







 本文详细探讨了Pytorch中自动求导函数`backward()`的参数含义,通过实例展示了标量、向量和矩阵自动求导的情况,并解析了参数如何影响梯度计算。最后总结了`backward()`参数的意义,即作为输出对输入求导的权重。
本文详细探讨了Pytorch中自动求导函数`backward()`的参数含义,通过实例展示了标量、向量和矩阵自动求导的情况,并解析了参数如何影响梯度计算。最后总结了`backward()`参数的意义,即作为输出对输入求导的权重。
正常来说backward( )函数是要传入参数的,一直没弄明白backward需要传入的参数具体含义,但是没关系,生命在与折腾,咱们来折腾一下,嘿嘿。
对标量自动求导
首先,如果out.backward()中的out是一个标量的话(相当于一个神经网络有一个样本,这个样本有两个属性,神经网络有一个输出)那么此时我的backward函数是不需要输入任何参数的。
import torch
from torch.autograd import Variable
a = Variable(torch.Tensor([2,3]),requires_grad=True)
b = a + 3
c = b * 3
out = c.mean()
out.backward()
print('input:')
print(a.data)
print('output:')
print(out.data.item())
print('input gradients are:')
print(a.grad)
运行结果:
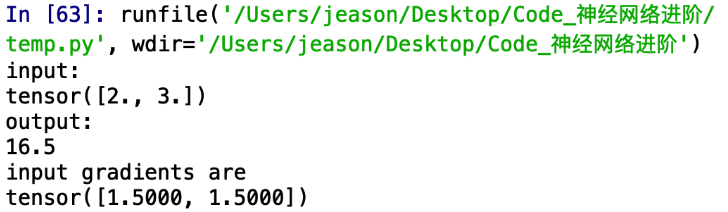
不难看出,我们构建了这样的一个函数:
o u t = 3 [ ( a 1 + 3 ) + ( a 2 + 3 ) ] 2 out={3[(a_1+3)+(a_2+3)]\over2} out=23[(a1+3)+(a2+3)]
所以其求导也很容易看出:
∂ o u t ∂ a 1 = ∂ o u t ∂ a 2 = 3 2 {\partial out \over \partial a_1}={\partial out \over \partial a_2 }={3\over2} ∂a1∂out=∂a2∂out=23
这是对其进行标量自动求导的结果.
对向量自动求导
如果out.backward()中的out是一个向量(或者理解成1xN的矩阵)的话,我们对向量进行自动求导,看看会发生什么?
先构建这样的一个模型(相当于一个神经网络有一个样本,这个样本有两个属性,神经网络有两个输出):
import torch
from torch.autograd import Variable
a = Variable(torch.Tensor([[2.,4.]]),requires_grad=True)
b = torch.zeros(1,2)
b[0,0] = a[0,0] ** 2
b[0,1] = a[0,1] ** 3
out = 2 * b
#其参数要传入和out维度一样的矩阵
out.backward(torch.FloatTensor([[1.,1.]]))
print('input:')
print(a.data)
print('output:')
print(out.data)
print('input gradients are:')
print(a.grad)
模型也很简单,不难看出out求导出来的雅克比应该是:
( ∂ o u t 1 ∂ a 1 = 4 a 1 ∂ o u t 1 ∂ a 2 = 0 ∂ o u t 2 ∂ a 1 = 0 ∂ o u t 2 ∂ a 2 = 6 a 2 2 ) \begin{pmatrix} {\partial out_1 \over \partial a_1}=4a_1&{\partial out_1 \over \partial a_2}=0\\\\ {\partial out_2 \over \partial a_1}=0&{\partial out_2 \over \partial a_2}=6a_2^2\\\\ \end{pmatrix} ⎝⎜⎜⎛∂a1∂out1=4a1∂a1∂out2=0∂a2∂out1=0∂a2∂out2=6a22⎠⎟⎟⎞
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









