







学了有一段时间的图像识别的相关知识,始终不得入门,最近才有所心得。在这里做一点头脑笔记。
环境安装配置:
首先我们要配置tensorflow的开发环境,为什么要用tensorflow,跟着谷歌爸爸就不会错滴。安装python的集成环境Anaconda3,创建一个叫tensorflow的虚拟运行环境,同时安装python3.5(这个坑不知道有没有人遇到,我本来按的是2.7版本的,然后改成最新3.6,都不支持tensorflow,后来我看到有博主说tensorflow只支持3.5,我也不知道真假,反正3.5是没问题)。
选PyCharm作为IDE注意,在setting下选择Project Interpreter 选择python.exe是,要选择tensorflow虚拟环境下的python.exe,位置在envs/tensorflow/python.exe, 这个坑我也踩过。当你import tensorflow as tf不会报错就没问题了。
MINST数据模型:
我们都知道手写数字MINST是机器学习的Hello World,就以这个为例简单体验一下。
导入数据:由于tensorflow里面有这个数据集,我们就不用在网上去下载了,很多老的博客都说去下载,别信。
两行代码:
from tensorflow.examples.tutorials.mnist import input_data
# Get MNIST Data
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)我们先不弄CNN的,简单版本的来试下水。
首先,我们要搞清楚我们研究的问题本质是什么,我们要区分0到9这十个手写字,解决方法是构建一个模型来训练,然后这个训练后的模型可以区分新的图片。难点在于模型如何构建?如何判断这个模型是好是坏?
我们要明白,我们无法做到准确判断,只能给出概率,相信你可以理解。还有一点,这本质是一个线性回归的问题,相信也可以理解。所以这个模型构建就很容易理解了,就是一个函数 y=wx+b,w叫权重,b叫做偏置项。我们要做的工作就是找到一个很棒的w和b, 有人说机器学习就是调参的过程,我深以为然。当然如果你运气好,一步到位,接下来的工作就不用做了,不过这可是玄学,还是老实点来优化你的参数吧。
实现回归模型y=wx+b,y是要输出的,x就是我们需要输入的,我们输入的是一张张图片,当然直接是无法计算的,所以用像素来计算,每张图片是 28 x 28 像素,即 784 个像素点,我们可以把它展开形成一个向量,即长度为 784 的向量。训练集我们可以转化为 [55000, 784] 的向量。具体怎么算,详看代码。然后我们需要有一个指标来评估我们模型是好是坏啊,它就是成本或者损失。损失越小当然我们模型也就越棒。
非常漂亮的成本函数是“交叉熵”。交叉熵产生于信息论里面的信息压缩编码技术,但是它后来演变成为从博弈论到机器学习等其他领域里的重要技术手段。信息论中的熵是指信息不确定性的度量。熵越高代表为了呈现某个事物所需要的信息量就越多。熵的值都是基于概率的,其概率解释是:当某些事物在样本空间中的占比率越高,则需要将他描述出来的信息量越少。而交叉熵计算公式为
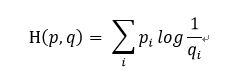
具体可以自行百度,现在你只需要知道它是用来计算损失函数的,我们怎么让这个损失变得最小呢,这里用到经典的梯度下降法,tensorflow 只需将每个变量一点点地往使成本不断降低的方向移动即可。
有一个问题,无论是我们训练还是最后识别的时候,我们计算出的线性输出可能不是一个0到1之间的概率(且所有概率之和为1),比如计算出来的是2.2,4.3,-1.1,怎么会有负数,这很有可能。用Softmax 可以解决,它可以看成是一个激励函数或者链接函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于 10 个数字类的概率分布。
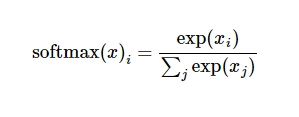
Softmax 的过程首先会对各个值进行次幂计算,然后计算各个次幂结果占总次幂结果的比重,所以这样我们就可以实现差别的放缩,即好的更好、差的更差。
接下来运行设置好了模型,我们把它放到 Session 里面运行,之后然后可以测试这个模型。详看代码。最后可以看看你模型的准确率。
还有一个问题就是为什么有训练集、测试集,还有验证集呢,对原始数据进行三个数据集的划分,也是为了防止模型过拟合。过拟合是什么呢,就是在训练的时候表现很好,真正测试的时候呢,就错误百出。训练集和测试集很好理解,而验证集就是当通过训练集训练出多个模型后,为了能找出效果最佳的模型,使用各个模型对验证集数据进行预测,并记录模型准确率。选出效果最佳的模型所对应的参数,即用来调整模型参数。
最终的结果还是找出一个最佳的参数,而废了这么大劲。不过这也是前人优秀的经验,值得赞扬。
下一篇总结使用卷积神经网络CNN来训练模型,是的,厉害的还在后面。














 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









