






[阅读心得] 半监督学习论文阅读笔记——Curriculum Labeling
写在前面
半监督学习的目标是在有标注数据的基础上,利用无标签数据增强算法模型的性能表现。其主要有两种方案:基于伪标签训练的方法和基于一致性训练的方法。本文是一种基于伪标签训练的方法,主要是使用了一种更精细的伪标签筛选方案,读这篇希望逐步了解半监督学习的基本原理和研究方式。
1. Abstract
本工作使用伪标签训练的方式进行半监督学习,通过精细的伪标签筛选和投入策略使其效果达到了超过一致性训练的半监督学习的方法,并且在域变化的情况下更具有鲁棒性。本工作主要有两个改进点:
1)使用了课程标签(Curriculum Labeling, CL)的方法利用伪标签;
2)每轮训练重新初始化参数(restarting)而不是微调(funtuning),避免训练过程语义偏移;
2. Introduction
无监督学习的主要有两个方式:基于伪标签训练的方法和基于一致性训练的方法;
针对伪标签训练的方法,主要是通过“熵正则化”的方式,明确模型的决策边界,从而提高模型的感知能力。基于伪标签的方法主要有两个问题:
1)手工设计阈值差:不论是单步训练中伪标签-标签的平衡、还是多步训练中每次伪标签的投入快慢程度的权衡,大多依赖于人工设定的固定阈值,这对于由易到难训练伪标签的方式来说过于死板,不利于训练;
2)概念偏移(concept drift):投入伪标签进行训练的早期阶段,由于模型本身的表现性能较差,所以可能导致很多错误识别的样本,这些样本被投入网络中迭代训练,将会强化这一错误的“概念偏移”,导致错误不断累积;
3)应用域存在差异性:目前的半监督方案大多是将数据集直接划分为“labeled”和"unlabeled",这导致伪标签域和标签域是完全一致的,而在实际应用的过程中并非如此。大多半监督的方法对于实际应用过程中的域变化不具备鲁棒性;
其整体流程如下,本文主要的工作在于(3)步骤中每轮投入训练的伪标签的筛选策略,和(4)步骤中训练的初始化参数设计上。
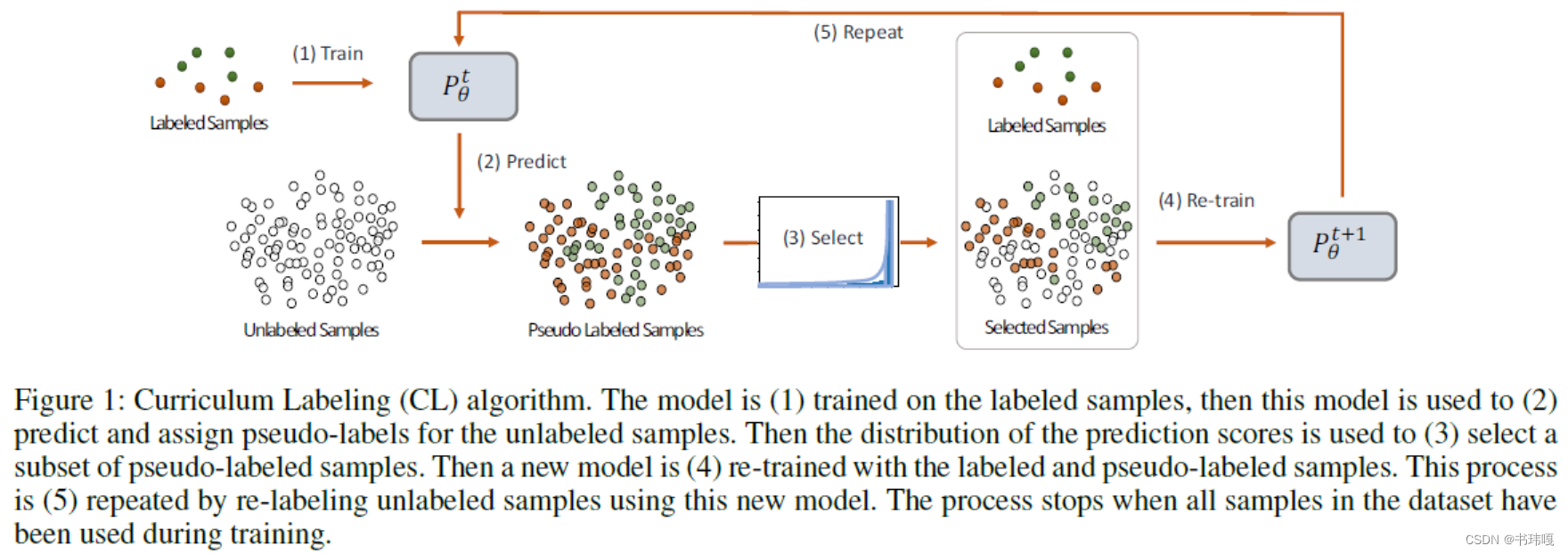
3. Method
3.1 Select
本工作的整体伪标签利用策略如下图:

相比于按照固定的置信度阈值进行筛选,本工作假设模型预测的伪标签的置信度遵循帕累托分布。在每个迭代轮次将全部标签按置信度排列后,按百分比
T
r
T_r
Tr进行选取,
P
e
r
c
e
n
t
i
l
e
Percentile
Percentile随着轮次迭代而逐渐增大,从20%–>100%,到全部伪标签投入训练后即停止训练。
这样做相比于固定阈值筛选具有一定的合理性:在模型迭代训练之初,模型的表现能力较差,比较容易出现错误样本,因此在训练之初选取较少的样本有利于避免错误标签误导训练,导致概念偏移(concept drift)。后面retrain的设计也是为了避免这一问题。
3.2 Re-train
相比于每个训练迭代轮次微调模型(funtuning),本工作直接在每轮迭代轮次中初始化参数(re-start),这样也有助于避免早期训练的过程中,错误标签累计误导训练,导致概念偏移(concept drift)。
4. Experiment
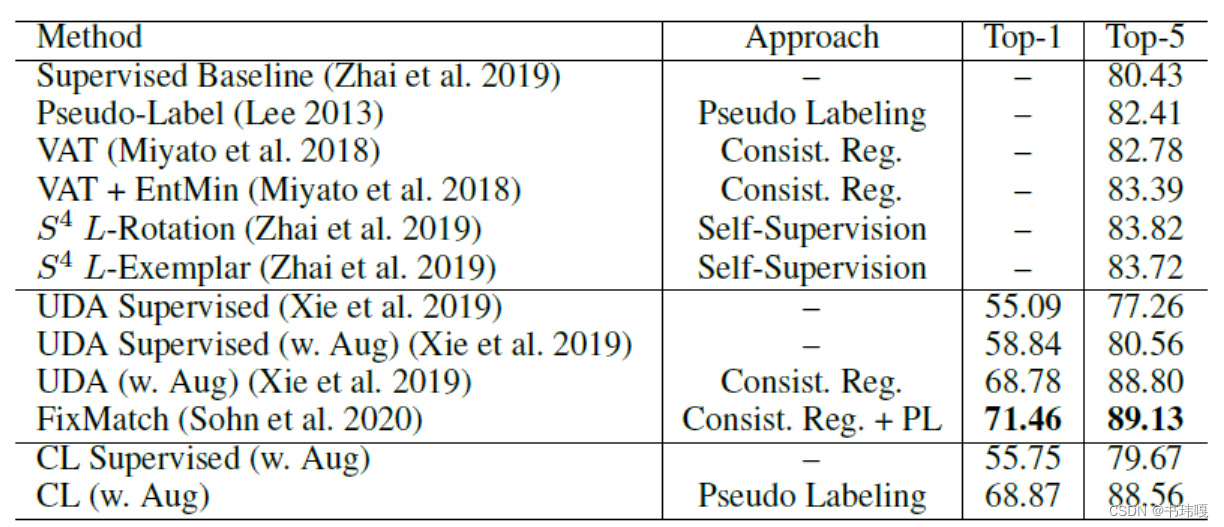
4.1 Compare With SOTA
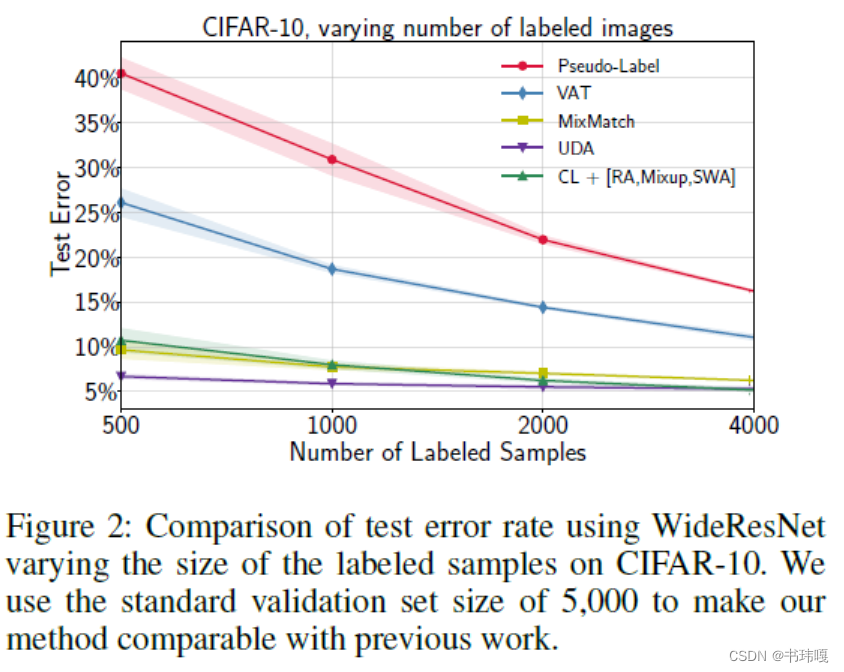
提出的CL方法优于先前的基于伪标签训练的SSL方法,同时相比于基于一致性训练的SSL方法(UDA)也很有竞争力。另外通过将有标注数据的样本数量衰减后,CL仍能保证较强的性能。
4.2 Realistic Eval with Out-of-Distribution Unlabeled Samples
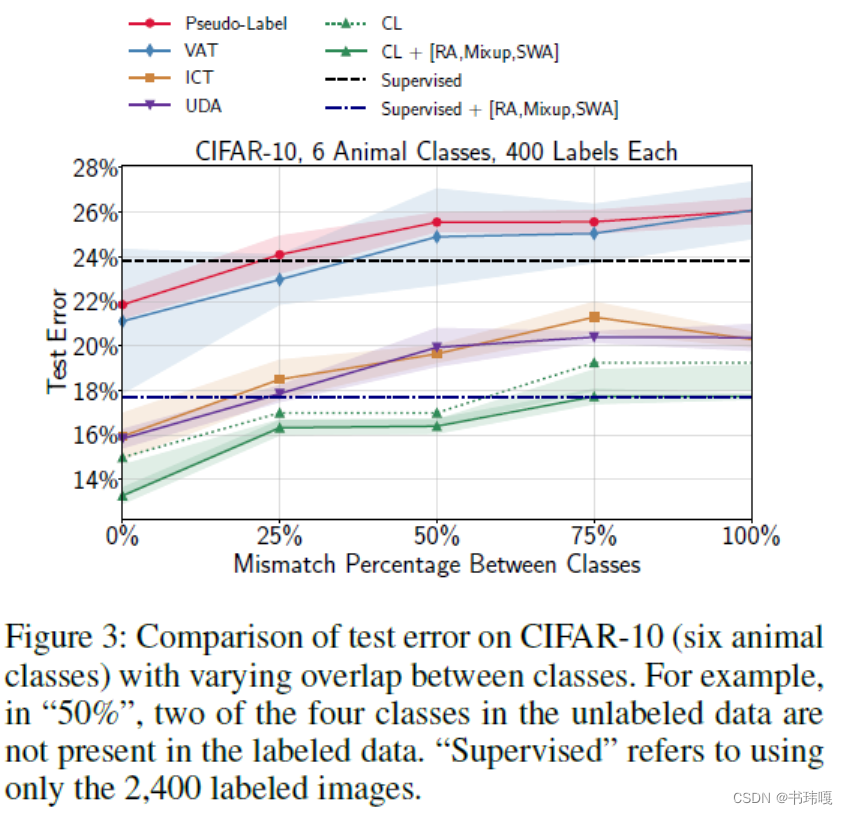
这里想测试一下提出的方法在域迁移的情况下的鲁棒性,但是测试的场景并不是完全的域迁移。而是限制有标签数据仅包含6类动物,而无标签数据包含4个类别,其中4个类别不完全能够对应有标签数据中的6个类别。虽然图像整体的特征域对于Labeled和Unlabelled是完全相同的,但是细化的类别的特征域上二者一定是不同的。
通过下图结果可以发现,在域迁移逐渐加重的条件下,CL性能更加稳定,作者将这种鲁棒性归功于CL的每轮迭代自适应选取阈值能过滤掉很多噪声样本。另外值得注意的是,MisMatch程度达到50%之后,很多SSL方法的误差甚至会超过只使用有标注样本的训练,这也侧面说明了:如果域的差别过大,可能考虑SSL方法会起反效果
4.3 Effectiveness of Curriculum Labeling
表5证明了相比于通过固定阈值筛选的单步训练利用伪标签,CL的方法效果更好;
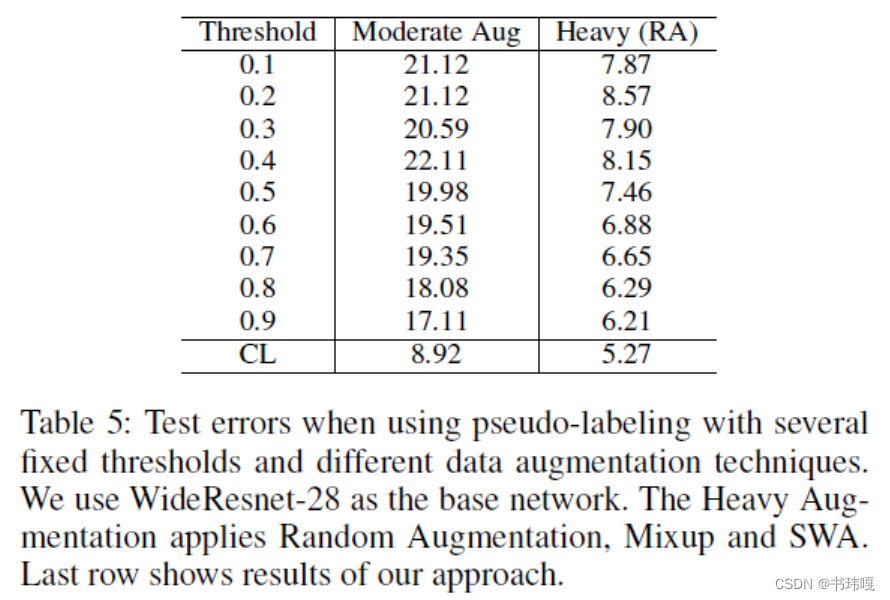
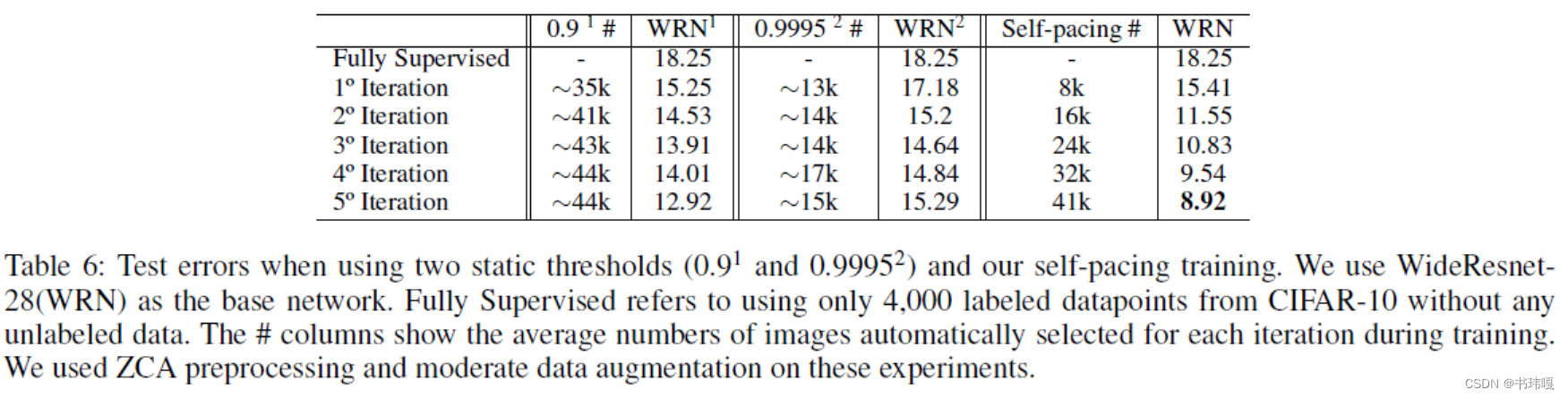
表6证明了相比于基于固定阈值筛选的多步迭代训练,CL的方法效果更好;
4.4 Effectiveness of Reinitializing v.s. Funtuning
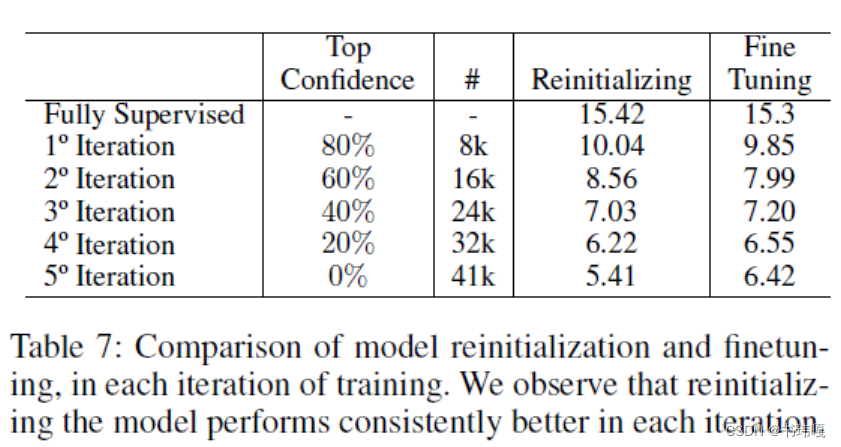
表7说明了Reinitializing在每轮的迭代中至少会带来1%的涨点收益,作者认为这一操作带来的收益是由于其缓解了早期训练模型得到的结果质量不高,很多高置信度伪标签可能会误导模型,导致训练误差的累计。
5. Conclusion
通过基于伪标签的半监督学习方法,超过了基于一致性训练的无标注数据训练方法。
6. Analysis
本文通过更精细的伪标签筛选规则设计,使基于伪标签训练的SSL方法上限进一步提高,达到能媲美基于一致性训练的SSL方法的水平。但是现在看来这个标签筛选规则也并非十分合理和细致,本质上样本选取百分位 T r T_r Tr的设计还是一个阈值,只不过更"soft"一写,还是比较僵硬的,将标签预测结果服从“帕累托分布”缺乏实验验证。另外每次训练都重新初始化参数Reinitializing,训练成本较高,同时相比于Funtuninig更容易发生欠拟合问题,毕竟相当于每个模型都只训练了1个iteration。但是看一看这些消融实验,能够初步对伪标签的作用和效果有一定的认识,入门SSL比较好。















 1440
1440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









