







C中sections指令结构如下:
#pragma omp sections [clause[[,] clause] .. ]
{
[#pragma omp section]
structured-block
[#pragma omp section]
structured-block
……………..
}
其中条件clause可以为private(list)、firstprivate(list)、lastprivate(list)、reduction(operator: list)和 等。
采用section定义的每段程序都将只执行一次,sections中的每段section将并行执行。一个程序中可以定义多个sections,每个sections中又可以定义多个section。同一个sections中section之间处于并行状态。sections与其他sections之间处于串行状态。
如下在程序中定义两段sections,其中每段都有两个section,代码如下:
- //File: SectionsTest.cpp
- #include"stdafx.h"
- #include<omp.h>
- #include<iostream>
- using namespace std;
- void SectionsTest()
- {
- int i;
- #pragma omp parallel num_threads(4)
- {
- #pragma omp sections //第1个sections
- {
- #pragma omp section
- {
- cout<<"section 1 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 2 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- }
- #pragma omp sections //第2个sections
- {
- #pragma omp section
- {
- cout<<"section 3 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 4 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- }
- }
- }
运行程序,其结果有:
section 1 线程ID:0
section 2 线程ID:1
section 3 线程ID:3
section 4 线程ID:1
或者其他的结果,但是都会发现section 1与section 2的线程ID永远都可能相同(除非CPU只支持一个线程,或上面代码中num_threads设置为1),同样,section 3与section 4的线程ID也不可能相同,但是,section 1的线程ID有可能与section 3或section 4的线程ID相同,section 2的线程ID有可能与section 3或section 4的线程ID相同。之所以出现这种现象的原因就是,第一个sections与第二个sections在程序中处于串行,而第一个sections中的section1和section2它们处于并行,第二个sections中的section3和section4也处于并行。上面程序的运行示意图如下图所示:
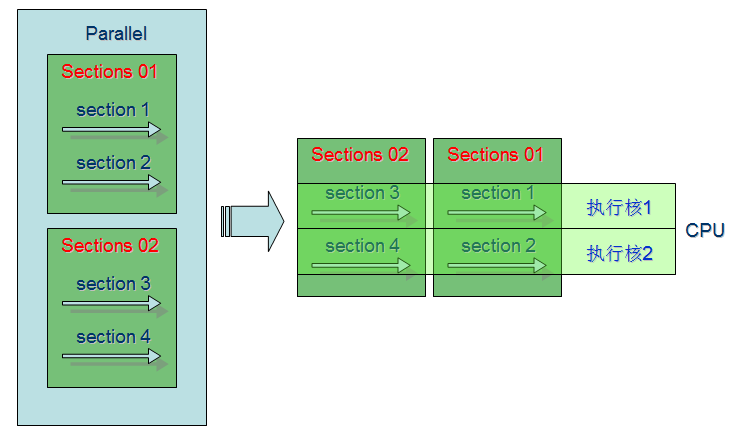
如果将上段程序中num_threads设置为2,则计算结果中线程ID只会是0和1,这样可以更加明确sections之间的运行顺序。
上例中并行是基于每个sections的,如果只有一个sections,其并行定义如下例子的代码:
- //File: SectionsTest02.cpp
- #include"stdafx.h"
- #include<omp.h>
- #include<iostream>
- using namespace std;
- void SectionsTest02()
- {
- #pragma omp parallel sections num_threads(4)
- {
- #pragma omp section
- {
- cout<<"section 1 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 2 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 3 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 4 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- }
- }
运行程序,其结果可能为如下:
section 1 线程ID:0
section 3 线程ID:2
section 2 线程ID:1
section 4 线程ID:3
很明显section1与2、3、4不一定按顺序输出,因为在这里它们已经并行,输出顺序具体要看那个线程先执行完,不像前面的代码中第一个sections肯定是在第二个sections的前面输出。
如果要使sections之间并行,只需要在sections后加上nowait指令即可,如下例子:
- //File: SectionsTest03.cpp
- #include"stdafx.h"
- #include<omp.h>
- #include<iostream>
- using namespace std;
- void SectionsTest03()
- {
- #pragma omp parallel
- {
- #pragma omp sections nowait //第个sections
- {
- #pragma omp section
- {
- cout<<"section 1 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 2 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 3 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- }
- #pragma omp sections //第个sections
- {
- #pragma omp section
- {
- cout<<"section 4 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 5 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- #pragma omp section
- {
- cout<<"section 6 线程ID:"<<omp_get_thread_num()<<"\n";
- }
- }
- }
- }
运行程序,其结果如下:
section 1 线程ID:6
section 5 线程ID:3
section 2 线程ID:1
section 4 线程ID:4
section 3 线程ID:5
section 6 线程ID:2














 3004
3004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









