







 本文介绍了一个Python实现的CSDN博客爬虫项目,该爬虫能够抓取指定用户的博客文章标题、类型、创建时间及阅读量等信息,并将这些数据保存至Excel文件中。文中详细展示了从需求分析、代码实现到最终结果的全过程。
本文介绍了一个Python实现的CSDN博客爬虫项目,该爬虫能够抓取指定用户的博客文章标题、类型、创建时间及阅读量等信息,并将这些数据保存至Excel文件中。文中详细展示了从需求分析、代码实现到最终结果的全过程。
需求
Python爬取某个账号CSDN博客所有文章的标题,类型,创建时间,阅读数量,并将结果保存至Excel。
分析
CSDN主页URL为:https://blog.csdn.net/seanyang_/article/list/1
根据url可以得到其他页数的链接在https://blog.csdn.net/seanyang_/article/list/页数
主页F12查看元素,可以看到每一个文章列表所在class为article-list
每一篇文章所在class为article-item-box,如图可以herf,文章标题,创建时间,文章阅读数

Requests获取内容
Requests发送请求,获取网页内容,这里注意需要加上请求头。
self.headers = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
"(KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"
}
response = requests.get(f'{self.url}/{page_num}', headers=self.headers)
response.encoding = response.apparent_encoding
response.raise_for_status()
content = response.contentBeautifulSoup解析内容
BeautifulSoup根据标签的属性和属性值获取到想要的内容。
soup = BeautifulSoup(content, 'html.parser')
article_table = soup.find('div', class_='article-list')#获取到文章列表
for article in article_table.find_all('div', class_='article-item-box'):#对于每一个文章
article_type = article.a.span.text #逐级查找标签,找到文章类型(感觉BS很灵活啊)
article_url = article.a["href"]
article_span = article.a.find_all('span')
for i in article_span:
i.clear()#清空span标签然后获取标题
article_name = article.a.get_text().strip() #获取文章名称
create_date = article.find('div', class_='info-box').find('span', class_='date').text.strip()#获取到date这里查找标签操作真厉害
read_num= article.find('div', class_='info-box').find('span', class_='read-num').text #查找到阅读量,实际页面无评论数量所以这里偷懒乐
comment_num=read_num
print(article_type, article_name, article_url, create_date, read_num, comment_num)#输出值原文:清风Python
源代码还涉及到保存结果至Excel,以及打包为exe文件,感兴趣可以自行研究。
针对页数的处理,这里定义了100页,当获取到的article_table为空时,则说明结束了。
if article_table is None:#如果文章列表为空,说明到最后了
self.show.config(text="数据获取结束.")
return结果
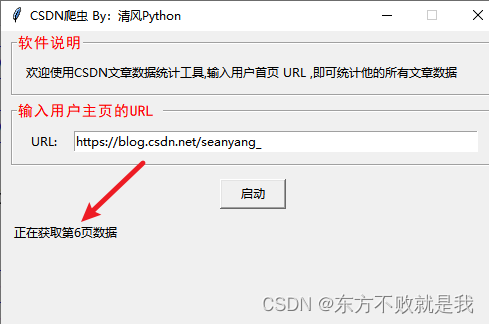
运行后再窗口输入URL:点击启动。东方不败就是我的博客_CSDN博客-测试工具,测试基础,python+java领域博主
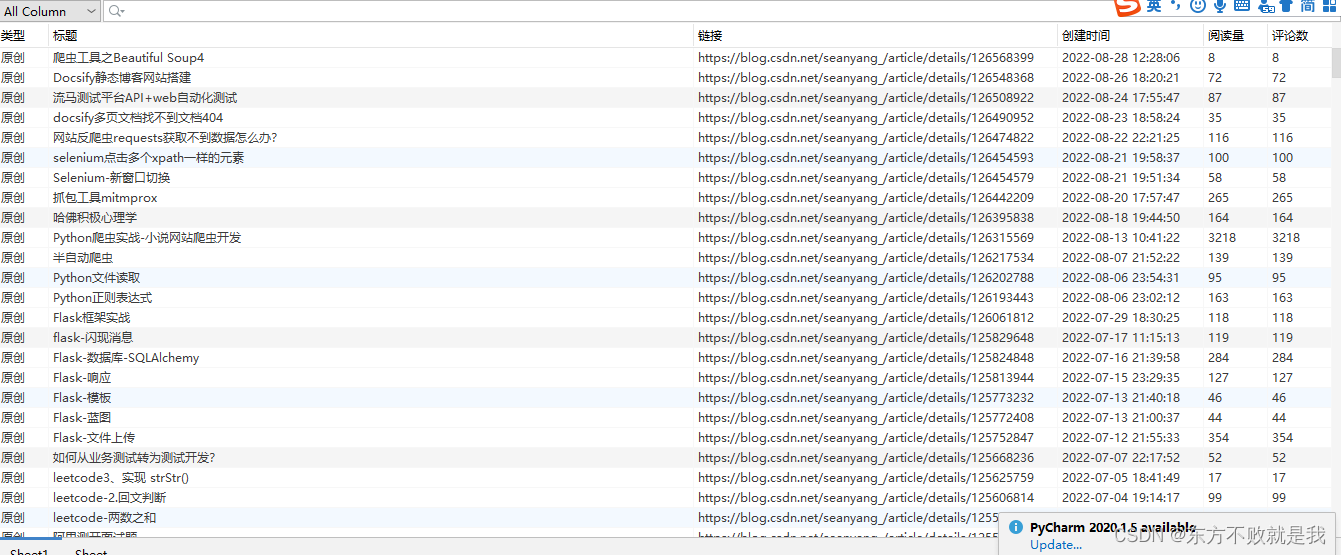
运行结束后,打开生成的EXCEL文档,可以看到结果。
完整代码
import tkinter as tk
import requests
import openpyxl
from bs4 import BeautifulSoup
class BlogCrawler:
def __init__(self, url, sheet_name, show):
self.sheet = sheet_name
self.show = show
self.headers = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36"
}
self.url = f"{url.rstrip('/')}/article/list"
self.url_parser()
def url_parser(self):#解析html并输出数据
for page_num in range(1, 100):
self.show.config(text="正在获取第%s页数据" % page_num)
root.update()
response = requests.get(f'{self.url}/{page_num}', headers=self.headers)
response.encoding = response.apparent_encoding
response.raise_for_status()
content = response.content
soup = BeautifulSoup(content, 'html.parser')
article_table = soup.find('div', class_='article-list')#获取到文章列表
if article_table is None:#如果文章列表为空,说明到最后了
self.show.config(text="数据获取结束.")
return
for article in article_table.find_all('div', class_='article-item-box'):#对于每一个文章
article_type = article.a.span.text #逐级查找标签,找到文章类型(感觉BS很灵活啊)
article_url = article.a["href"]
article_span = article.a.find_all('span')
for i in article_span:
i.clear()#???
article_name = article.a.get_text().strip() #获取文章名称
create_date = article.find('div', class_='info-box').find('span', class_='date').text.strip()#获取到date这里查找标签操作真厉害
read_num= article.find('div', class_='info-box').find('span', class_='read-num').text #查找到阅读量,实际页面无评论数量所以这里偷懒乐
comment_num=read_num
print(article_type, article_name, article_url, create_date, read_num, comment_num)#输出值
self.sheet.append(
[article_type, article_name, article_url, create_date, read_num, comment_num])#添加至excell
def start_crawler(url, show_info):#保存数据
wb = openpyxl.Workbook()
try:
st = wb.create_sheet(index=0)
st.append(["类型", "标题", "链接", "创建时间", "阅读量", "评论数"])
BlogCrawler(url, st, show_info)#传进url,sheetname和show
finally:
wb.save("清风Python数据爬虫.xlsx")
def center_window(master, width, height):
# tkinter GUI工具居中展示
screenwidth = master.winfo_screenwidth()
screenheight = master.winfo_screenheight()
size = '%dx%d+%d+%d' % (width, height, (screenwidth - width) / 2,
(screenheight - height) / 2)
master.geometry(size)
def user_input(root):#输入窗口
note = tk.LabelFrame(root, text="软件说明", padx=10, pady=10, fg="red", font=("黑体", '11'))
note.grid(padx=10, pady=3, sticky=tk.NSEW)
index = tk.Label(note, text='欢迎使用CSDN文章数据统计工具,输入用户首页 URL ,'
'即可统计他的所有文章数据').grid()
lb = tk.LabelFrame(root, text="输入用户主页的URL ", padx=10,
pady=10, fg="red", font=("黑体", '11'))
lb.grid(padx=10, pady=3, sticky=tk.NSEW)
unit = tk.Label(lb, text="URL: ")
unit.grid(row=1, column=0, padx=5)
url = tk.Entry(lb)
url.grid(row=1, column=1, columnspan=2, padx=5, ipadx=130, pady=2)
show_info = tk.Label(root, text='')
show_info.grid(row=3, column=0, padx=10, pady=2, sticky=tk.W)
submit = tk.Button(root, text="启动", width=8,
command=lambda: start_crawler(url.get(), show_info)#开始进行爬虫。
)
print(show_info)
submit.grid(row=2, column=0, pady=10)
if __name__ == '__main__':
root = tk.Tk()
center_window(root, 500, 300)
root.resizable(width=False, height=False)
root.title('CSDN爬虫 By:清风Python')
user_input(root)
root.mainloop()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









