







 文章探讨了如何利用TF-IDF技术改进基于用户打标签次数和物品打标签次数的推荐算法,以减少热门物品推荐,增强个性化。通过引入TF-IDF,可以更准确地衡量标签的重要性,从而提供更精准的推荐。
文章探讨了如何利用TF-IDF技术改进基于用户打标签次数和物品打标签次数的推荐算法,以减少热门物品推荐,增强个性化。通过引入TF-IDF,可以更准确地衡量标签的重要性,从而提供更精准的推荐。
使用用户打标签次数*物品打标签次数做乘积的算法虽然简单,但是会造成热门物品推荐的情况。物品标签的权重是物品打过该标签的次数,用户标签的权重是用户使用过该标签的次数,从而导致个性化的推荐降低,而造成热门推荐。
运用TF-IDF的思想可以对算法进行改进。TF-IDF(term frequemcy-inverse documnet frequency)是一种用于资讯检索和文本挖掘的加权技术。用来评估一个词的重要程度。其主要思想是如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。IDF是逆向文件频率,即包含某个term的文件越少,则IDF越大。
IDF可以由总文件数目除以包含该词语的文件的数目,然后取对数得到:
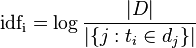
其中D代表文件的总数,分母代表包含该词语的文件的数目,为避免分母为0,通常用1+分母作为当前的分母。这样,当包含该词语的文件在总文件数量中所占比重很小时,能够得到较大的TDF,从而能够得到较大的比重,有利于实现个性化的推荐。(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









