







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
描述起来,用struct结构体
组织起来,用链表或其他高效的数据结构
系统调用和库函数概念
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分 由操作系统提供的接口,叫做系统调用。 系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
进程
上面就说过进程其实就是一个可执行程序的实例,那么程序的本质就是文件,放在磁盘上的
通过冯诺依曼结构体系,我们也大概明白了,可执行程序放在磁盘中,因为磁盘访问太慢,CPU进行数据计算的时候,操作系统会将文件放入内存中,CPU再进行处理。
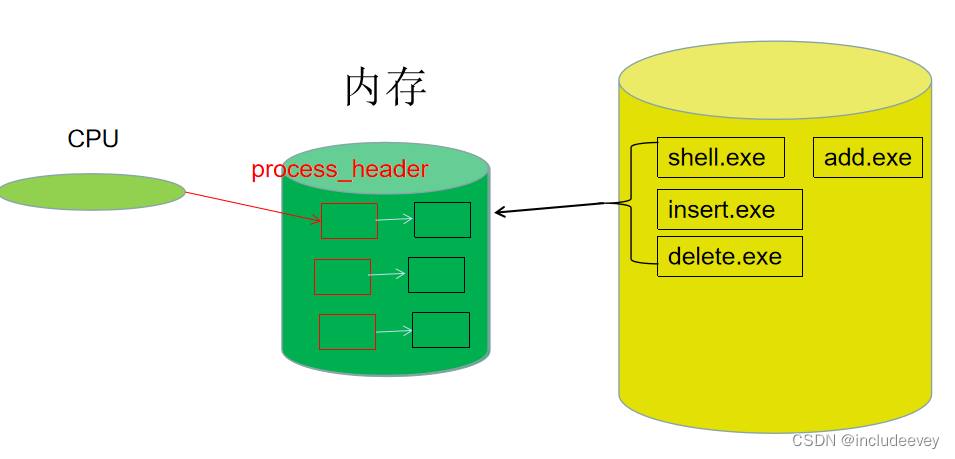
操作系统对进程的管理
在内存中加载的程序很多,如果不管理,就会出现不知道那个程序先执行,那个程序后执行,如果程序挂掉,或者一直未被执行,那么这个时候是需要操作系统进行管理的。管理–先描述,再组织
先描述
当CPU处理数据前,操作系统会对每个进程的进行管理,形成一个结构体–task_struct,便于操作系统好管理,该结构体就放着进程的各个数据。
struct task_struct {
//进程的所有属性
//该进程对应的代码和属性地址
struct task_struct* next;
}
struct task_struct *pl = malloc(struct task_struct)
pl->…= XXX
p1->addr = 代码和数据的地址
再组织
所谓的对进程进行管理,就变成了进程对应的PCB进行相应的管理,PCB为结构体就就转化成对链表的增删改查。操作系统是通过对struct task_struct进行管理,而struct task_struct中相当于有许许多多的该进程对应的代码和属性地址,它通过 struct task_struct* next进行对每个进程向链接。操作系统只对PCB进行管理而不进行计算,当CPU进行计算的时候,操作系统就会把该进程放再前面让CPU进行处理。CPU就通过获取PCB的struct task_struc中的进程地址空间–一段范围,对内存中的该文件的数据进行识别,然后进行计算,进程地址空间后续会讲。
task_ struct内容分类
标示符: 描述本进程的唯一标示符,用来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执行的下一条指令的地址。 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。 其他信息
Linux中的-PCB
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合,被称之为PBC。Linux操作系统下的PCB是:task_struct–进程控制块(结构体)
Linux中task_struct用来控制管理进程,结构如下:
struct task_struct
{
//说明了该进程是否可以执行,还是可中断等信息
volatile long state;
//Flage 是进程号,在调用fork()时给出
unsigned long flags;
//进程上是否有待处理的信号
int sigpending;
//进程地址空间,区分内核进程与普通进程在内存存放的位置不同
mm_segment_t addr_limit; //0-0xBFFFFFFF for user-thead
//0-0xFFFFFFFF for kernel-thread
//调度标志,表示该进程是否需要重新调度,若非0,则当从内核态返回到用户态,会发生调度
volatile long need_resched;
//锁深度
int lock_depth;
//进程的基本时间片
long nice;//进程的调度策略,有三种,实时进程:SCHED_FIFO,SCHED_RR, 分时进程:SCHED_OTHER
unsigned long policy;
//进程内存管理信息
struct mm_struct *mm;
int processor;
//若进程不在任何CPU上运行, cpus_runnable 的值是0,否则是1 这个值在运行队列被锁时更新
unsigned long cpus_runnable, cpus_allowed;
//指向运行队列的指针
struct list_head run_list;
//进程的睡眠时间
unsigned long sleep_time;//用于将系统中所有的进程连成一个双向循环链表, 其根是init_task
struct task_struct *next_task, *prev_task;
struct mm_struct *active_mm;
struct list_head local_pages; //指向本地页面
unsigned int allocation_order, nr_local_pages;
struct linux_binfmt *binfmt; //进程所运行的可执行文件的格式
int exit_code, exit_signal;
int pdeath_signal; //父进程终止是向子进程发送的信号
unsigned long personality;
//Linux可以运行由其他UNIX操作系统生成的符合iBCS2标准的程序
int did_exec:1;
pid_t pid; //进程标识符,用来代表一个进程
pid_t pgrp; //进程组标识,表示进程所属的进程组
pid_t tty_old_pgrp; //进程控制终端所在的组标识
pid_t session; //进程的会话标识
pid_t tgid;
int leader; //表示进程是否为会话主管
struct task_struct *p_opptr,*p_pptr,*p_cptr,*p_ysptr,*p_osptr;
struct list_head thread_group; //线程链表
struct task_struct *pidhash_next; //用于将进程链入HASH表
struct task_struct **pidhash_pprev;
wait_queue_head_t wait_chldexit; //供wait4()使用
struct completion *vfork_done; //供vfork() 使用
unsigned long rt_priority; //实时优先级,用它计算实时进程调度时的weight值
//it_real_value,it_real_incr用于REAL定时器,单位为jiffies, 系统根据it_real_value//设置定时器的第一个终止时间. 在定时器到期时,向进程发送SIGALRM信号,同时根据
//it_real_incr重置终止时间,it_prof_value,it_prof_incr用于Profile定时器,单位为jiffies。
//当进程运行时,不管在何种状态下,每个tick都使it_prof_value值减一,当减到0时,向进程发送
//信号SIGPROF,并根据it_prof_incr重置时间.
//it_virt_value,it_virt_value用于Virtual定时器,单位为jiffies。当进程运行时,不管在何种//状态下,每个tick都使it_virt_value值减一当减到0时,向进程发送信号SIGVTALRM,根据
//it_virt_incr重置初值。
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_value;
struct timer_list real_timer; //指向实时定时器的指针
struct tms times; //记录进程消耗的时间
unsigned long start_time; //进程创建的时间//记录进程在每个CPU上所消耗的用户态时间和核心态时间
long per_cpu_utime[NR_CPUS], per_cpu_stime[NR_CPUS];
//内存缺页和交换信息://min_flt, maj_flt累计进程的次缺页数(Copy on Write页和匿名页)和主缺页数(从映射文件或交换
//设备读入的页面数); nswap记录进程累计换出的页面数,即写到交换设备上的页面数。
//cmin_flt, cmaj_flt, cnswap记录本进程为祖先的所有子孙进程的累计次缺页数,主缺页数和换出页面数。//在父进程回收终止的子进程时,父进程会将子进程的这些信息累计到自己结构的这些域中
unsigned long min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;
int swappable:1; //表示进程的虚拟地址空间是否允许换出
//进程认证信息
//uid,gid为运行该进程的用户的用户标识符和组标识符,通常是进程创建者的uid,gid//euid,egid为有效uid,gid
//fsuid,fsgid为文件系统uid,gid,这两个ID号通常与有效uid,gid相等,在检查对于文件//系统的访问权限时使用他们。
//suid,sgid为备份uid,gid
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
int ngroups; //记录进程在多少个用户组中
gid_t groups[NGROUPS]; //记录进程所在的组//进程的权能,分别是有效位集合,继承位集合,允许位集合
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;int keep_capabilities:1;
struct user_struct *user;
struct rlimit rlim[RLIM_NLIMITS]; //与进程相关的资源限制信息
unsigned short used_math; //是否使用FPU
char comm[16]; //进程正在运行的可执行文件名
//文件系统信息
int link_count, total_link_count;//NULL if no tty 进程所在的控制终端,如果不需要控制终端,则该指针为空
struct tty_struct *tty;
unsigned int locks;
//进程间通信信息
struct sem_undo *semundo; //进程在信号灯上的所有undo操作
struct sem_queue *semsleeping; //当进程因为信号灯操作而挂起时,他在该队列中记录等待的操作
//进程的CPU状态,切换时,要保存到停止进程的task_struct中
struct thread_struct thread;
//文件系统信息
struct fs_struct *fs;
//打开文件信息
struct files_struct *files;
//信号处理函数
spinlock_t sigmask_lock;
struct signal_struct *sig; //信号处理函数
sigset_t blocked; //进程当前要阻塞的信号,每个信号对应一位
struct sigpending pending; //进程上是否有待处理的信号
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
u32 parent_exec_id;
u32 self_exec_id;spinlock_t alloc_lock;
void *journal_info;
};
进程=内核数据结构(tast_struct)+进程对应的磁盘代码
查看进程
查看进程
myproc.c
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("我是一个进程!\n");
sleep(1);
}
return 0;
}
Makefile
myporc:myporc.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f myporc
查看进程脚本
ps ajx | head -1 && ps ajx | grep “myporc”

- Process ID(PID)
Linux中标识进程的一个数字,它的值是不确定的,是由系统分配的(但是有一个例外,启动阶段,kernel运行的第一个进程是init,它的PID是1,是所有进程的最原始的父进程),每个进程都有唯一PID,当进程退出运行之后,PID就会回收,可能之后创建的进程会分配这个PID- Parent Process ID(PPID)
字面意思,父进程的PID- Process Group ID(PGID)
PGID就是进程所属的Group的Leader的PID,如果PGID=PID,那么该进程是Group Leader- Session ID(SID)
和PGID非常相似,SID就是进程所属的Session Leader的PID,如果SID==PID,那么该进程是session leader- TPGID:控制终端进程组ID(由控制终端修改,用于指示当前前台进程组)
- STAT: 进程状态
- UID:用户标识码
- TIME:命令常用于测量一个命令的运行时间
进程在调度运行的时候,进程具有动态属性
见见系统调用
man getpid
 测试代码:
测试代码:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while(1)
{
printf("我是一个进程!,我的ID是:%d\n",getpid());
sleep(1);
}
return 0;
}

每次重新运行程序pid都会改变
因为每次都需要重新加载到内存,就意味着操作系统都会重新创建task_struct,重新分配pid

ls /proc

“/proc/[pid]”目录,pid为进程的数字ID,是个数值,每个运行着的进 程都有这么一个目录。

 查看父进程
查看父进程
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while(1)
{
printf("我是一个进程!,我的ID是:%d\n,父进程ID是:%d\n",getpid(),getppid());
sleep(1);
}
return 0;
}


命令行上启动的进程,一般它的父进程没有特殊情况的话,都是bash
通过系统调用创建进程-fork初识
运行 man fork 认识fork
fork有两个返回值
父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)

创建进程
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = fork();
if(ret < 0){
perror("fork");
return 1;
}
else if(ret == 0){ //child
printf("I am child : %d!, ret: %d\n", getpid(), ret);
}else{ //father
printf("I am father : %d!, ret: %d\n", getpid(), ret);
}
sleep(1);
return 0;
}

进程状态
宏观概念
 总结:
总结:
1.一个CPU一个运行队列
2.让进程入队列的本质是:将该进程的struct stsk_struct结构体对象放入运行队列中
3.进程PCB在runqueue,就是R–运行状态,而不是这个进程正在运行才叫运行状态
4.进程不只会等待(占用)CPU资源,也可能随时随地要外设资源
5.所谓的进程不同的状态,本质是进程在不同的队列中,等待某种资源
挂起状态

阻塞和挂起的区别
挂起了一定阻塞,阻塞了不一定挂起。阻塞时该进程的代码和数据都在内存中,当内存不足时,就会产生挂起状态该内存的数据和代码就会被操作系统放进磁盘中
Linux操作系统的的状态
static const char * const task_state_array[] = {
“R (running)”, /* 0 */
“S (sleeping)”, /* 1 */
“D (disk sleep)”, /* 2 */
“T (stopped)”, /* 4 */
“t (tracing stop)”, /* 8 */
“X (dead)”, /* 16 */
“Z (zombie)”, /* 32 */
};
R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里。
S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠(interruptible sleep))。
**D磁盘休眠状态(Disk sleep):**有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的 进程通常会等待IO的结束。
T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。
**X死亡状态(dead):**这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
进程状态查看
ps aux / ps axj 命令
R状态–运行状态
#include <stdio.h>
#include <unistd.h>
int main()
{
int a=0;
while(1)
{
a=1+2;
};
return 0;
}

S状态–阻塞状态
#include <stdio.h>
#include <unistd.h>
int main()
{
int a=0;
while(1)
{
a=1+2;
printf("当前a的值是:%d\n ",a);
};
return 0;
}

为什么是S状态?
因为printf会访问显示器,显示器是外设的输入输出速度比较慢,CPU就会等待显示器就绪。99%都是在等I/O就绪,1%才是执行打印代码。所以当我们去查的时候,几乎大概率都会是S状态
t状态 --停止状态
进程处于此状态表示该进程正在被追踪,比如 gdb 调试进程:

T状态–停止状态
测试代码
#include <stdio.h>
#include <unistd.h>
int main()
{
int a=0;
while(1)
{
a=1+2;
};
return 0;
}
kill -l

kill -19 [pid]–停止进程

后台运行
kill -18 [pid]–运行进程

后台运行–‘+’的消失
前台运行–有‘+’
 用Ctrl+c不能杀死
用Ctrl+c不能杀死
就用kill -9 [pid]

总结:
先将该进程暂停后,再运行。进程状态前面的 + 号消失了,该进程变成了后台程序。但是对于后台进程来说,我们只能通过 kill 命令来杀死它。
D状态–深度睡眠
深度睡眠TASK_UNINTERRUPTIBLE:不可被信号唤醒;
浅度睡眠TASK_INTERRUPTIBLE:唤醒方式,等到需要的资源,响应信号;
深度睡眠场景:
有些场景是不能响应信号的,比如读磁盘过程是不能打断的,NFS也是;
执行程序过程中,可能需要从磁盘读入可执行代码,假如在读磁盘过程中,又有代码需要从磁盘读取,就会造成嵌套睡眠。逻辑做的太复杂,所以读磁盘过程不允许打断,即只等待IO资源可用,不响应任何信号;
应用程序无法屏蔽也无法重载SIGKILL信号,深度睡眠可以不响应SIGKILL kill-9信号;
注意:处于深度睡眠状态的进程既不能被用户杀掉,也不能被操作系统杀掉,只能通过断电,或者等待进程自己醒来。深度睡眠一般只会在高IO的情况发生下,且如果操作系统中存在多个深度睡眠状态的程序,那么说明该操作系统也即将崩溃了。
X–死亡状态
死亡状态代表着一个进程结束运行,该进程对应的PCB以及代码和数据全部被操作系统回收。
Z–僵尸状态
僵死状态(Zombies)是一个比较特殊的状态。当进程退出并且父进程(使用wait()系统调用,后面讲)没有读取到子进程退出的返回代码时就会产生僵死(尸)进程
僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码。
所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态

两个特殊的进程
Z(zombie)-僵尸进程
僵尸进程是处于僵尸状态的进程
脚本代码
while :; do ps axj | head -1 && ps axj |grep myprocess |grep -v grep; sleep 1; done
测试代码
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//child
while(1){
printf("I am child process, pid: %d, ppid: %d\n", getpid(), getppid());
sleep(5);
exit(1);
}
}
else
{
//parent
while(1)
{
printf("I am parent proceass, pid: %d, ppid: %d\n", getpid(), getppid()); sleep(1);
}
}
return 0;
}
子进程:pid= 26655
父进程:ppid=26654

当运行一段时间后的显现,26654进程因为打印变成S状态,由于26655退出了该进程变成僵尸进程。

在上面测试代码中
if(id == 0)
{
//child
while(1){
printf(“I am child process, pid: %d, ppid: %d\n”, getpid(), getppid());
sleep(5);
exit(1);
}
}
子进程通过5秒后退出,结合观察得到再子进程(26655)退出后,父进程(26654)变成了僵尸状态。
26654 26655 26654 5238 pts/0 26654 Z+ 1005 0:00 [myprocess]
的意思失效
意味着该进程是失效的,死掉的
当我们再观察进程时,我们发现该进程不在了,其原因是关掉了父进程,该失效的子进程被系统回收了。

僵尸进程危害
进程的退出状态必须被维持下去,父进程需要一直知道子进程的状态,随时进行处理。可父进程如果一直不读取,那子进程就一直处于Z状态。
维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中,换句话说,Z状态一直不退出,PCB一直都要维护。
那一个父进程创建了很多子进程,就是不回收,就会造成内存资源的浪费,因为数据结构对象本身就要占用内存,想想C中定义一个结构体变量(对象),是要在内存的某个位置进行开辟空间!–内存泄漏
孤儿进程
测试代码
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//child
while(1){
printf("I am child process, pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
}
else
{
//parent
while(1)
{
printf("I am parent proceass, pid: %d, ppid: %d\n", getpid(), getppid()); sleep(1);
}
}
return 0;
}
最开始代码跑起来时,父进程pid=8644,bash=5238;子进程的pid=8645,子进程的父进程8644;他们的运行状态都是S状态–因为在打印就会访问I/O;

当我们销毁子进程时,kill -9 8645;我们发现子打印进程不在了,但是子进程的状态还在,变成了Z状态,这个时候就只能等父进程退出,让操作系统进行回收。

当我们杀掉父进程时,子进程被操作系统领养了,这个过程就叫做孤儿进程
当整个进程变成孤儿了,我们发现我们用Ctrl + c 是不能退出的;我们细心就会发现最开始子进程是S+当变成孤儿进程了,它的状态就是S了。说明了该程序变成了后台程序。

那么这个时候我们就只有用kill -9 16866,杀掉子进程了

进程优先级
基本概念
cpu资源分配的先后顺序,就是指进程的优先权(priority)。
优先权高的进程有优先执行权利。配置进程优先权对多任务环境的linux很有用,可以改善系统性能。 还可以把进程运行到指定的CPU上,这样一来,把不重要的进程安排到某个CPU,可以大大改善系统整体性能。
查看系统进程
在linux或者unix系统中,用ps –l命令则会类似输出以下几个内容:

我们很容易注意到其中的几个重要信息,有下:
UID : 代表执行者的身份
PID : 代表这个进程的代号
PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
PRI :代表这个进程可被执行的优先级,其值越小越早被执行
NI :代表这个进程的nice值
PRI and NI
PRI也还是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高
那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值
PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice
这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行 所以,调整进程优先级,在Linux下,就是调整进程nice值
nice其取值范围是-20至19,一共40个级别
用top命令更改已存在进程的nice:
top
1.非root用户:sudo top 进入top
2.在top中按r
3.输入进程pid
4.输入nice值
这里是输入nice值为100,我们发现最大区间是99 -19

这里是输入nice值为-100,所以我们发现最小大区间是60-20

经过上面两个例子,我们就发现其实我们只能改变范围是-20至19,一共40个级别
我们再观察一个场景,当我们把nice值改9的时候,我们发现值变成89,那么就得出结论:每次改nice值都在默认nice值的基础上进行改动,而不是修改之后。

其他概念
竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高 效完成任务,更合理竞争相关资源,便具有了优先级 独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰 并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行 并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为 并发
进程切换
测试代码
#include <stdio.h>
int main()
{
int a=10;
int b=10;
int c=b+a;
printf("%d\n",c);
a=20;
b=30;
c=b+a;
printf("%d\n",c);
return 0;
}
我们从该代码中不难看出,a,b,c都是临时变量,在以前c语言也知道,他们的数据都是存放在寄存器里的,这里我们发现寄存器里的数据是可以发生改变的。这里我们进入vs2013查看反汇编,数据都是加载到寄存器中的。

在这里有一个概念需要知道:CPU虽然只有一套寄存器,但是寄存器的数据是属于当前进程的。这里的寄存器其实更偏向于寄存器内的数据,而不是寄存器硬件。

在这个过程中运行的时候,占有CPU进程不是一直要占有到进程结束!因为CPU虽然只有一套寄存器而且还要对其他进程进行处理,进程在运行的时候,都会有自己的时间片

操作系统会对每个进程进行设置一个时间片,让CPU去读取进程数据进行处理,就会有进入/退出–进程的切换。在这个切换的过程中寄存器数据需要被保护和恢复。
进程在切换的时候,要进行进程的上下文保护,当进程在恢复运行的时候,要进行上下文的恢复。
在任何时刻,CPU里面的寄存器里面的数据,看起来是在大家都能看到的寄存器上,但是,寄存器内的数据,只属于当前运行的进程!
寄存器被所有进程共享,寄存器内的数据,是每个进程各自私有的—上下文数据
环境变量
基本概念
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数 如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。 环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性
常见环境变量
PATH : 指定命令的搜索路径

我们直接输入test我们发现,编译不起

我们将我们写的可执行程序放入usr/sbin路径中,需要注意的这个文件目录只有root用户可以进去
 这种是不支持的,会污染指令池;
这种是不支持的,会污染指令池;
sudo rm /usr/bin/test.o —删除

一般情况下,我们是选择用
exprot PATH=$PATH:
 我们发现使用exprot PATH=$PATH: test.o 的路径还是在11-19中
我们发现使用exprot PATH=$PATH: test.o 的路径还是在11-19中
总结:
1.PATH就是系统默认的搜索路径
2.系统的指令能被找到就是因为环境变量PATH本来就默认带了系统对于的路径搜索
3.which底层实现就使用环境变量PATH来进行路径搜索
系统会默认将.bash_profile执行一次,将环境变量导到shell中,也就是说环境变量的配置也就是.bash_profile 再启动的时候加载到bash中

vim .bash_profile–进入.bash_profile
HOME : 指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)

用root和普通用户,分别执行 echo $HOME ,对比差异 . 执行 cd ~; pwd ,对应 ~ 和 HOME 的关系
SHELL : 当前Shell,它的值通常是/bin/bash。

和环境变量相关的命令
echo: 显示某个环境变量值
export: 设置一个新的环境变量
env: 显示所有环境变量
unset: 清除环境变量
set: 显示本地定义的shell变量和环境变
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
unset: 清除环境变量
set: 显示本地定义的shell变量和环境变
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。
[外链图片转存中…(img-r7IA7YAa-1714720427100)]
本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 8171
8171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









