







一、基本概念
1 学习的概念
1975年图灵奖获得者、1978年诺贝尔经济学奖获得者、著名学者赫伯特.西蒙 (Herbert Simon) 曾下过一个定义:
如果一个系统,能够通过执行某个过程,就此改进了它的性能,那么这个过程就是学习.由此可看出,学习的目的就是改善性能.卡耐基梅隆大学机器学习和人工智能教授汤姆.米切尔 (TomMitchell) 在他的经典教材《机器学习》中,给出了更为具体的定义对于某类任务 (Task,简称T) 和某项性能评价准则 (Performance简称P),如果一个计算机在程序
T上,以P作为性能度量,随着经验(Experience,简称E) 的积累,不断自我完善,那么我们称计算机程序从经验E中进行了学习.
2. 为什么需要机器学习
- 程序自我升级;
- 解决那些算法过于复杂,甚至没有已知算法的问题;
- 在机器学习的过程中,协助人类获得事物的洞见。
3. 机器学习的形式
3.1 建模问题
所谓机器学习,在形式上可近似等同于在数据对象中通过统计、推理的方法,来寻找一个接受特定输入X,并给出预期输出Y功能函数f,即Y=f(a)这个函数以及确定函数的参数被称为模型。
3.2 评估问题
针对已知的输入,函数给出的输出 (预测值) 与实际输出 (目标值)之间存在一定误差,因此需要构建一个评估体系,根据误差大小判定函数的优劣。
3.3 优化问题
学习的核心在于改善性能,通过数据对算法的反复锤炼不断提升函数预测的准确性,直至获得能够满足实际需求的最优解,这个过程就是机器学习。
4. 机器学习的分类
4.1 有监督、无监督、半监督学习
1)有监督学习
在已知数据输出(经过标注的)的情况下对模型进行训练,根据输出进行调整、优化的学习方式称为有监督学习。
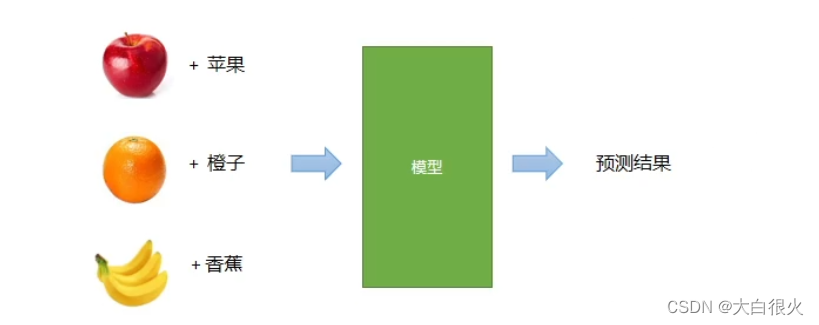
2)无监督学习
没有已知输出的情况下,仅仅根据输入信息的相关性,进行类别的划分。
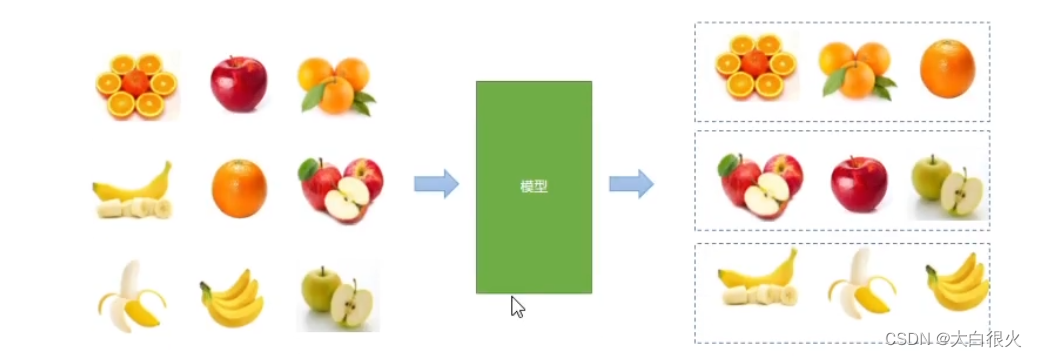
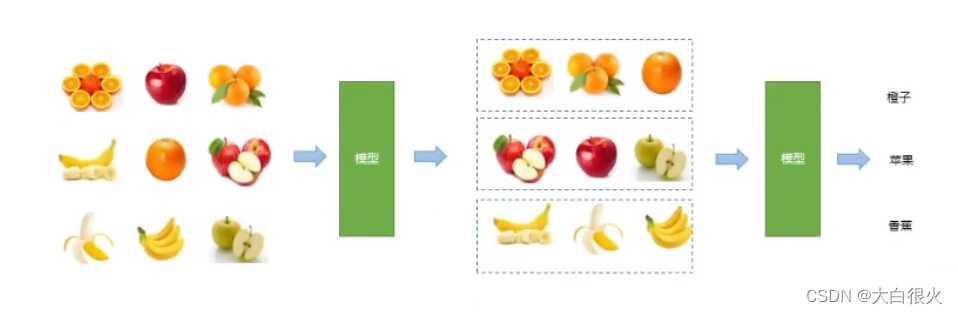
3)半监督学习
先通过无监督学习划分类别,再人工标记通过有监督学习方式来预测输出.例如先对相似的水果进行聚类,再识别是哪个类别。
4)强化学习
通过对不同决策结果的奖励、惩罚,使机器学习系统在经过足够长时间的训练以后,越来越倾向于接近期望结果的输出。
4.2 批量学习、增量学习
1)批量学习
将学习过程和应用过程分开,用全部训练数据训练模型,然后再在应用场景中进行预测,当预测结果不够理想时,重新回到学习过程,如此循环.
2)增量学习
将学习过程和应用过程统一起来,在应用的同时,以增量的方式不断学习新的内容,边训练、边预测.
4.3 基于模型学习、基于实例学习
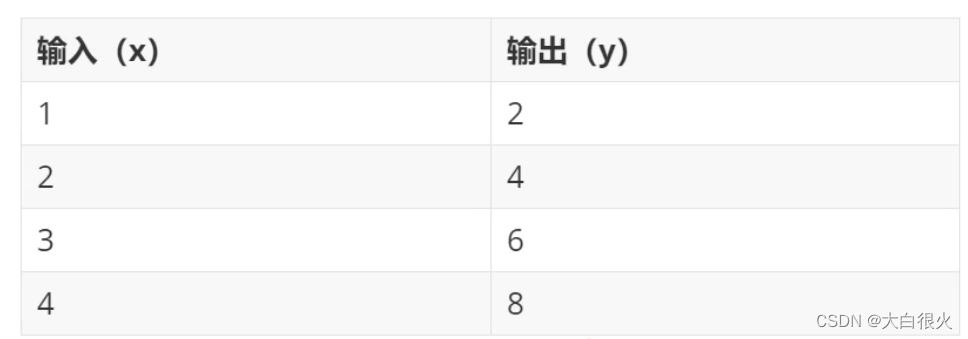
1) 基于模型学习
根据样本数据,建立用于联系输出和输出的某种数学模型,将待预测输入带入该模型,预测其结果.例如有如下输入输出关系:
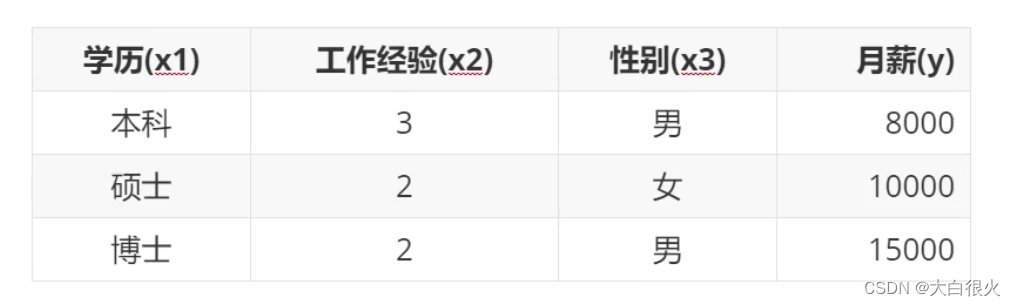
2)基于实例的学习
根据以往经验,寻找与待预测输入最接近的样本,以其输出作为预测结果(从数据中心找答案)例如有如下一组数据:
5. 机器学习的一般过程
- 数据收集,手段如手工采集、设备自动化采集、爬虫等
- 数据清洗:数据规范、具有较大误差的、没有意义的数据进行清理注:以上称之为数据处理,包括数据检索、数据挖掘、爬虫…
- 选择模型 (算法)
- 训练模型
- 模型评估
- 测试模型
注:3~6步主要是机器学习过程,包括算法、框架、工具等… - 应用模型
- 模型维护
6. 机器学习的基本问题
1)回归问题
根据已知的输入和输出,寻找某种性能最佳的模型,将未知输出的输入代入模型,得到连续的输出.
例如:
- 根据房屋面积、地段、修建年代以及其它条件预测房屋价格;
- 根据各种外部条件预测某支股票的价格;
- 根据农业、气象等数据预测粮食收成;
- 计算两个人脸的相似度。
2) 分类问题
根据已知的输入和输出,寻找性能最佳的模型,将未知输出的输入带入模型,得到离散的输出,例如:
- 手写体识别 (10个类别分类问题;
- 水果、鲜花、动物识别;
- 工业产品瑕疵检测(良品、次品二分类问题)识别一个句子表达的情绪(正面、负面、中性)。
3)聚类问题
根据已知输入的相似程度,将其划分为不同的群落,例如:。根据一批麦粒的数据,判断哪些属于同一个品种根据客户在电商网站的浏览和购买历史,判断哪些客户对某件商占感兴趣判断哪些客户具有更高的相似度。
4)降维问题
在性能损失尽可能小的情况下,降低数据的复杂度,数据规模缩小都称为降维问题。
二、数据预处理
1. 数据预处理目的
- 去除无效数据、不规范数据、错误数据
- 补齐缺失值
- 对数据范围、量纲、格式、类型进行统一化处理,更容易进行后续计算
2. 预处理方法
1)标准化(均值移除)
numpy实现
import numpy as np
data = np.array([[12.0, 59.0, 113.0],
[9.0, 61.0, 132.0],
[15.0, 66.0, 102.0]])
for col in data.T:
col_mean = col.mean()
col_std = col.std()
col -= col_mean
col /= col_std
print(data)
print(np.mean(data, axis=0))
print(np.std(data, axis=0 ))
# 输出
[[ 0. -1.01904933 -0.21519688]
[-1.22474487 -0.33968311 1.31808087]
[ 1.22474487 1.35873244 -1.102884 ]]
[ 0.00000000e+00 0.00000000e+00 -3.70074342e-16]
[1. 1. 1.]
sklearn实现
import numpy as np
import sklearn.preprocessing as sp
data = np.array([[12.0, 59.0, 113.0],
[9.0, 61.0, 132.0],
[15.0, 66.0, 102.0]])
res = sp.scale(data)
print(res)
# 输出
[[ 0. -1.01904933 -0.21519688]
[-1.22474487 -0.33968311 1.31808087]
[ 1.22474487 1.35873244 -1.102884 ]]
2)范围缩放
把数据缩放到一定范围,常用的是[0, 1]
import numpy as np
import sklearn.preprocessing as sp
data = np.array([[12.0, 59.0, 113.0],
[9.0, 61.0, 132.0],
[15.0, 66.0, 102.0]])
data2 = data.copy()
# 手动实现
for col in data.T:
col_max = np.max(col)
col_min = np.min(col)
col -= col_min
col /= (col_max - col_min)
print(data)
# 使用sklearn
mms = sp.MinMaxScaler(feature_range=(0, 1))
res = mms.fit_transform(data2)
print(res)
# 输出
[[0.5 0. 0.36666667]
[0. 0.28571429 1. ]
[1. 1. 0. ]]
[[0.5 0. 0.36666667]
[0. 0.28571429 1. ]
[1. 1. 0. ]]
3) 归一化
反映样本所占比率用每个样本的每个特征值,除以该样本各个特征值绝对值之和.变换后的样本矩阵,每个样本的特征值绝对值之和为1.例如如下反映编程语言热度的样本中,2018年也2017年比较,Python开发人员数量减少了2万,但是所占比率确上升了

import numpy as np
import sklearn.preprocessing as sp
data = np.array([[12.0, 59.0, 113.0],
[9.0, 61.0, 132.0],
[15.0, 66.0, 102.0]])
data_copy = data.copy()
for row in data:
row /= abs(row).sum()
print(data)
res = sp.normalize(data_copy)
print(data)
# 输出
[[0.06521739 0.32065217 0.61413043]
[0.04455446 0.3019802 0.65346535]
[0.08196721 0.36065574 0.55737705]]
[[0.06521739 0.32065217 0.61413043]
[0.04455446 0.3019802 0.65346535]
[0.08196721 0.36065574 0.55737705]]
4)二值化
根据一个事先给定的值,用0和1来表示特征值是否超过闽值.以下是实现二值化预处理的代码
import numpy as np
import sklearn.preprocessing as sp
data = np.array([[12.0, 59.0, 113.0],
[9.0, 61.0, 132.0],
[15.0, 66.0, 102.0]])
data_copy = data.copy()
# 手动实现
data[data < 59] = 0
data[data >= 59] = 1
print(data)
# sklearn
bin = sp.Binarizer(threshold=59)
bin_data = bin.transform(data_copy)
print(bin_data)
# 输出
[[0. 1. 1.]
[0. 1. 1.]
[0. 1. 1.]]
[[0. 0. 1.]
[0. 1. 1.]
[0. 1. 1.]]
二值化编码会导致信息损失,是不可逆的数值转换.如果进行可逆转换,则需要用到独执编码。
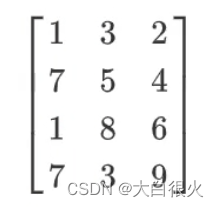
5)独热编码
根据一个特征中不重复值的个数来建立一个由一个1和若干个0组成的序列,用来序列对所有的特征值进行编码.例如有如下样本:
import numpy as np
import sklearn.preprocessing as sp
data = np.array([[12, 59, 113],
[9, 61, 132],
[15, 66, 102]])
data_copy = data.copy()
# 编码
one_hot_encoder = sp.OneHotEncoder()
res = one_hot_encoder.fit_transform(data)
print(res)
# 解码
inv_res = one_hot_encoder.inverse_transform(res)
print(inv_res)
# 输出
(0, 1) 1.0
(0, 3) 1.0
(0, 7) 1.0
(1, 0) 1.0
(1, 4) 1.0
(1, 8) 1.0
(2, 2) 1.0
(2, 5) 1.0
(2, 6) 1.0
[[ 12 59 113]
[ 9 61 132]
[ 15 66 102]]
6) 标签编码
根据字符串形式的特征值在特征序列中的位置,来为其指定一个数字标签,用于提供给基于数值算法的学习模型。
import numpy as np
import sklearn.preprocessing as sp
data = np.array(['bmw', 'benzi', 'xm', 'benzi', 'xm'])
data_copy = data.copy()
encoder = sp.LabelEncoder()
res = encoder.fit_transform(data)
print(res)
# 输出 先按ASCII码排序
[1 0 2 0 2]
三、回归问题
3.1 线性回归
线性模型是自然界最简单的模型之一,它描述了一个 (或多个) 自变量对另一个因变量的影响是呈简单的比例、线性关系.例如:
- 住房每平米单价为1万元,100平米住房价格为100万元,120平米住房为120万元
- 一台挖掘机每小时挖100m3沙土,工作4小时可以挖掘400m沙土
-线性模型在二维空间内表现为一条直线,在三维空间内表现为一个平面,更高维度下的线性模型很难用几何图形来表示(称为超平面).
1 模型定义

2 模型训练
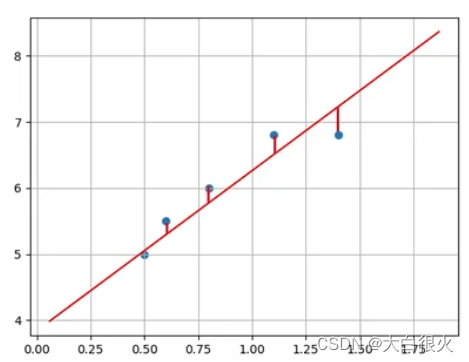
在二维平面中,给定两点可以确定一条直线。但在实际工程中,可能有很多个样本点,无法找到一条直线精确穿过所有样本点,只能找到一条与样本”足够接近“或”距离足够小”的直线,近似拟合给定的样本如下图所示:
1)损失函数
损失函数用来度量真实值(由样本中给出)和预测值(由模型算出)之间的差异。损失函数值越小,表明模型预测值和真实值之间差异越小,模型性能越好;损失函数值越大,模型预测值和真实值之间差异越夫,模型性能越差。在回归问题中,均方差是常用的损失函数,其表达式如下所示:
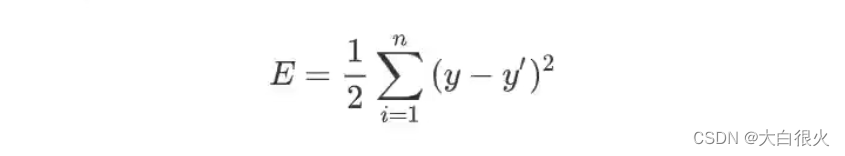
损失函数用来度量真实值(由样本中给出)和预测值(由模型算出)之间的差异.损失函数值越小,表明模型预测值和真实值之间差异越小,模型性能越好;损失函数值越大,模型预测值和真实值之间差异越夫,模型性能越差.在回归问题中,均方差是常用的损失函数,其表达式如下所示
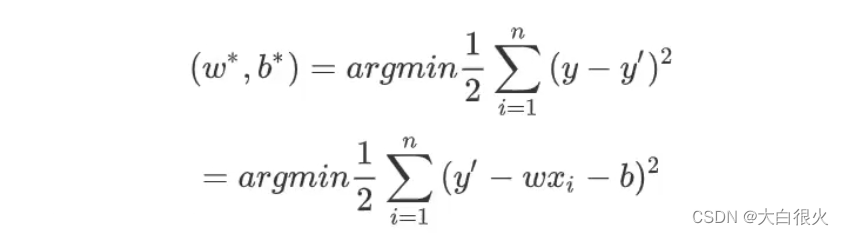
基于均方误差最小化来进行模型求解的方法称为“最小二乘法”.线性回归中,最小二乘法就是试图找到一条直线,是所有样本到直线的欧式距离之和最小.可以将损失函数对w和b分别求导,得到损失函数的导函数,并令导函数为0即可得到w和b的最优解
2)梯度下降法
(1) 为什么使用梯度下降
在实际计算中,通过最小二乘法求解最优参数有一定的问题:
- 最小二乘法需要计算逆矩阵,有可能逆矩阵不存在
- 计算逆矩阵非常耗时甚至不可行样本持征效里较多时,所以,在实际计算中,通常采用梯度下降法来求解损失函数的极小值,从而找到模型的最优参数.
(2)什么是梯度下降
梯度 gradient) 是一个向量 (矢量,有方向) ,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大.损失函数沿梯度相反方向收敛最快 (即能最快找到极值点) .当梯度向量为零(或接近于零),说明到达一个极值点,这也是梯度下降算法迭代计算的终止条件.
这种按照负梯度不停地调整函数权值的过程就叫作“梯度下降法”.通过这样的方法,改变权重让损失函数的值下降得更快,进而将值收敛到损失函数的某个极小值.
通过损失函数,我们将“寻找最优参数”问题,转换为了“寻找损失函数最小值”问题.梯度下降法算法描述如下
(1)损失是否足够小?如果不是,计算损失函数的梯度
(2)按梯度的反方向走一小步,以缩小损失
(3) 循环到 (1)
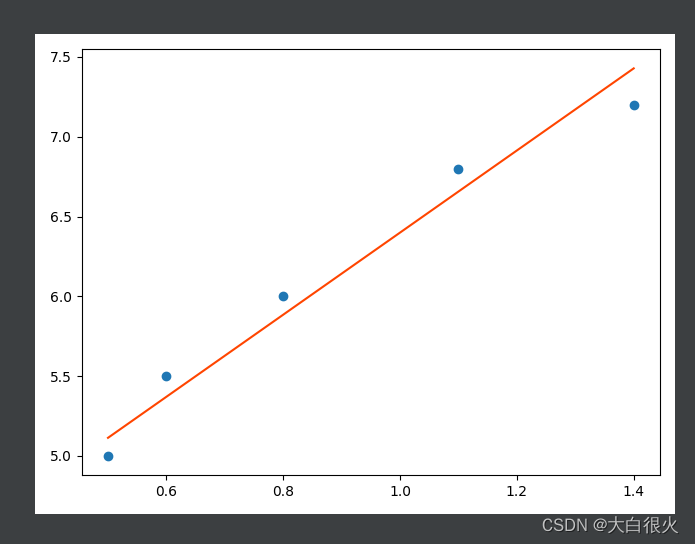
3)基础代码—— 实例
import numpy as np
import matplotlib.pyplot as plt
x = np.array([0.5, 0.6, 0.8, 1.1, 1.4])
y = np.array([5.0, 5.5, 6.0, 6.8, 7.2])
# 超参数设置
learning_rate = 0.01
epoch = 500
# 模型参数设置
w0 = 1
w1 = 1
for c in range(epoch):
loss = ((y - w1 * x - w0)**2).sum() / 2
print("epoch: {}, w0: {:.8f}, w1: {:.8f}, loss: {:.8f}.".format(c+1, w0, w1, loss))
d0 = (w0 + w1 * x - y).sum()
d1 = (x * (w1 * x + w0 - y)).sum()
w0 = w0 - learning_rate * d0
w1 = w1 - learning_rate * d1
y_pred = x * w1 + w0
plt.plot(x, y_pred, c="orangered")
plt.scatter(x, y)
plt.show()
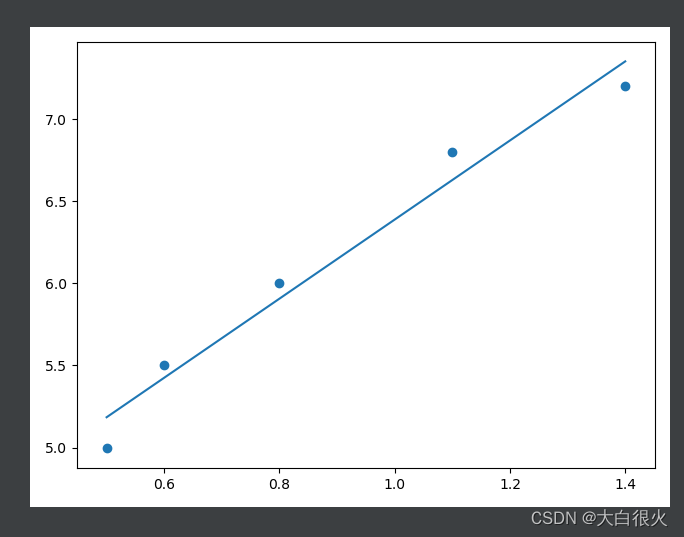
4)使用接口-实例
import numpy as np
import matplotlib.pyplot as plt
import sklearn.linear_model as lm
x = np.array([0.5, 0.6, 0.8, 1.1, 1.4])
x = x.reshape(5, 1)
y = np.array([5.0, 5.5, 6.0, 6.8, 7.2])
model = lm.LinearRegression()
model.fit(x, y)
y_pred = model.predict(x)
plt.scatter(x, y)
plt.plot(x, y_pred)
plt.show()
3 模型评估
1) 平均绝对值误差
2) 均方误差
3)中位数绝对偏差
4)R2评分
# 模型评估模块
import sklearn.metrics as sm
# 平均绝对值误差 MAE(mean absolute error)
mae = sm.mean_absolute_error(y, y_pred)
print("平均绝对误差:", mae)
# 均方误差
mse = sm.mean_squared_error(y, y_pred)
print("均方误差:", mse)
# 中位数绝对偏差
Mae = sm.median_absolute_error(y, y_pred)
print("中位数绝对偏差:", Mae)
# R2评分
R2 = sm.r2_score(y, y_pred)
print("r2_score:", R2)
4 模型的保存与加载
import numpy as np
import matplotlib.pyplot as plt
import sklearn.linear_model as lm
x = np.array([0.5, 0.6, 0.8, 1.1, 1.4])
x = x.reshape(5, 1)
y = np.array([5.0, 5.5, 6.0, 6.8, 7.2])
model = lm.LinearRegression()
model.fit(x, y)
y_pred = model.predict(x)
print(y_pred)
plt.scatter(x, y)
plt.plot(x, y_pred)
plt.show()
#
import pickle
# 保存模型
# pickle.dump(模型对象, 文件对象)
with open('model.pickle', 'wb') as f:
pickle.dump(model, f)
# 加载模型
# pickle.loads(文件对象)
# 模型的加载
with open('./model.pickle', 'rb') as f:
new_model = pickle.load(f)
py = new_model.predict(x)
print(py)
在上一小节多项式回归示例中,多项特征扩展器PolynomialFeatures()进行多项式扩展时,指定了最高次数为3该参数为多项式扩展的重要参数,如果选取不当,则可能导致不同的拟合效果下图显示了该参数分别设为1、20时模型的拟合图像
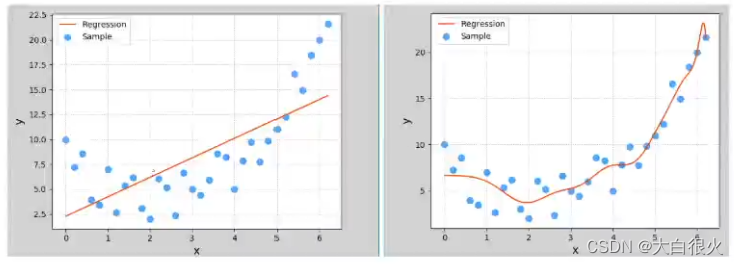
这两种其实都不是好的模型.前者没有学习到数据分布规律,模型拟合程度不够,预测准确度过低,这种现象称为“欠拟合”;后者过于拟合更多样本,以致模型泛化能力(新样本的适应性)变差,这种现象称为“过拟合”拟合模型一般表现为训练集、测试集下准确度都比较低;过拟合模型一般表现为训练集下准确度较高、测试集下准确度较低。一个好的模型,不论是对于训练数据还是测试数据,都有接近的预测精度,而且精度不能太低
3.2 线性回归的模型变种
1 正则化
1) 什么是正则化
过拟合还有一个常见的原因,就是模型参数值太大,所以可以通过抑制参数的方式来解决过拟合问题.如下图所示,右图产生了一定程度过拟合,可以通过弱化高次项的系数(但不删除)来降低过拟合。
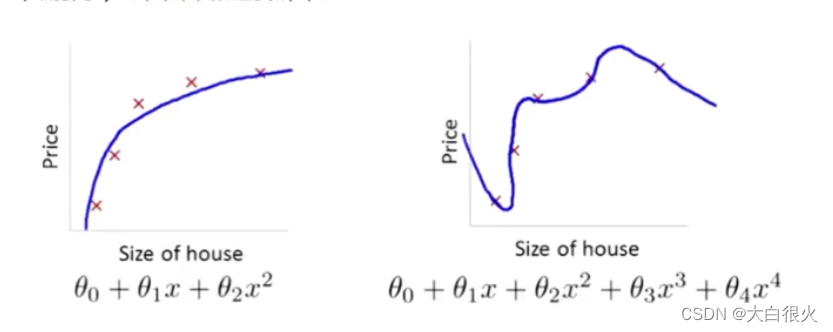
例如,可以通过在
θ
3
\theta_3
θ3,
θ
4
\theta_4
θ4 的系数上添加一定的系数,来压制这两个高次项的系数,这种方法称为正则化.但在实际问题中,可能有更多的系数,我们并不知道应该压制哪些系数所以,可以通过收缩所有系数来避免过拟合
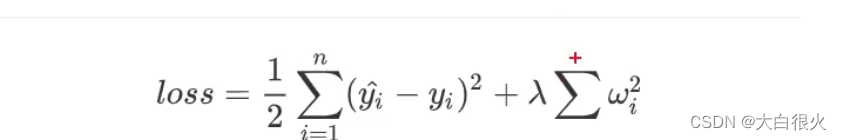
2) 正则化的定义
正则化是指,在目标函数后面添加一个范数,来防止过拟合的手段,这个范数定义为
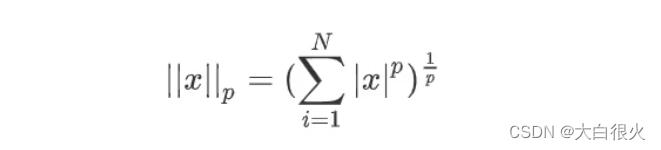
当p=1时,称为L1范数(即所有系数绝对值之和)
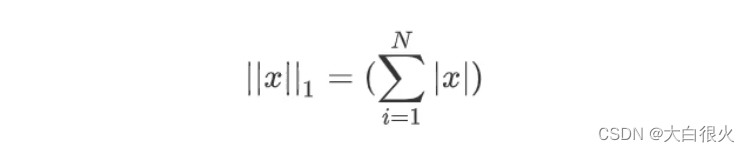
当p=2是,称为L2范数 (即所有系数平方之和再开方)
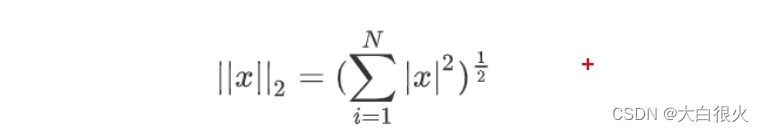
通过对目标函数添加正则项,整体上压缩了参数的大小,从而防止过拟合。
2 Lasso回归和岭回归
Lasso 回归和岭回归(Ridge Regression)都是在标准线性回归的基础上修改了损失函数的回归算法。Lasso回归全称为Least absolute shrinkage and selection operator,又译“最小绝对值收敛和选择算子”、“套索算法”,其损失函数如下所示:
Lasso回归损失函数为:
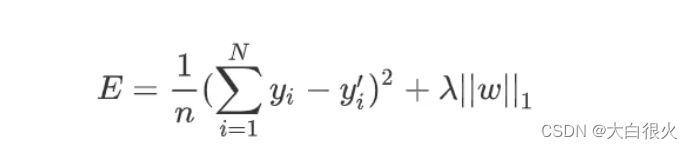
岭回归损失函数为:
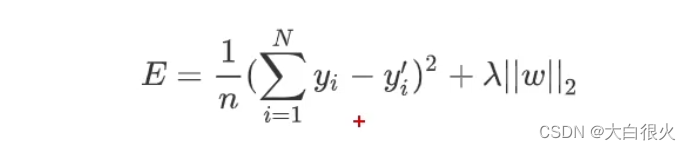
从逻辑上说,Lasso回归和岭回归都可以理解为通过调整损失函数,减小函数的系数,从而避免过于拟合于样本,降低偏差较大的样本的权重和对模型的影响程度。
1)岭回归和Lasso回归——sklearn接口调用实现
import numpy as np
import matplotlib.pyplot as plt
import sklearn.linear_model as lm
# 1.导入数据
x = np.array([0.5, 0.6, 0.8, 1.1, 1.4, 1.5, 1.7, 1.8])
y = np.array([5.0, 5.5, 6.0, 6.8, 7.2, 7.6, 10, 9.9])
# 2.整理数据
x = x.reshape(len(x), 1)
# 3.构建模型
# 3.1 构建线型回归模型
model_linear_regression = lm.LinearRegression()
model_linear_regression.fit(x, y)
y_pred_lr = model_linear_regression.predict(x)
# 3.2 构建岭回归模型
model_ridge_regression = lm.Ridge()
model_ridge_regression.fit(x, y)
y_pred_rr = model_ridge_regression.predict(x)
print(y_pred_rr)
# 3.3 构建Lasso回归模型
model_lasso_regression = lm.Lasso(alpha=0.1)
model_lasso_regression.fit(x, y)
y_pred_lsr = model_lasso_regression.predict(x)
print(y_pred_lsr)
# 6.模型可视化
plt.scatter(x, y)
plt.plot(x, y_pred_lr, c="orangered")
plt.plot(x, y_pred_rr)
plt.plot(x, y_pred_lsr, c="purple")
plt.show()
2)超参数选择——基础代码实现
import sklearn.linear_model as lm
import sklearn.metrics as ms
import pandas as pd
import numpy as np
# 1.导入数据
x = np.array([0.5, 0.6, 0.8, 1.1, 1.4, 1.5, 1.7, 1.8])
y = np.array([5.0, 5.5, 6.0, 6.8, 7.2, 7.6, 10, 9.9])
# 2.整理数据
x = x.reshape(len(x), 1)
scores = []
for param in range(1, 2000):
model = lm.Ridge(alpha=param/10)
model.fit(x, y)
y_pred = model.predict(x)
r2_score = ms.r2_score(y, y_pred)
scores.append(r2_score)
# print(param/100, r2_score)
data = pd.DataFrame(scores, index=[i/10 for i in range(1, 2000)])
print(data.idxmax().values, data.max())
3.3 多项式回归
1 什么是多项式回归
线性回归适用于数据呈线性分布的回归问题.如果数据样本呈明显非线性分布,线性回归模型就不再适用 (下图左)而采用多项式回归可能更好 (下图右) .例如
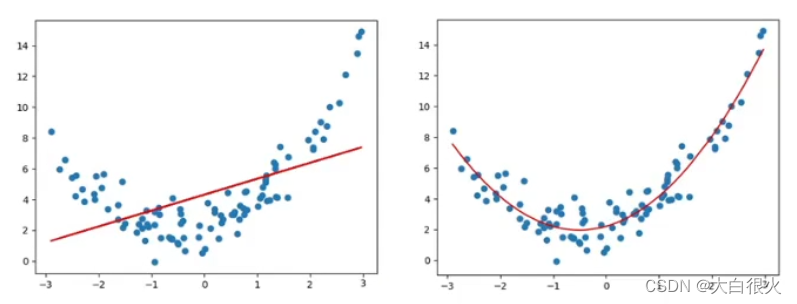
2 多项式模型定义
3 波士顿房价预测实例——线性回归
import sklearn.datasets as sd
import sklearn.linear_model as lm
import sklearn.model_selection as ms
import sklearn.metrics as sm
x = sd.load_boston().data
y = sd.load_boston().target
train_x, test_x, train_y, test_y = ms.train_test_split(x, y, test_size=0.3, random_state=666)
model_lr = lm.LinearRegression()
model_lr.fit(train_x, train_y)
y_train_pred = model_lr.predict(train_x)
y_test_pred = model_lr.predict(test_x)
train_r2 = sm.r2_score(train_y, y_train_pred)
test_r2 = sm.r2_score(test_y, y_test_pred)
print(train_r2, test_r2)
4 波士顿房价预测实例——多项式回归&线性回归
import sklearn.datasets as sd
import sklearn.linear_model as lm
import sklearn.model_selection as ms
import sklearn.metrics as sm
import sklearn.pipeline as sp
import sklearn.preprocessing as spr
x = sd.load_boston().data
y = sd.load_boston().target
train_x, test_x, train_y, test_y = ms.train_test_split(x, y, test_size=0.3, random_state=666)
# 使用线性回归作预测
model_lr = lm.LinearRegression()
model_lr.fit(train_x, train_y)
y_train_pred = model_lr.predict(train_x)
y_test_pred = model_lr.predict(test_x)
train_r2 = sm.r2_score(train_y, y_train_pred)
test_r2 = sm.r2_score(test_y, y_test_pred)
print(train_r2, test_r2)
# 使用多项式回归作预测
model_m = sp.make_pipeline(spr.PolynomialFeatures(2), lm.LinearRegression())
model_m.fit(train_x, train_y)
y_train_pred_mm = model_m.predict(train_x)
y_test_pred_mm = model_m.predict(test_x)
train_r2_mm = sm.r2_score(train_y, y_train_pred_mm)
test_r2_mm = sm.r2_score(test_y, y_test_pred_mm)
print(train_r2_mm, test_r2_mm)
3.4 回归——决策树
决策树既可以作回归,也可以作分类,算法有不同
1 算法基本原理
核心思想:相似的输入必会产生相似的输出。例如预测某人薪资:
首先从训练样本矩阵中选择一个特征进行子表划分,使每个子表中该特征的值全部相同,然后再在每个子表中选择下-个特征按照同样的规则继续划分更小的子表,不断重复直到所有的特征全部使用完为止,此时便得到叶级子表,其中所有样本的特征值全部相同。对于待预测样本,根据其每一个特征的值,选择对应的子表,逐一匹配,直到找到与之完全匹配的叶级子表,用该子表中样本的输出,通过平均(回归)或者投票(分类)为待预测样本提供输出。
首先选择哪一个特征进行子表划分决定了决策树的性能。这么多特征,使用哪个特征先进行子表划分?
sklearn提供的决策树底层为cart树(Classification and Regression Tree) ,cart回归树在解决回归问题时的步骤如
1.原始数据集S,此时树的深度depth=0;
2.针对集合S,遍历每一个特征的每一个value(遍历数据中的所有离散值 )
用该value将原数据集S分裂成2个集合: 左集合
终止条件有如下几种:
1、特征已经用完了:没有可供使用的特征再进行分裂了则树停止分裂;
2、子节点中没有样本了: 此时该结点已经没有样本可供划分,该结点停止分裂;
3、树达到了人为预先设定的最大深度: depth >=max_depth,树停止分裂。4、节点的样本数量达到了人为设定的闯值: 样本数量 <min_samples_split ,则该节点停止分裂:
决策树面临的关键问题:
问题1:优先选择哪个特征进行划分决定了决策树的性能。
2 实例
import sklearn.datasets as sd
import sklearn.linear_model as lm
import sklearn.model_selection as ms
import sklearn.metrics as sm
import sklearn.pipeline as sp
import sklearn.preprocessing as spr
import sklearn.tree as st
x = sd.load_boston().data
y = sd.load_boston().target
train_x, test_x, train_y, test_y = ms.train_test_split(x, y, test_size=0.2, random_state=7)
# 使用线性回归作预测
model_lr = lm.LinearRegression()
model_lr.fit(train_x, train_y)
y_train_pred = model_lr.predict(train_x)
y_test_pred = model_lr.predict(test_x)
train_r2 = sm.r2_score(train_y, y_train_pred)
test_r2 = sm.r2_score(test_y, y_test_pred)
print("线性回归r2: ", train_r2, test_r2)
# 使用多项式回归作预测
model_m = sp.make_pipeline(spr.PolynomialFeatures(2), lm.LinearRegression())
model_m.fit(train_x, train_y)
y_train_pred_mm = model_m.predict(train_x)
y_test_pred_mm = model_m.predict(test_x)
train_r2_mm = sm.r2_score(train_y, y_train_pred_mm)
test_r2_mm = sm.r2_score(test_y, y_test_pred_mm)
print("多项式回归r2: ", train_r2_mm, test_r2_mm)
# 决策树回归
model_st = st.DecisionTreeRegressor(max_depth=6)
model_st.fit(train_x, train_y)
y_train_pred_st = model_st.predict(train_x)
y_test_pred_st = model_st.predict(test_x)
train_r2_st = sm.r2_score(train_y, y_train_pred_st)
test_r2_st = sm.r2_score(test_y, y_test_pred_st)
print("决策树回归r2: ", train_r2_st, test_r2_st)
3 集合算法
单个模型得到的预测结果总是片面的,根据多个不同模型给出的预测结果,利用平均(回归)或者投票(分类)的方法,得出最终预测结果
基于决策树的集合算法,就是按照某种规则,构建多棵彼此不同的决策树模型,分别给出针对未知样本的预测结果,最后通过平均或投票得到相对综合的结论。常用的集合模型包括Boosting类模型(AdaBoost、GBDT) 与Bagging (自助聚合、随机森林)类模型。
Boosting:下一棵树是在上一棵树的基础上进行提升的。主要有:AdaBoost(提升权重),GBDT(拟合残差 )Bagging:每棵树间没有关系。主要有:随机森林
1) AdaBoost(正向激励)
import sklearn.datasets as sd
import sklearn.linear_model as lm
import sklearn.model_selection as ms
import sklearn.metrics as sm
import sklearn.pipeline as sp
import sklearn.preprocessing as spr
import sklearn.tree as st
import sklearn.ensemble as se
x = sd.load_boston().data
y = sd.load_boston().target
train_x, test_x, train_y, test_y = ms.train_test_split(x, y, test_size=0.2, random_state=7)
# 使用线性回归作预测
model_lr = lm.LinearRegression()
model_lr.fit(train_x, train_y)
y_train_pred = model_lr.predict(train_x)
y_test_pred = model_lr.predict(test_x)
train_r2 = sm.r2_score(train_y, y_train_pred)
test_r2 = sm.r2_score(test_y, y_test_pred)
print("线性回归r2: ", train_r2, test_r2)
# 使用多项式回归作预测
model_m = sp.make_pipeline(spr.PolynomialFeatures(2), lm.LinearRegression())
model_m.fit(train_x, train_y)
y_train_pred_mm = model_m.predict(train_x)
y_test_pred_mm = model_m.predict(test_x)
train_r2_mm = sm.r2_score(train_y, y_train_pred_mm)
test_r2_mm = sm.r2_score(test_y, y_test_pred_mm)
print("多项式回归r2: ", train_r2_mm, test_r2_mm)
# 决策树回归
model_st = st.DecisionTreeRegressor(max_depth=6)
model_st.fit(train_x, train_y)
y_train_pred_st = model_st.predict(train_x)
y_test_pred_st = model_st.predict(test_x)
train_r2_st = sm.r2_score(train_y, y_train_pred_st)
test_r2_st = sm.r2_score(test_y, y_test_pred_st)
print("决策树回归r2: ", train_r2_st, test_r2_st)
# 集成学习-Adaboost
model_ab = st.DecisionTreeRegressor(max_depth=4)
model_ab = se.AdaBoostRegressor(model_ab, n_estimators=400, random_state=7)
model_ab.fit(train_x, train_y)
y_train_pred_ab = model_ab.predict(train_x)
y_test_pred_ab = model_ab.predict(test_x)
train_r2_ab = sm.r2_score(train_y, y_train_pred_ab)
test_r2_ab = sm.r2_score(test_y, y_test_pred_ab)
print("Adaboostr2: ", train_r2_ab, test_r2_ab)
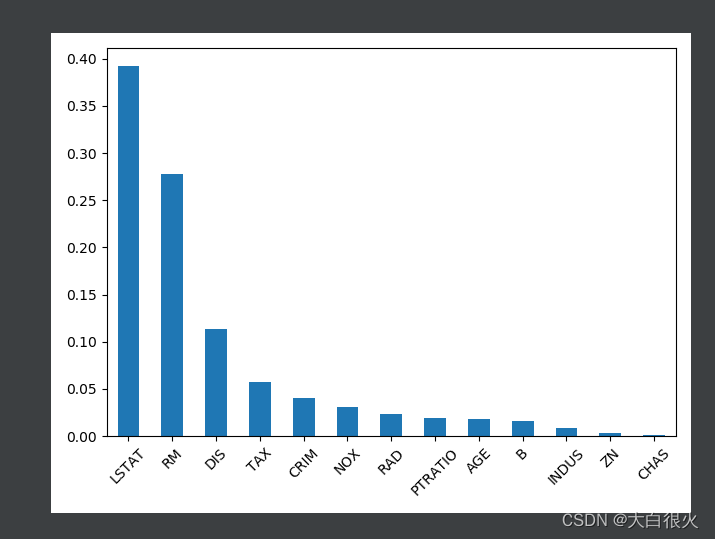
特征重要性
作为决策树模型训练过程的副产品,根据划分子表时选择特征的顺序标志了该特征的重要程度,此即为该特征重要性指标。训练得到的模型对象提供了属性: feature_importances_来存储每个特征的重要性。
获取样本矩阵特征重要性属性
model.fit(train_x,train_y)
fi = model.feature_importances_
import sklearn.datasets as sd
import sklearn.linear_model as lm
import sklearn.model_selection as ms
import sklearn.metrics as sm
import sklearn.pipeline as sp
import sklearn.preprocessing as spr
import sklearn.tree as st
import sklearn.ensemble as se
import pandas as pd
import matplotlib.pyplot as plt
data = sd.load_boston()
x = data.data
y = data.target
train_x, test_x, train_y, test_y = ms.train_test_split(x, y, test_size=0.2, random_state=7)
# 使用线性回归作预测
model_lr = lm.LinearRegression()
model_lr.fit(train_x, train_y)
y_train_pred = model_lr.predict(train_x)
y_test_pred = model_lr.predict(test_x)
train_r2 = sm.r2_score(train_y, y_train_pred)
test_r2 = sm.r2_score(test_y, y_test_pred)
print("线性回归r2: ", train_r2, test_r2)
# 使用多项式回归作预测
model_m = sp.make_pipeline(spr.PolynomialFeatures(2), lm.LinearRegression())
model_m.fit(train_x, train_y)
y_train_pred_mm = model_m.predict(train_x)
y_test_pred_mm = model_m.predict(test_x)
train_r2_mm = sm.r2_score(train_y, y_train_pred_mm)
test_r2_mm = sm.r2_score(test_y, y_test_pred_mm)
print("多项式回归r2: ", train_r2_mm, test_r2_mm)
# 决策树回归
model_st = st.DecisionTreeRegressor(max_depth=6)
model_st.fit(train_x, train_y)
y_train_pred_st = model_st.predict(train_x)
y_test_pred_st = model_st.predict(test_x)
train_r2_st = sm.r2_score(train_y, y_train_pred_st)
test_r2_st = sm.r2_score(test_y, y_test_pred_st)
print("决策树回归r2: ", train_r2_st, test_r2_st)
# 集成学习-Adaboost
model_ab = st.DecisionTreeRegressor(max_depth=4)
model_ab = se.AdaBoostRegressor(model_ab, n_estimators=400, random_state=7)
model_ab.fit(train_x, train_y)
y_train_pred_ab = model_ab.predict(train_x)
y_test_pred_ab = model_ab.predict(test_x)
train_r2_ab = sm.r2_score(train_y, y_train_pred_ab)
test_r2_ab = sm.r2_score(test_y, y_test_pred_ab)
print("Adaboostr2: ", train_r2_ab, test_r2_ab)
# 查看属性的重要性
weights = model_ab.feature_importances_
weights = pd.Series(weights, index=data.feature_names)
print("属性权重: ", weights )
# 权重可视化
weights = weights.sort_values(ascending=False)
weights.plot.bar(rot=45)
plt.show()
2)GBDT
GBDT (Gradient Boosting Decision Tree 梯度提升决策树)通过多轮迭代,每轮迭代产生一弱分类器每个分类器在上一轮分类器的残差(残差在数理统计中是指实际观察值与估计值(拟合值)之间的差)基础上进行训练。基于预测结果的残差设计损失函数。GBDT训练的过程即是求该损失函数最小值的过程。
3)Bagging
(1) 自助聚合
每次从总样本矩阵中以有放回抽样的方式随机抽取部分样本构建决策树,这样形成多棵包含不同训练样本的决策树,以削弱某些强势样本对模型预测结果的影响,提高模型的泛化特性。
sklearn中没有对自助聚合的接口,因为随机森林包括了它。
(2) 随进森林
在自助聚合的基础上,每次构建决策树模型时,不仅随机选择部分样本,而且还随机选择部分特征,这样的集合算法,不仅规避了强势样本对预测结果的影响,而且也削弱了强势特征的影响,使模型的预测能力更加泛化。
import sklearn.ensemble as se
# 随机森林回归模型(属于集合算法的一种)
# max_depth:决策树最大深度10
# n_estimators: 构建1000棵决策树,训练模型
# min_samples_split: 子表中最小样本数 若小于这个数字,则不再继续向下拆分
model = se.RandomForestRegressor(max_depth=10,n_estimators=1000, min_samples_split=2)
优缺点:效果
不是很好,但是泛化能力强。
import sklearn.datasets as sd
import sklearn.linear_model as lm
import sklearn.model_selection as ms
import sklearn.metrics as sm
import sklearn.pipeline as sp
import sklearn.preprocessing as spr
import sklearn.tree as st
import sklearn.ensemble as se
import pandas as pd
import matplotlib.pyplot as plt
data = sd.load_boston()
x = data.data
y = data.target
train_x, test_x, train_y, test_y = ms.train_test_split(x, y, test_size=0.2, random_state=7)
# 使用线性回归作预测
model_lr = lm.LinearRegression()
model_lr.fit(train_x, train_y)
y_train_pred = model_lr.predict(train_x)
y_test_pred = model_lr.predict(test_x)
train_r2 = sm.r2_score(train_y, y_train_pred)
test_r2 = sm.r2_score(test_y, y_test_pred)
print("线性回归r2: ", train_r2, test_r2)
# 使用多项式回归作预测
model_m = sp.make_pipeline(spr.PolynomialFeatures(2), lm.LinearRegression())
model_m.fit(train_x, train_y)
y_train_pred_mm = model_m.predict(train_x)
y_test_pred_mm = model_m.predict(test_x)
train_r2_mm = sm.r2_score(train_y, y_train_pred_mm)
test_r2_mm = sm.r2_score(test_y, y_test_pred_mm)
print("多项式回归r2: ", train_r2_mm, test_r2_mm)
# 决策树回归
model_st = st.DecisionTreeRegressor(max_depth=6)
model_st.fit(train_x, train_y)
y_train_pred_st = model_st.predict(train_x)
y_test_pred_st = model_st.predict(test_x)
train_r2_st = sm.r2_score(train_y, y_train_pred_st)
test_r2_st = sm.r2_score(test_y, y_test_pred_st)
print("决策树回归r2: ", train_r2_st, test_r2_st)
# 集成学习-Adaboost
model_ab = st.DecisionTreeRegressor(max_depth=4)
model_ab = se.AdaBoostRegressor(model_ab, n_estimators=400, random_state=7)
model_ab.fit(train_x, train_y)
y_train_pred_ab = model_ab.predict(train_x)
y_test_pred_ab = model_ab.predict(test_x)
train_r2_ab = sm.r2_score(train_y, y_train_pred_ab)
test_r2_ab = sm.r2_score(test_y, y_test_pred_ab)
print("Adaboostr2: ", train_r2_ab, test_r2_ab)
# 查看属性的重要性
# weights = model_ab.feature_importances_
# weights = pd.Series(weights, index=data.feature_names)
# print("属性权重: ", weights )
#
# # 权重可视化
# weights = weights.sort_values(ascending=False)
# weights.plot.bar(rot=45)
# plt.show()
# 集中学习-GBDT
model_se = se.GradientBoostingRegressor(max_depth=4, n_estimators=400, min_samples_split=5)
model_se.fit(train_x, train_y)
y_pred_train_se = model_se.predict(train_x)
y_pred_test_se = model_se.predict(test_x)
r2_score_train_se = sm.r2_score(train_y, y_pred_train_se)
r2_score_test_se = sm.r2_score(test_y, y_pred_test_se)
print("GBDT: ", r2_score_train_se, r2_score_test_se)
# 集中学习-随机森林
model_rf = se.RandomForestRegressor(max_depth=10, n_estimators=1000, min_samples_split=2)
model_rf.fit(train_x, train_y)
y_pred_train_rf = model_rf.predict(train_x)
y_pred_test_rf = model_rf.predict(test_x)
r2_score_train_rf = sm.r2_score(train_y, y_pred_train_rf)
r2_score_test_rf = sm.r2_score(test_y, y_pred_test_rf)
print("随机森林学习: ", r2_score_train_rf, r2_score_test_rf)
输出:
线性回归r2: 0.7698532963729757 0.5785415472763433
多项式回归r2: 0.9336239312538431 0.6170018543899776
决策树回归r2: 0.9466499293522961 0.6685235944256043
Adaboostr2: 0.9503619697248306 0.8265559366287137
GBDT: 0.9998606157609922 0.8165856254862572
随机森林学习: 0.9772166807225966 0.8147395943502115
四、分类问题
4.1 逻辑回归
逻辑回归是分类模型!!!不是回归模型。
1)什么是逻辑回归?
逻辑回归 (Logistic Regression)虽然被称为回归,但其实际上是分类模型,常用于二分类。逻辑回归因其简单、可并行化、可解释强而受到广泛应用。二分类 (也称为逻辑分类) 是常见的分类方法,是将一批样本或数据划分到两个类别。
2)逻辑函数
逻辑回归是一种广义的线性回归,其原理是利用线性模型根据输入计算输出(线性模型输出值为连续),并在逻辑函数sigmod作用下将连续值转换为两个离散值 (0或1),其表达式如下:
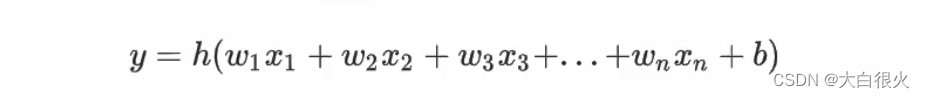
其中,括号中的部分为线性模型,计算结果在函数h0的作用下,做二值化转换,函数h0)的定义为:
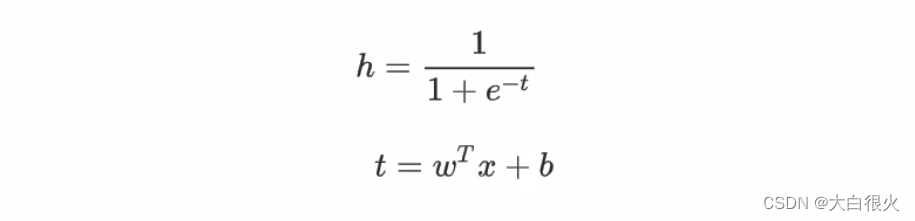
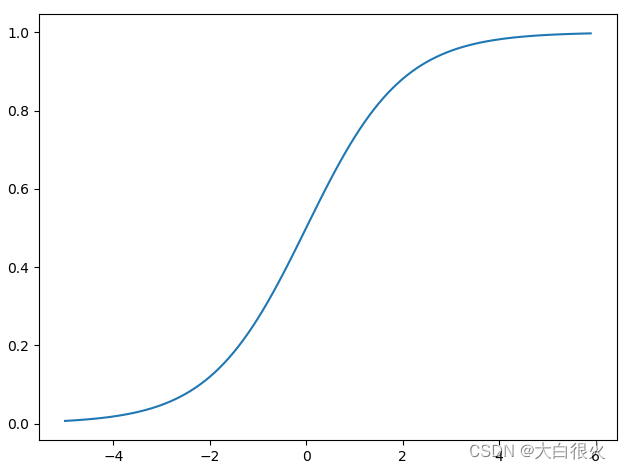
sigmod的作用:
1.将负无穷-正无穷的数值映射到0-1范围内
2.将线性输出转为非线性
3)分类问题的损失函数
对于回归问题,可以使用均方差作为损失函数,对于分类问题如何度量预测值与真实值之间的差异?分类问题采用交叉熵作为损失函数,当只有两个类别时,交叉熵表达式为
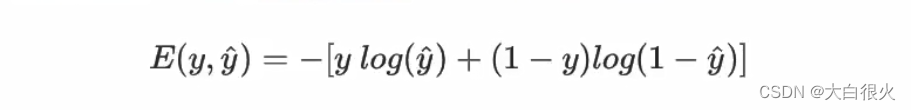
其中,y为真实值,y^为预测值。
- 当y =1时,预测值g越接近于1,log(y^)越接近于0,损失函数值越小,表示误差越小,预测的越准确;当预测时9接近于0时,log( y^ )接近于负无穷大,加上符号后误差越大,表示越不准确;
- 当y =0时,预测值g越接近于0,log(1 -y^ )越接近于,损失函数值越小,表示误差越小,预测越准确;当预测值0接近于1时,log(1-y^)接近于负无穷大,加上符号后误差越大,表示越不准确
4)鸢尾花二分类实现(挑出来)
import matplotlib.pyplot as plt
import numpy as np
import sklearn.datasets as sd
import sklearn.metrics as sm
import sklearn.model_selection as sms
import sklearn.linear_model as sl
data = sd.load_iris()
x = data.data[data.target != 0]
y = data.target[data.target != 0]
x_train, x_test, y_train, y_test = sms.train_test_split(x, y, test_size=0.2, random_state=11)
model_sl = sl.LogisticRegression(solver='liblinear')
model_sl.fit(x_train, y_train)
y_pred_train = model_sl.predict(x_train)
y_pred_test = model_sl.predict(x_test)
# 使用准确率计算
print((y_test == y_pred_test).sum()/y_pred_test.size)
5) 逻辑回归的多分类

4.2 分类——决策树
1 什么是决策树
决策树是一种常见的机器学习方法,其核心思想是相同 (或相似)的输入产生相同(或相似)的输出,通过树状结构来进行决策,其目的是通过对样本不同属性的判断决策,将具有相同属性的样本划分到一个叶子节点下,从而实现分类或回归。
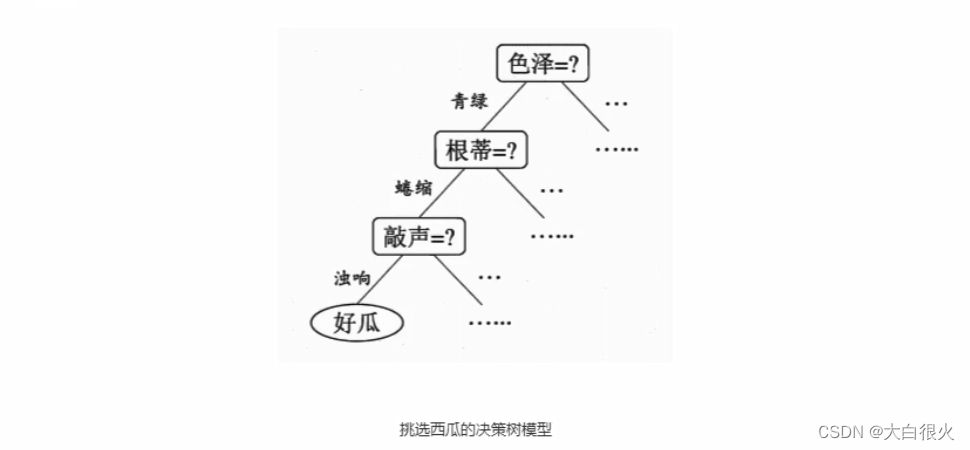
构建决策树的伪代码:

2 如何选择特征
1)信息熵
信息(information entropy) 是度量样本集合纯度的常用指标该值越大,表示该集合纯度越低(或越混乱),该值越小,表示该集合纯度越高(或越有序)信息定义如下:
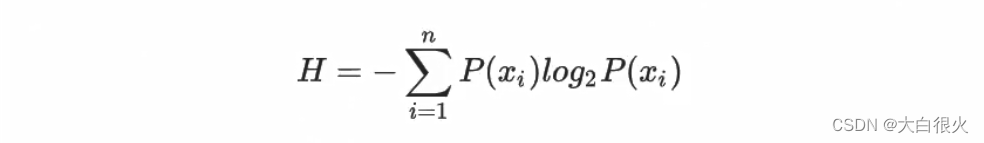
其中,
P
(
x
i
)
P(x_i)
P(xi)表示集合中第i类样本所占比例,当
P
(
x
i
)
P(x_i)
P(xi)为1时(只有一个类别,比例为100%),
l
o
g
2
P
(
x
i
)
log_2P(x_i)
log2P(xi)的值为0,整个系统信息熵为0;当类别越多,则
P
(
x
i
)
P(x_i)
P(xi)的值越接近于0,
l
o
g
2
P
(
x
i
)
log_2P(x_i)
log2P(xi)趋近去负无穷大,整个系统信息熵就越大.以下代码,展示了类别数量从1…10的集合信息熵变化:
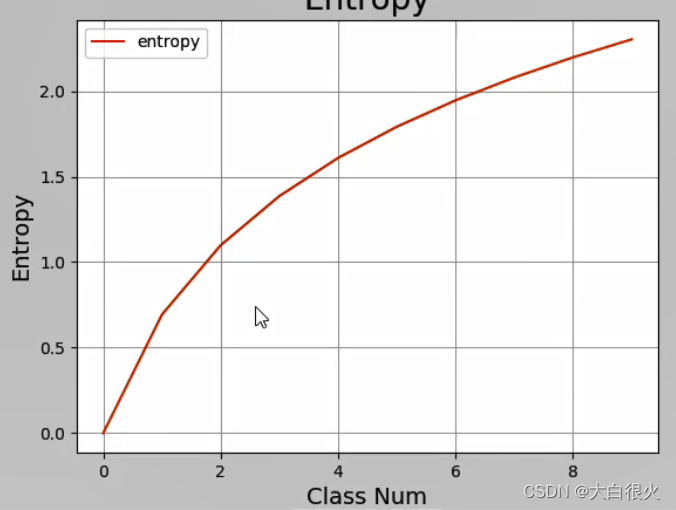
2) 信息增益
决策树根据属性进行判断,将具有相同属性的样本划分到相同节点下,此时,样本比划分之前更加有序(混乱程度降低),信息熵的值有所降低。用划分前的信息熵减去划分后的信息熵,就是决策树
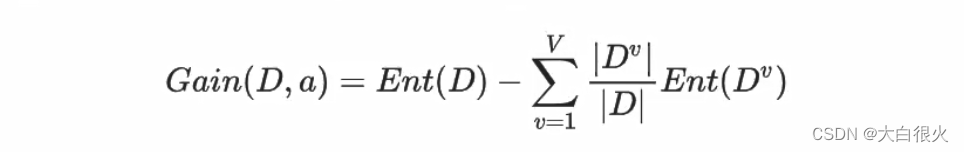
其中,
D
D
D表示样本集合,
a
a
a表示属性,
v
v
v表示属性可能的取值
v
1
v^1
v1,
v
2
v^2
v2,…,
v
n
v^n
vn,
∣
D
v
∣
/
∣
D
∣
|D^v|/|D|
∣Dv∣/∣D∣表示权重,样本越多的分支对分类结果影响更大,赋予更高的权重,
G
a
i
n
(
D
,
a
)
Gain(D,a)
Gain(D,a)表示在样本集合
D
D
D上使用属性
a
a
a来划分子节点所获得的信息增益以下是一个关于信息增益计算的示例:
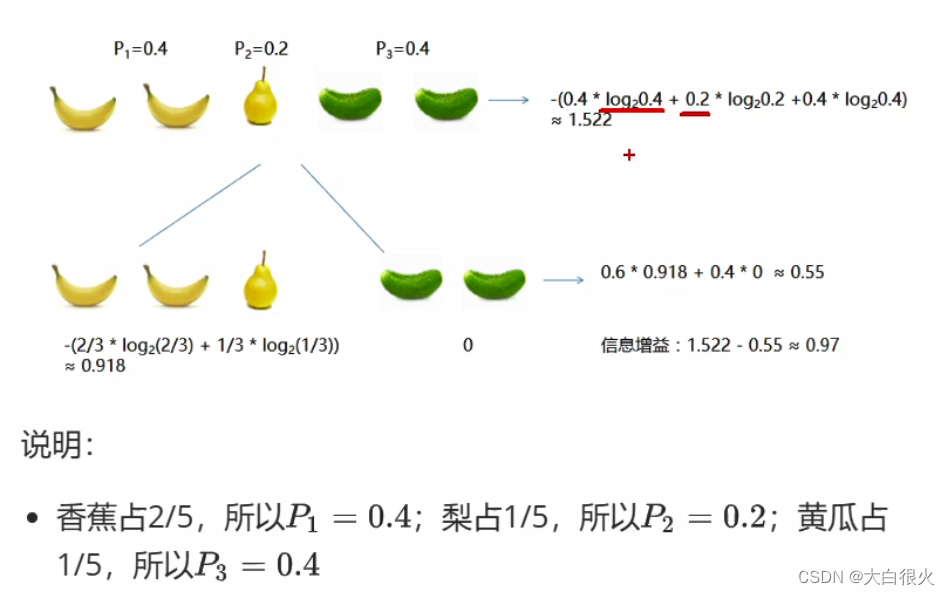

由以上示例可知,经过对样本按颜色进行类别划分,划分后的信息熵比原来下降了,下降的值就是信息增益。一般来说,信息增益越大,以该属性划分所获得的“纯度提升”越大著名的ID3决策树学习算法就是以信息增益为准则来划分属性。
3)增益率
增益率不直接采用信息增益,而采用信息增益与熵值的比率来作为衡量特征优劣的标准C45算法就是使用增益率作为标准来划分属性增益率定义为:
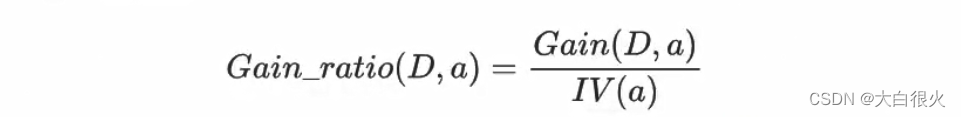
其中
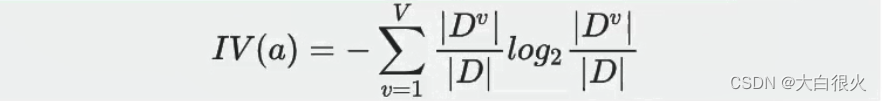
4)基尼系数
基尼系数定义:
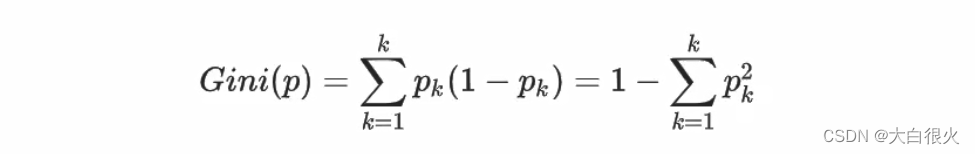
直观来说,基尼系数反映了从数据集D中随机抽取两个样本,类别标记不一致的概率因此,基尼系数越小,数据集的纯度越高.CART决策树(Classification And Regression Tree) 使用基尼系数来选择划分属性,选择属性时,选择划分后基尼值最小的属性作为最优属性采用和上式相同的符号表示,数据集D下属性a的基尼系数定义为:
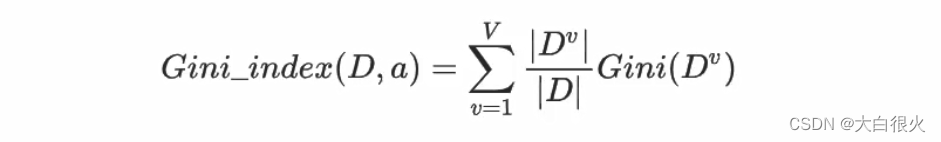
3 决策树的实现
4.3 模型评估及优化
1 模型评估(性能度量)
1)错误率与精度
错误率和精度是分类问题中常用的性能度量指标,既适用于二分类任务,也适用于多分类任务
错误率 (error rate) : 指分类错误的样本占样本总数的比例,即 ( 分类错误的数量 /样本总数数量)
精度 (accuracy) : 指分类正确的样本占样本总数的比例,即(分类正确的数量/样本总数数量)
精度 =1- 错误率
2) 查准率、查全率(召回率)与F1得分
错误率和精度虽然常用,但并不能满足所有的任务需求。例如在一次疾病检测中,我们更关注以下两个问题
- 检测出感染的个体中有多少是真正病毒携带者?。
- 所有真正病毒携带者中,有多大比例被检测了出来?
类似的问题在很多分类场景下都会出现,“查准率”(precision)与“召回率”(recall) 是更为适合的度量标准。对于二分类问题可以将真实类别、预测类别组合为“真正例”(truepositive)、“假正例”(false positive)、“真反例”(truenegative)、“假反例”(false negative) 四种情形,见下表
样例总数: TP + EP + TN + EN
- 查准率: TP /(TP + EP),表示分的准不准
- 召回率: TP /(TP + FN),表示分的全不全,又称为“查全率
- F1得分

查准率和召回率是一对矛盾的度量。一般来说,查准率高时,召向率往往偏低,召回率高时,查准率往往偏低。例如,在病毒感染者检测中,若要提高查准率,只需要采取更严格的标准即可这样会导致漏掉部分感染者,召回率就变低了;反之,放松检测标准,更多的人被检测为感染,召回率升高了,查准率又降低了通常只有在一些简单任务中,才能时获得较高查准率和召回率。
基础代码实现与接口实现
import matplotlib.pyplot as plt
import numpy as np
import sklearn.datasets as sd
import sklearn.metrics as sm
import sklearn.model_selection as sms
import sklearn.linear_model as sl
data = sd.load_iris()
x = data.data
y = data.target
x_train, x_test, y_train, y_test = sms.train_test_split(x, y, test_size=0.1, random_state=7)
model_sl = sl.LogisticRegression(solver='liblinear')
model_sl.fit(x_train, y_train)
y_pred_train = model_sl.predict(x_train)
y_pred_test = model_sl.predict(x_test)
# 使用准确率(精度accuracy)计算
accuracy = sm.accuracy_score(y_test, y_pred_test)
print(accuracy)
print("真实:", y_test)
print("预测:", y_pred_test)
mask_0 = y_test == 0
mask_1 = y_test == 1
mask_2 = y_test == 2
# 查准率——基础代码实现
p0 = (y_test[mask_0] == y_pred_test[mask_0]).sum()/y_pred_test[y_pred_test == 0].size
p1 = (y_test[mask_1] == y_pred_test[mask_1]).sum()/y_pred_test[y_pred_test == 1].size
p2 = (y_test[mask_2] == y_pred_test[mask_2]).sum()/y_pred_test[y_pred_test == 2].size
print(p0, p1, p2)
# 查全率——基础代码实现
r0 = (y_test[mask_0] == y_pred_test[mask_0]).sum()/y_test[mask_0].size
r1 = (y_test[mask_1] == y_pred_test[mask_1]).sum()/y_test[mask_1].size
r2 = (y_test[mask_2] == y_pred_test[mask_2]).sum()/y_test[mask_2].size
print(r0, r1, r2)
# 查准率,查全率——接口调用实现
pi = sm.precision_score(y_test, y_pred_test, average="macro")
pr = sm.recall_score(y_test, y_pred_test, average="macro")
print(pi, pr)
3) 混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。每一行 (数量之和)表示一个真实类别的样本,每一列(数量之和)表示一个预测类别的样本。
以下是一个预测结果准确的混淆矩阵
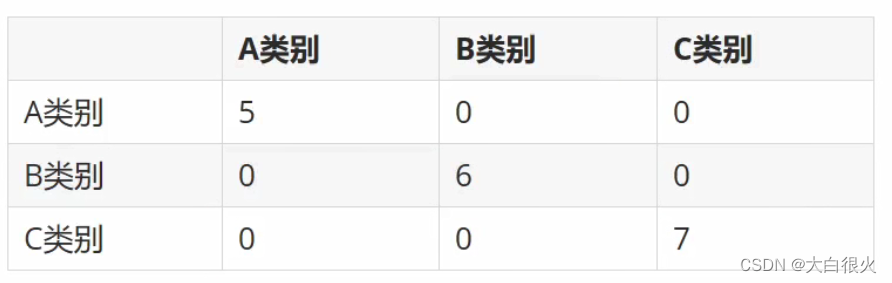
上述表格表示的含义为: A类别实际有5个样本,B类别实际有6个样本,C类别实际有7个样本;预测结果中,预测结果为A类别的为5个,预测结果为B类别的为6个,预测结果为C类别的为7个。
在混淆矩阵中
查准率=主对角线上的值/当前所在列的和
查全率=主对角线上的值/当前行的和
# 混淆矩阵接口
cm = sm.confusion_matrix(y_test, y_pred_test)
print(cm)
import matplotlib.pyplot as plt
import numpy as np
import sklearn.datasets as sd
import sklearn.metrics as sm
import sklearn.model_selection as sms
import sklearn.linear_model as sl
data = sd.load_iris()
x = data.data
y = data.target
x_train, x_test, y_train, y_test = sms.train_test_split(x, y, test_size=0.1, random_state=7)
model_sl = sl.LogisticRegression(solver='liblinear')
model_sl.fit(x_train, y_train)
y_pred_train = model_sl.predict(x_train)
y_pred_test = model_sl.predict(x_test)
# 使用准确率(精度accuracy)计算
accuracy = sm.accuracy_score(y_test, y_pred_test)
print(accuracy)
print("真实:", y_test)
print("预测:", y_pred_test)
mask_0 = y_test == 0
mask_1 = y_test == 1
mask_2 = y_test == 2
# 查准率——基础代码实现
p0 = (y_test[mask_0] == y_pred_test[mask_0]).sum()/y_pred_test[y_pred_test == 0].size
p1 = (y_test[mask_1] == y_pred_test[mask_1]).sum()/y_pred_test[y_pred_test == 1].size
p2 = (y_test[mask_2] == y_pred_test[mask_2]).sum()/y_pred_test[y_pred_test == 2].size
print(p0, p1, p2)
# 查全率——基础代码实现
r0 = (y_test[mask_0] == y_pred_test[mask_0]).sum()/y_test[mask_0].size
r1 = (y_test[mask_1] == y_pred_test[mask_1]).sum()/y_test[mask_1].size
r2 = (y_test[mask_2] == y_pred_test[mask_2]).sum()/y_test[mask_2].size
print(r0, r1, r2)
# 查准率,查全率——接口调用实现
pi = sm.precision_score(y_test, y_pred_test, average="macro")
pr = sm.recall_score(y_test, y_pred_test, average="macro")
print(pi, pr)
# 混淆矩阵接口
cm = sm.confusion_matrix(y_test, y_pred_test)
print(cm)
4)分类报告
report = sm.classification_report(y_test, y_pred_test)
import matplotlib.pyplot as plt
import numpy as np
import sklearn.datasets as sd
import sklearn.metrics as sm
import sklearn.model_selection as sms
import sklearn.linear_model as sl
data = sd.load_iris()
x = data.data
y = data.target
x_train, x_test, y_train, y_test = sms.train_test_split(x, y, test_size=0.1, random_state=7)
model_sl = sl.LogisticRegression(solver='liblinear')
model_sl.fit(x_train, y_train)
y_pred_train = model_sl.predict(x_train)
y_pred_test = model_sl.predict(x_test)
# 使用准确率(精度accuracy)计算
accuracy = sm.accuracy_score(y_test, y_pred_test)
print(accuracy)
print("真实:", y_test)
print("预测:", y_pred_test)
mask_0 = y_test == 0
mask_1 = y_test == 1
mask_2 = y_test == 2
# 查准率——基础代码实现
p0 = (y_test[mask_0] == y_pred_test[mask_0]).sum()/y_pred_test[y_pred_test == 0].size
p1 = (y_test[mask_1] == y_pred_test[mask_1]).sum()/y_pred_test[y_pred_test == 1].size
p2 = (y_test[mask_2] == y_pred_test[mask_2]).sum()/y_pred_test[y_pred_test == 2].size
print(p0, p1, p2)
# 查全率——基础代码实现
r0 = (y_test[mask_0] == y_pred_test[mask_0]).sum()/y_test[mask_0].size
r1 = (y_test[mask_1] == y_pred_test[mask_1]).sum()/y_test[mask_1].size
r2 = (y_test[mask_2] == y_pred_test[mask_2]).sum()/y_test[mask_2].size
print(r0, r1, r2)
# 查准率,查全率——接口调用实现
pi = sm.precision_score(y_test, y_pred_test, average="macro")
pr = sm.recall_score(y_test, y_pred_test, average="macro")
print(pi, pr)
# 混淆矩阵接口
cm = sm.confusion_matrix(y_test, y_pred_test)
print(cm)
# 分类报告
report = sm.classification_report(y_test, y_pred_test)
print(report)
D:\Software\Ananonda\python.exe D:/Project/PythonProject/AI_Test/sigmod.py
0.7333333333333333
真实: [2 1 0 1 2 0 1 1 0 1 1 1 0 2 0]
预测: [2 2 0 2 2 0 1 1 0 1 2 2 0 2 0]
1.0 1.0 0.42857142857142855
1.0 0.42857142857142855 1.0
0.8095238095238094 0.8095238095238096
[[5 0 0]
[0 3 4]
[0 0 3]]
precision recall f1-score support
0 1.00 1.00 1.00 5
1 1.00 0.43 0.60 7
2 0.43 1.00 0.60 3
accuracy 0.73 15
macro avg 0.81 0.81 0.73 15
weighted avg 0.89 0.73 0.73 15
Process finished with exit code 0
5) 测试集和训练集
划分测试集和训练集时,比例一般是1:9, 2:8,3:7,比例要均衡,所以
train_test_split(x, y, test_size=0.3)要加上类别均衡划分参数stratify=y。
import matplotlib.pyplot as plt
import numpy as np
import sklearn.datasets as sd
import sklearn.metrics as sm
import sklearn.model_selection as sms
import sklearn.linear_model as sl
data = sd.load_iris()
x = data.data
y = data.target
x_train, x_test, y_train, y_test = sms.train_test_split(x, y, test_size=0.1, random_state=7, stratify=y)
model_sl = sl.LogisticRegression(solver='liblinear')
model_sl.fit(x_train, y_train)
y_pred_train = model_sl.predict(x_train)
y_pred_test = model_sl.predict(x_test)
# 使用准确率(精度accuracy)计算
accuracy = sm.accuracy_score(y_test, y_pred_test)
print(accuracy)
print("真实:", y_test)
print("预测:", y_pred_test)
mask_0 = y_test == 0
mask_1 = y_test == 1
mask_2 = y_test == 2
# 查准率——基础代码实现
p0 = (y_test[mask_0] == y_pred_test[mask_0]).sum()/y_pred_test[y_pred_test == 0].size
p1 = (y_test[mask_1] == y_pred_test[mask_1]).sum()/y_pred_test[y_pred_test == 1].size
p2 = (y_test[mask_2] == y_pred_test[mask_2]).sum()/y_pred_test[y_pred_test == 2].size
print(p0, p1, p2)
# 查全率——基础代码实现
r0 = (y_test[mask_0] == y_pred_test[mask_0]).sum()/y_test[mask_0].size
r1 = (y_test[mask_1] == y_pred_test[mask_1]).sum()/y_test[mask_1].size
r2 = (y_test[mask_2] == y_pred_test[mask_2]).sum()/y_test[mask_2].size
print(r0, r1, r2)
# 查准率,查全率——接口调用实现
pi = sm.precision_score(y_test, y_pred_test, average="macro")
pr = sm.recall_score(y_test, y_pred_test, average="macro")
print(pi, pr)
# 混淆矩阵接口
cm = sm.confusion_matrix(y_test, y_pred_test)
print(cm)
# 分类报告
report = sm.classification_report(y_test, y_pred_test)
print(report)
D:\Software\Ananonda\python.exe D:/Project/PythonProject/AI_Test/sigmod.py
1.0
真实: [2 0 0 1 0 2 2 2 1 1 2 1 1 0 0]
预测: [2 0 0 1 0 2 2 2 1 1 2 1 1 0 0]
1.0 1.0 1.0
1.0 1.0 1.0
1.0 1.0
[[5 0 0]
[0 5 0]
[0 0 5]]
precision recall f1-score support
0 1.00 1.00 1.00 5
1 1.00 1.00 1.00 5
2 1.00 1.00 1.00 5
accuracy 1.00 15
macro avg 1.00 1.00 1.00 15
weighted avg 1.00 1.00 1.00 15
Process finished with exit code 0
6) 交叉验证法
(1)什么是交叉验证法
在样本数量较少的情况下,如果将样本划分为训练集、测试集,可能导致单个集合样本数量更少,可以采取交又验证法来训练和测试模型.
交叉验证法”(cross validation)先将数据集D划分为k个大小相同(或相似)的互不相交的子集,每个子集称为一个"折叠”(fold),每次训练,轮流使用其中的一个作为测试集、其它作为训练集.这样,就相当于获得了k组训练集、测试集,最终的预测结果为k个测试结果的平均值。
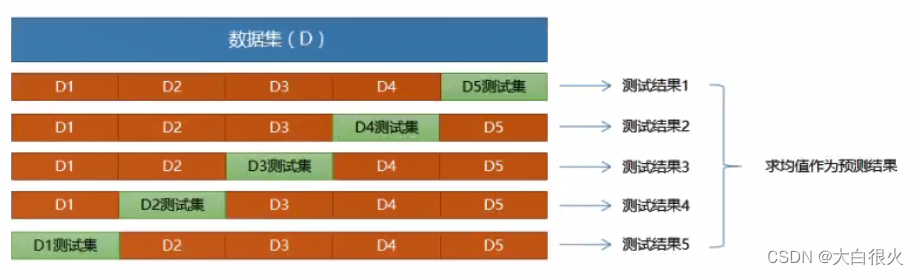

(2)交叉验证的实现
在模型确定之后,训练之前加入
import matplotlib.pyplot as plt
import numpy as np
import sklearn.datasets as sd
import sklearn.metrics as sm
import sklearn.model_selection as sms
import sklearn.linear_model as sl
data = sd.load_iris()
x = data.data
y = data.target
x_train, x_test, y_train, y_test = sms.train_test_split(x, y, test_size=0.1, random_state=7, stratify=y)
model_sl = sl.LogisticRegression(solver='liblinear')
scores = sms.cross_val_score(model_sl, x, y, scoring='f1_weighted', cv=5).mean()
print("score: ", scores)
score: 0.959522933505973
2 模型优化
1) 验证曲线
验证曲线是指根据不同的评估系数,来评估模型的优劣.例如,构建随机森林,树的数量不同,模型预测准确度有何不同?以下是一个验证曲线的示例:

2)学习曲线
学习曲线是用来评估不同大小的训练集下模型的优劣程度,如果预测结果随着训练集样本的增加而变化不大,那么增加样本数量不会对模型产生明显优化作用.以下是一个学习曲线的示例:
3)样本类别均衡
- 上采样(将类别数据少的数据 再收集一点)
- 下采样(将某类别多的比类别少的数据删除)
4) 相关实现
import pandas as pd
import numpy as np
import sklearn.preprocessing as sp
import sklearn.ensemble as se
import sklearn.model_selection as sms
import sklearn.metrics as sm
import matplotlib.pyplot as plt
# 1.读取数据
data = pd.read_csv('car.txt', header=None)
# 2.特征工程
encoders = []
data_encoded = pd.DataFrame()
for i in data:
encoder_label = sp.LabelEncoder()
res = encoder_label.fit_transform(data[i])
encoders.append(encoder_label)
data_encoded[i] = res
# 3.整理输入集和输出集
x = data_encoded.iloc[:, :-1].values
y = data_encoded.iloc[:, -1].values
train_x, test_x, train_y, test_y = sms.train_test_split(x, y, test_size=0.2, random_state=11, stratify=y)
# 4.构建模型
model_rf = se.RandomForestClassifier(n_estimators=550, max_depth=15, random_state=11, min_samples_split=3, class_weight='balanced')
model_rf.fit(train_x, train_y)
y_pred_train = model_rf.predict(train_x)
y_pred_test = model_rf.predict(test_x)
# 5.模型评估
report = sm.classification_report(train_y, y_pred_train)
print(report)
# 6.模型优化
# 6.1 验证曲线——验证模型的超参数是否合适
# params = np.arange(5, 15)
# train_scores1, test_scores1 = sms.validation_curve(model_rf, x, y, 'max_depth', params, cv=5)
# print(train_scores1.mean(axis=1))
# print(test_scores1.mean(axis=1))
# 6.2 学习曲线——评估不同大小的训练集下模型的优劣
train_size, train_scores, test_scores = sms.learning_curve(model_rf, x, y, train_sizes=[i/10 for i in range(2, 10)], cv=5)
train_score = train_scores.mean(axis=1)
test_score = test_scores.mean(axis=1)
plt.plot([i/10 for i in range(2, 10)], train_score, 'o-')
plt.show()
print(y_pred_test)
print(model_rf.predict_proba(test_x)) # 置信概率
4.4 支持向量机
1)支持向量机
支持向量机 (Support Vector Machines) 是一种二分类模型,在机器学习、计算机视觉、数据挖掘中广泛应用,主要用于解决数据分类问题,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化 (即数据集的边缘点到分界线的距离d最大,如下图),最终转化为一个凸二次规划问题来求解。通常SVM用于二元分类问题,对于多元分类可将其分解为多个二元分类问题,再进行分类。所谓“支持向量”,就是下图中虚线穿过的边缘点。支持向量机就对应着能将数据正确划分并且间隔最大的直线 (下图中红色直线):
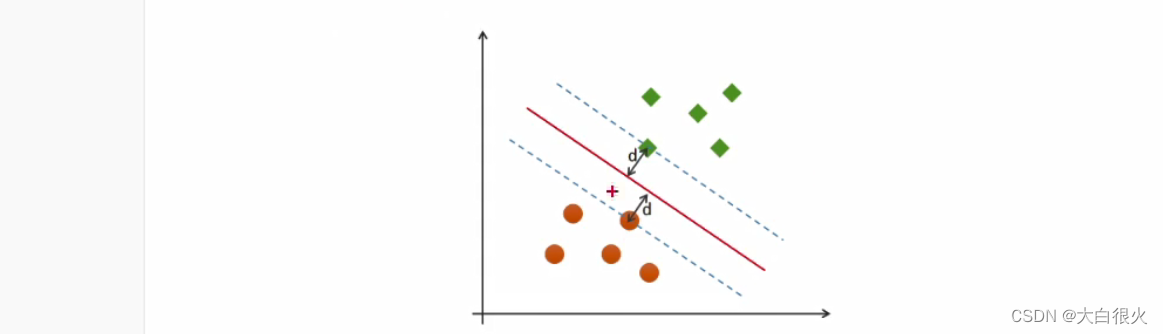
如图中的A,B两个样本点,B点被预测为正类的确信度要大于A点所以SVM的目标是寻找一个超平面,使得离超平面较近的异类点之间能有更大的间隔,即不必考虑所有样本点,只需让求得的超平面使得离它近的点间隔最大。超平面可以用如下线性方程来描述:
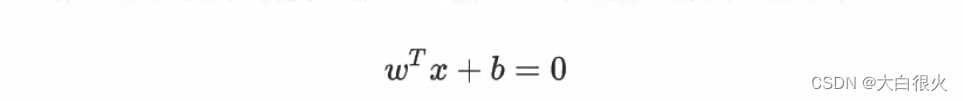
其中,
x
=
(
x
1
;
x
2
;
.
.
.
;
x
n
)
x=(x_1;x_2;...;x_n)
x=(x1;x2;...;xn),
w
=
(
w
1
;
w
2
;
.
.
.
;
w
n
)
w =(w_1;w_2;...;w_n)
w=(w1;w2;...;wn),
b
b
b为偏置项.可以从数学上证明,支持向量到超平面距离为:
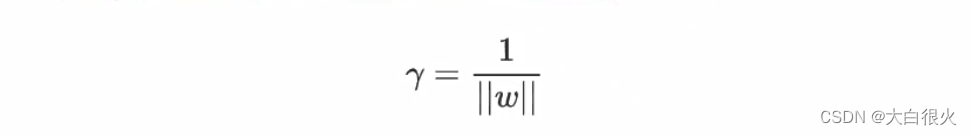
为了使距离最大,只需最小化
∣
∣
w
∣
∣
||w||
∣∣w∣∣即可。
2)SVM最优边界要求
SVM寻找最优边界时,需满足以下几个要求:
(1)正确性:对大部分样本都可以正确划分类别;
(2)安全性:支持向量,即离分类边界最近的样本之间的距离最远;
(3)公平性:支持向量与分类边界的距离相等;
(4) 简单性: 采用线性方程 (直线、平面)表示分类边界,也称分割超平面。如果在原始维度中无法做线性划分,那么就通过升维变换,在更高维度空间寻求线性分割超平面.从低纬度空间到高纬度空间的变换通过核函数进行。














 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









