e-4, atol=1e-6)
is_correct = (check_equal(c_serial, c_parallel) and
check_equal(d_serial, d_parallel) and
check_equal(f_serial, f_parallel))
print(f"矩阵大小: {matrix_size}x{matrix_size}")
print(f"串行时间: {serial_time:.4f}s")
print(f"并行时间: {parallel_time:.4f}s")
print(f"加速比: {serial_time/parallel_time:.2f}x")
print(f"结果一致: {is_correct}")
run_test(matrix_size=1000)输出结果:
矩阵大小: 1000x1000
串行时间: 0.3834s
并行时间: 0.0062s
加速比: 61.86x
结果一致: True



















 38
38

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











