







前言
pytorch是深度学习的一种框架,在科研论文中常常用到,最近开始学习pytorch,写一下自己对于一些方面的心得体会。
dataset是数据集,可以理解为一副扑克牌,dataloader是用来加载数据集的,可以理解为一次拿去多少张数据,或者怎么样去拿,transform是用来进行数据预处理的。
1.Dataset
dataset是一个抽象类,必须要实现的__getitem__(),len()方法。以下是基本的Dataset框架:
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self,dir):
pass
def __getitem__(self, index):
return img,target
def __len__(self):
return len()
在实际情况下,要根据具体的情况下创建自己的数据集,以下是我自定义的数据集:
class Mydata(Dataset):
def __init__(self, root_dir, transform=None):
# transform:数据预处理 ,transform预处理需要图像的数据类型为PIL,不是numpy
self.root_dir = root_dir
self.label_name = self.get_img_label(root_dir)
self.data_info = self.get_img_info(self.root_dir, self.label_name)
self.transform = transform
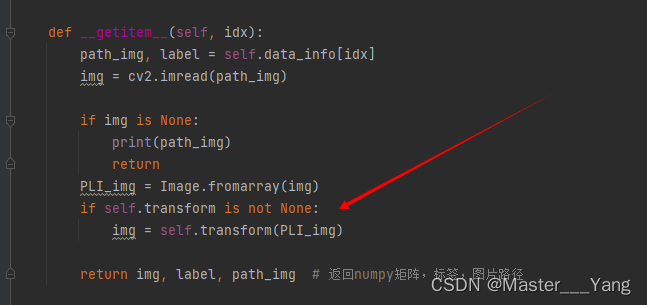
def __getitem__(self, idx):
path_img, label = self.data_info[idx]
img = cv2.imread(path_img)
if img is None:
print(path_img)
return
PLI_img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(PLI_img)
return img, label, path_img # 返回numpy矩阵,标签,图片路径
def __len__(self):
return len(self.data_info)
# 获取图像类别分类
@staticmethod
def get_img_label(data_dir):
if not os.path.exists(data_dir): # 路径不存在
return
if not os.path.isdir(data_dir): # 路径不是目录
return
label = {}
for root, dirs, files in os.walk(data_dir):
count = 0
for sub_dir in dirs:
label[sub_dir] = count
count += 1
return label
# 获取图像信息
@staticmethod
def get_img_info(data_dir, label_name):
if not os.path.exists(data_dir): # 路径不存在
return
if not os.path.isdir(data_dir): # 路径不是目录
return
data_info = list()
for root, dirs, files in os.walk(data_dir):
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir)) # 获取合并目录下的所有文件列表
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names)) # 过滤器
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
if not imghdr.what(path_img).__eq__("GIF"): #过滤掉gif图像
label = label_name[sub_dir]
data_info.append((path_img, label))
return data_info
使用:
test_data = Mydata(root_dir)
print(test_data.label_name)
print(test_data.__len__())
#{'cat': 0, 'dog': 1, 'horse': 2, 'pig': 3}
#238
2.Dataloader:
在pytorch官网上查看dataloader文档,方法的参数众多,但是都有默认值,因此只需要传递给最关键的dataset给dataloader即可调用。

batch_size:一次加载多少个数据
shuffle:第二次取数据是否与第一次保持一致,默认是False,保持一直。更常用是设置为True
num_workers:采用单个进程还是多个进程来进行加载。默认0是代表在主进程下加载
drop_last:是否保留不能为一组的数据,默认为False,保留数据
data_load = DataLoader(test_data, batch_size=6, shuffle=True)
for data in data_load:
imgs, targets, paths = data
print(imgs.shape, targets, paths)
3.Transform
用于数据预处理。比如在上述相对数据图像进行预处理:
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()
])
test_data = Mydata(root_dir, transform)
注:transform预处理需要图像的数据类型为PIL,不是numpy
transform的一些图像预处理方法可以翻看这篇博客:
https://blog.csdn.net/u011995719/article/details/85107009















 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











