









Generating SOAP Notes from Doctor-Patient Conversations Using Modular Summarization Techniques
Link
https://aclanthology.org/2021.acl-long.384/
Motivation
作者提出医疗报告应该是SOAP结构,包含4部分内容:
(S)subjective information reported by the patient(病人自己说的信息)
(O) objective observations(客观的观察,比如说一些化验,CT的结果)
(A) assessments made by the doctor(医生的诊断结果)
§ plan for future care(未来的计划,比如怎么治疗,用什么药物)
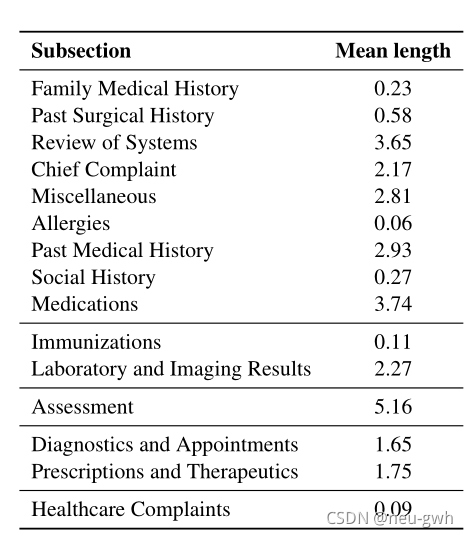
这四个部分又可以进一步细分为若干个子部分,比如S部分可以细分为家族患病史、主要症状等等。
这篇文章构造了一个SOAP结构的数据集,包含上千组医患对话以及标注好的SOAP note,每个note包含最多15个子部分,如下图所示,当然,某一子部分也可以没有,每个子部分包含若干个语句,同时标记出了每个子部分中的重要语句,称为 supporting utterances,包含了这部分的关键信息。
然后针对这个问题,提出了四种extractive和abstractive相结合的算法,首先从文本中抽取出一些关键句子,然后再生成最终的摘要。这四种算法对extraction的依赖程度越来越高,效果也越来越好
Method
文章提出了四种方法
(1) CONV2NOTE
完全abstractive的方法,直接从整个对话中生成note,这里使用pointer-generator模型
(2) EXT2NOTE
首先从对话中抽取出关键句子,然后利用这些关键句子生成最终的摘要。这里使用层次化LSTM模型和BERT模型抽取句子,可以看成一个二分类问题,预测每个句子是否是关键句子。使用pointer-generator生成摘要。
(3)EXT2SEC
抽取出每个子部分(sub section)的关键句子,对于每个子部分,利用这些关键句子生成这部分的摘要
抽取器和EXT2NOTE一样,不同点在于这里不是一个二分类问题,而是一个多标签的输出,预测这个句子对于每个子部分是不是关键句子,一个句子可能对于多个子部分都是关键句子。使用T5模型生成摘要,以对应的子部分为条件。
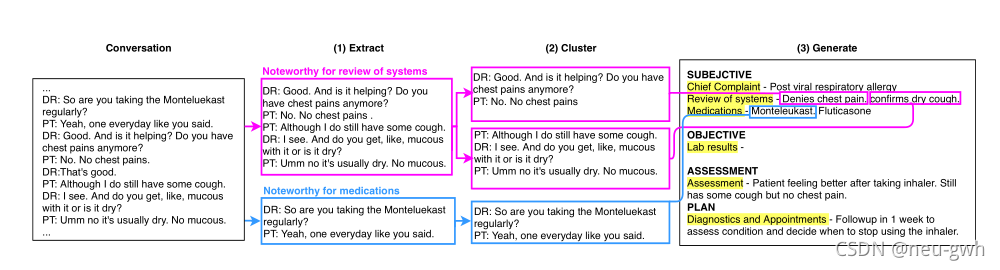
(4)CLUSTER2SENT
对于每个子部分首先抽取出关键句子,然后再对抽取出的关键句子进行聚类,每一类对应于摘要中的一句话。解码器一次生成一个句子,以对应的子部分和聚类为条件。总体流程如下图所示,抽取器和生成器与EXT2SEC一样,聚类采用简单的启发式规则。
这四种模型从abstractive-heavy到extract-heavy,表现越来越好。
Code
https://github.com/acmi-lab/modular-summarization
Summarizing Medical Conversationsvia Identifying Important Utterances
Link
https://www.aclweb.org/anthology/2020.coling-main.63/
Motivation
这篇文章重点关注从医疗对话中抽取出患者的问题以及医生的诊断结果和治疗建议,进而形成高质量的医疗对话摘要。这篇文章通过爬虫构建了一个中文的医疗对话摘要数据集。下图给出了一个示例,每段对话都被切分成多个片段,每个片段都有一个标签,如下图所示,PD代表problem description(问题描述),DT代表diagnosis or treatment(诊断和治疗),OT代表others(其他)。每段对话对应两个摘要,SUM1是患者问题的摘要,是从对话中直接抽取出来的(PD)标签,SUM2是治疗和诊断的摘要,包含两种,SUM2A是直接从对话中提取出来的(DT)标签,SUM2B是医生自己写的概括性比较强。所有的对话都有SUM1和SUM2A,只有一小部分对话有SUM2B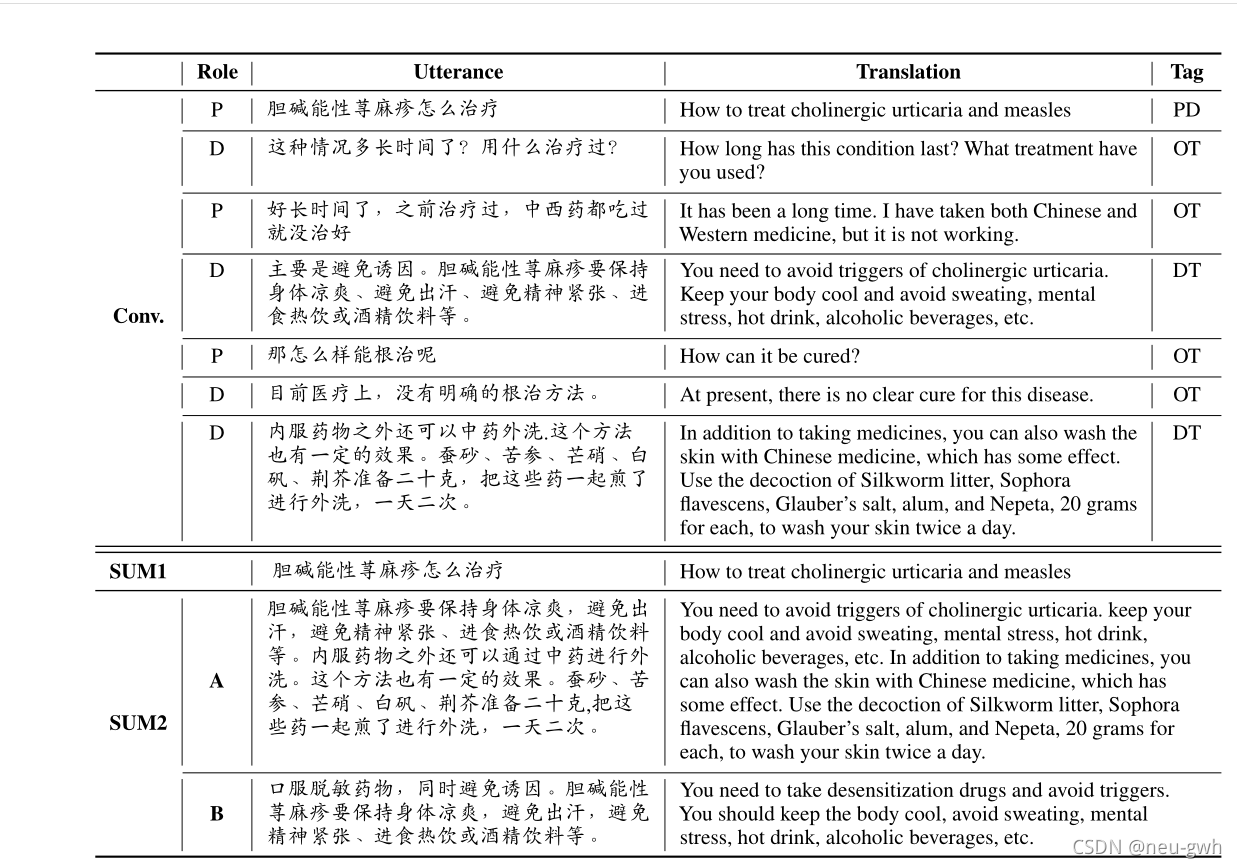
针对这个问题,作者设计了一个hierarchical encoder-tagger model (HET),给对话中的每个句子打上标签,将所有PD的句子拼接在一起得到SUM1,也就是患者问题,将所有DT的句子拼接在一起得到SUM2,也就是治疗和诊断结果。
Method
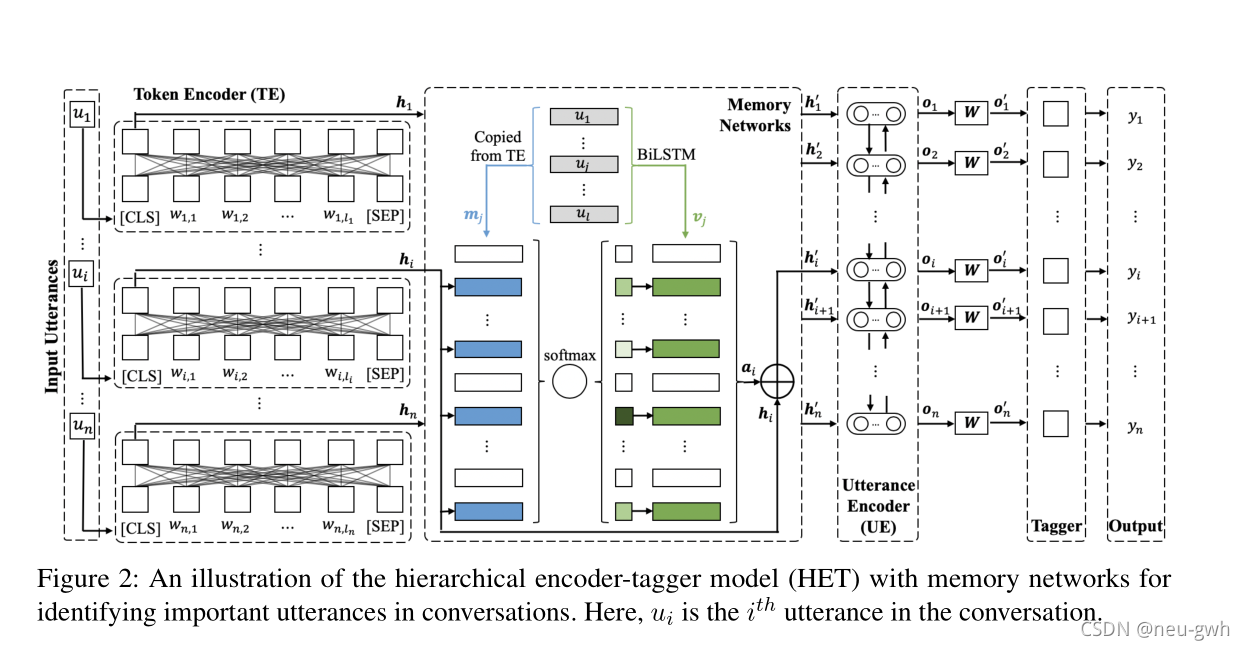
上图给出了模型的总体架构,输入utterance
u
=
[
u
1
,
u
2
,
.
.
.
u
n
]
u=[u_1,u_2,...u_n]
u=[u1,u2,...un],首先经过一个Token Encoder编码(BERT),取CLS位置的编码结果
h
i
h_i
hi作为
u
i
u_i
ui的表示。
然后通过一个Memory NetWork,将与utterance
u
i
u_i
ui相关的信息整合在一起。首先把所有的utterance
[
u
1
.
u
2
,
.
.
.
u
n
]
[u_1.u_2,...u_n]
[u1.u2,...un]映射为memory向量和vector向量,memory向量直接从Token Encoder编码的结果中复制得到,vector向量经过双向LSTM编码得到,通过计算加权和的方式得到最终表示
a
i
a_i
ai,将
h
i
h_i
hi与
a
i
a_i
ai拼接在一起,再经过Utterance Encoder,tagger layer得到表示
o
i
′
o_{i}^{\prime}
oi′,最后通过softmax或者CRF层得到对应的标签。
最后将PD或DT标签对应的句子拼接在一起得到SUM1或者SUM2

















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









