







LeNet
开山之作!
一共七层。2层卷积、2层池化、3层全连接
class Lenet(nn.Module):
def __init__(self):
super(Lenet, self).__init__()
layer1 = nn.Sequential()
layer1.add_module('conv1', nn.Conv2d(1, 6, 3, padding=1))
layer1.add_module('pool1', nn.MaxPool2d(2, 2))
self.layer1 = layer1
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(6, 16, 5))
layer2.add_module('pool2', nn.MaxPool2d(2, 2))
self.layer2 = layer2
layer3 = nn.Sequential()
layer3.add_module('fc1', nn.Linear(400, 120))
layer3.add_module('fc2', nn.Linear(120, 84))
layer3.add_module('fc3', nn.Linear(84, 10))
self.layer3 = layer3
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size(0), -1)
x = self.layer3(x)
return xAlexnet
2012年横空出世,是深度学习近几年大火的起点!
最原始版本的Alexnet是用两个GPU计算的,相对于LeNet,他增加了ReLU激活层和Dropout层
class AlexNet(nn.Module):
def __init__(self, num_classes):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), )
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes), )
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return xVGGNet
VGGNet总结起来就是使用了更小的滤波器,同时使用了更深的结构,Alexnet只有8层网络,而VGGNet有16——19层网络,它的滤波器是3*3卷积滤波器和2*2的大池化层。
层叠很多的小滤波器的视野和一个大的滤波器的感受野是相同的,还能减少参数,同时拥有更深的网络结构。
class VGG(nn.Module):
def __init__(self, num_classes):
super(VGG, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2), )
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes), )
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
其实VGG只是堆叠了较多的网络层,并没有进行太多的创新。
GoogLeNet
GoogLeNet是在2014年被提出的,现在进化到了v4版本。它采取了比VGGNet更深的网络结构,一共有22层,但是参数比AlexNet少了12倍,同时有很高的计算效率,因为他采用了一种Inception的模块,而且它没有全连接层。
Inception模块设计了一个局部的网络拓扑结构,然后将这些模块堆叠在一起形成一个抽象层网络结构。具体来说就是运用几个并行的滤波器对输入进行卷积和池化,这些滤波器有不同的感受野,最后将输出的结果按深度拼接在一起形成输出层。
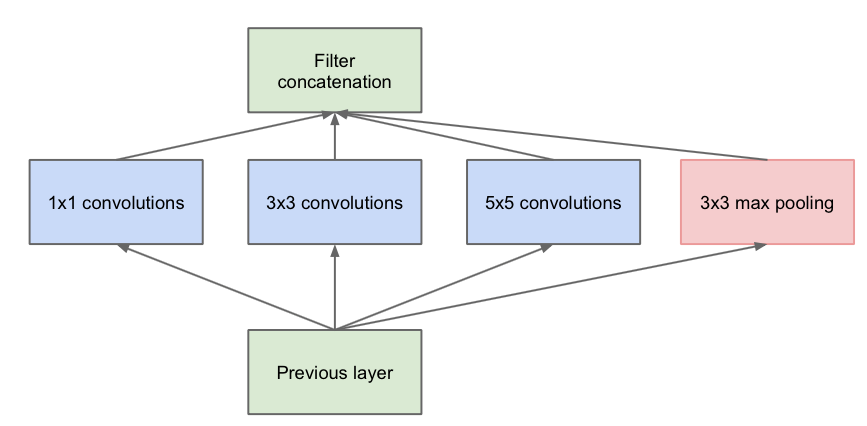
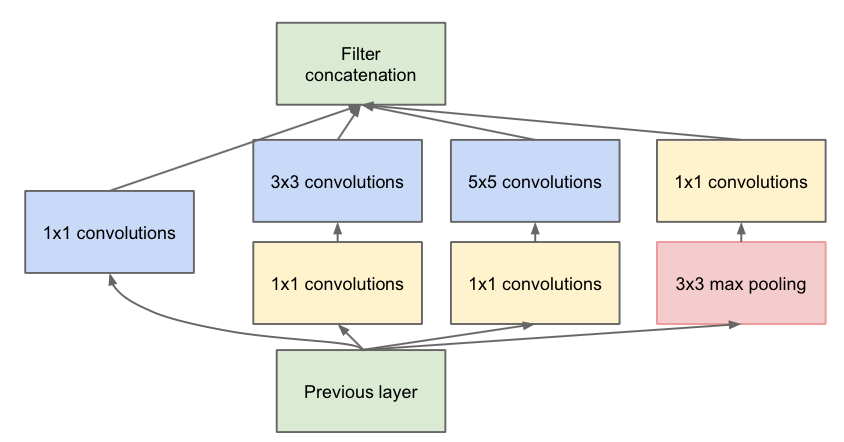
下边的模块是对上边的改进,增加了一些1*1的巻积层来降低输入层的纬度,是网络参数减少,从而减少了网络的复杂性。
下面是Inception模块,这个网络都是有这个模块组成的。
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class Inception(nn.Module):
def __init__(self, in_channels, pool_features):
super(Inception, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(
in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
首先定义一个最基础的卷积模块,然后根据这个模块定义了1*1,3*3,5*5的模块和一个池化层,最后使用torch.cat()将他们按深度拼接起来,得到输出的结果。
ResNet
ResNet于2015年被提出,通过残差模块能够成功的训练高达152层的神经网络。
它的设计灵感来源于:在加深神经网络的时候,会出现Degradation,就是说准确率会先上升然后饱和,然后下降。
这不是过拟合的问题,因为不仅在验证集上误差增加,训练集本身误差也会增加。假设一个比较浅的网络达到了饱和的准确率,那么在后面加上几个恒等映射层,误差也不会增加,也就是说更深的模型起码不会使得模型效果下降。
这里提到的恒等映射直接将前一层传到后边一层的思想就是ResNet的灵感。假设输入是x,期望输出是H(x),如果直接把输入x传到输出作为初始结果,那么此时需要学习的木匾就是F(x)=H(x)-x,也就是残差模块。
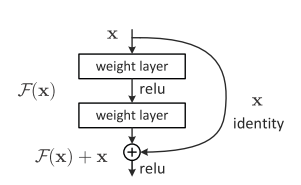
实现如下:
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(
in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=1,
bias=False)
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out















 2504
2504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









