







Motivation:
一般的抽取式文本摘要方法都是sentence-level的,即对每个句子进行打分,然后选出一些句子来构成摘要。作者通过实验验证了这种sentence-level的抽取式方法可能并不是最优的,因此作者提出一种summary-level的抽取式摘要方法,将文本摘要转化为一个文本匹配问题,使得选出的摘要与原始文档在语义空间中尽可能的相似。
Method
这篇文章其实一共分为两步,第一步是生成候选摘要,第二步是利用文本匹配的方法对候选摘要重排。
第一步生成候选摘要其实还是sentence-level的,首先使用一个content-selection模块( BERTSUM 模型)对文档中的每个句子打分,提取出与文档内容最相关的ext个句子,去掉不相关的句子。然后从这ext个句子中随机选出sel个句子进行组合,并按照原始文档的顺序重新组织,最后一共得到
C
e
x
t
s
e
l
C_{ext}^{sel}
Cextsel个候选
第二步从候选摘要中选出最佳摘要,这一步是summary-level的,使用Siamese-BERT模型对原文档D和候选摘要C进行文本匹配,即用siamese-bert分别将D和C编码成向量,计算编码后的向量的余弦相似度,得到相似度得分
f
(
D
,
C
)
f(D,C)
f(D,C)
训练时的损失函数公式如下:
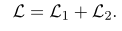
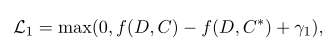
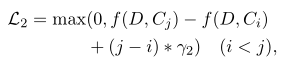
这里的候选摘要按照rouge得分降序排序
目标是使得参考摘要得分最高,同时使得越好的摘要相似度得分越高。














 2916
2916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









