







 中国石油借助数字孪生技术,旨在构建具备“全方位感知、综合性预判、一体化管控、自适应优化”能力的智慧管网。通过3DGIS+视频融合+时空位置智能技术,实现设计施工、油气调运、线路管理、设备诊断和事故应急的智能化管理。标准化数据与统一化模型以及模型融合技术为核心,推动信息化与工业化的深度融合,助力管道全业务链的高效协同。
中国石油借助数字孪生技术,旨在构建具备“全方位感知、综合性预判、一体化管控、自适应优化”能力的智慧管网。通过3DGIS+视频融合+时空位置智能技术,实现设计施工、油气调运、线路管理、设备诊断和事故应急的智能化管理。标准化数据与统一化模型以及模型融合技术为核心,推动信息化与工业化的深度融合,助力管道全业务链的高效协同。
随着中国数字化转型浪潮不断加深,长输油气管道传统业态模式同样面临着数字化转型升级的机遇期。北京智汇云舟科技有限公司研发经过6年以上的积累,取得了坚实的技术和产品,拥有'3DGIS+视频融合+时空位置智能(LI)技术首创“实景数字孪生”',自主研发了实景孪生①解决方案、②Paas平台、③实景孪生虚实融合一体机等产品。

(一)案例背景
以数字孪生天然气管道工程建设为标志,中国石油提出建设具备“全方位感知、综合性预判、一体化管控、自适应优化”能力的智慧管网并开题立项,力求实现管道运行管理由精细化模式进一步朝智能化、精准化方向升级。其中,数字孪生无论从技术理念、技术内涵还是预期目标都与智慧管网建设理念高度契合,因此以管道数字孪生构建应用作为实现智慧管网建设运行的重要着力点,也同时成为管道各建设运行企业关注焦点。
(二)系统框架
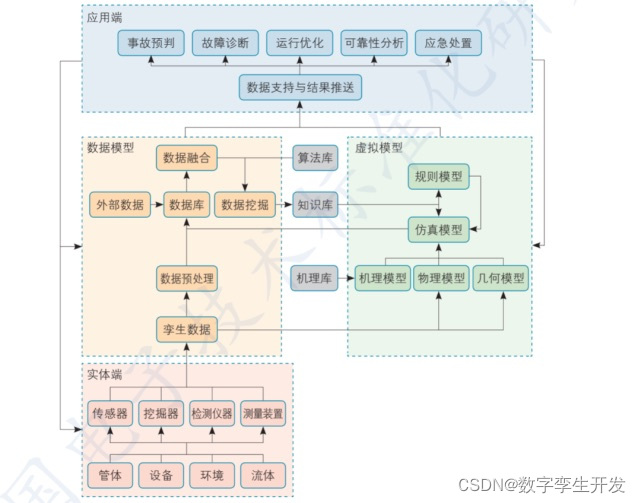
(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









