






目录
dataset数据
在pytorch中如何读取数据主要有两类,一类是Dataset,另外一类是Dataloader,Dataset主要是提供一种方式去获取数据及其label,Dataloader为网络提供其不同的数据形式。
dataset:获取每一个数据和label
dataloader:提供不同的数据形式

下面为提供的数据集,然后分别打开jupyter和pycharm新建python项目

在jupyter键入如下,注意,在jupyter中使用help,可以得到排版很好的解释,在pycharm控制器中排版很混乱。
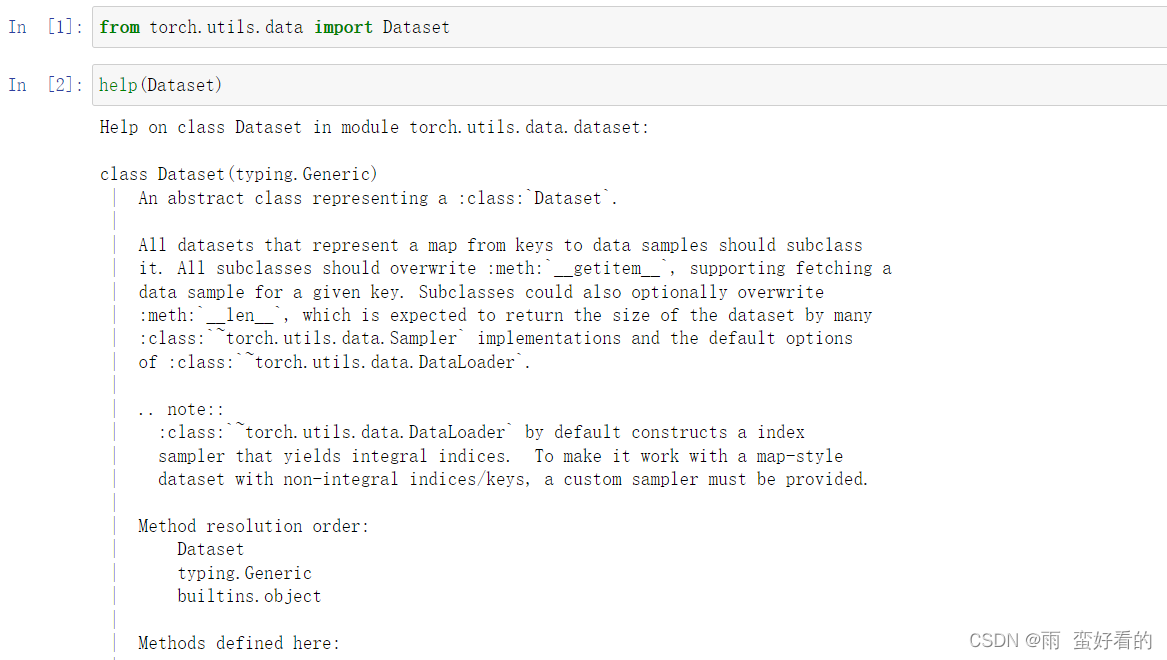
pycharm中加载数据集方法:新建工程-open in-exploar,然后将数据集复制在该工程下。
pycharm中使用 Ctrl+P 可以看函数需要传入什么参数。
使用控制台可以显示相关的属性,可以进行调试
读取图片
from PIL import Image
img_path = "dataset/train/bees_image/16838648_415acd9e3f.jpg"上述地址在相对路径中,数据集已经加载到项目,python控制台实时创建了相应的变量,并显示了类型。显示为字符串类型。
![]()
如果要读取图片使用以下代码。
from PIL import Image
img_path = "dataset/train/bees_image/16838648_415acd9e3f.jpg"
img = Image.open(img_path)![]()
并创建了img的变量,在里面会显示img的属性,比如size等。如果要显示图片
img.size
Out[6]: (500, 450)
img.show()首先我们要获取图片的地址,如果说我们想要通过索引的方式进行获取,可以通过 OS(operating system)(python中常用的系统的库)通过相应的索引来获取。如果想要获取所有的文件
dir_path = "dataset/train/bees_image"
import os
img_path_list = os.listdir(dir_path) 
我们可以看到第一个数组对应的第一个图片等,如果访问第一个图片的话,就可以输入以下代码
img_path_list[0]
Out[11]: '1092977343_cb42b38d62.jpg'from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir = root_dir #大目录
self.label_dir = label_dir #子目录
self.path = os.path.join(self.root_dir,self.label_dir) #拼接
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
展示图片
root_dir = "dataset/train"
ants_label_dir = "bees_image"
ants_dataset = MyData(root_dir,ants_label_dir)
img,label = ants_dataset[0] #展示第一张
img.show()数据集的相加
root_dir = "dataset/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
train_dataset = ants_dataset+bees_dataset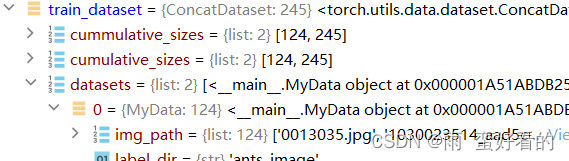
TensorBoard使用
介绍
使用help查看文档或者按住Ctrl鼠标点击查看
介绍:将条目直接写入 log_dir 中的事件文件以供 TensorBoard 使用。`SummaryWriter` 类提供了一个高级 API,用于在给定目录中创建事件文件,并向其中添加摘要和事件。
导入库函数,utils就是torch中包括的常用的个工具箱集合,很常用
from torch.utils.tensorboard import SummaryWriter
使用方法
首先实例化Writer
writer = SummaryWriter(log_dir='logs',flush_secs=60)
- log_dir:tensorboard文件的存放路径
- flush_secs:表示写入tensorboard文件的时间间隔
常用函数-add_scalar()
add_scalar()函数的目的是添加一个标量数据(scalar data)到summary中,他怎么使用。

运行以下程序,左侧会有一个logs的文件夹,tensorboard的事件文件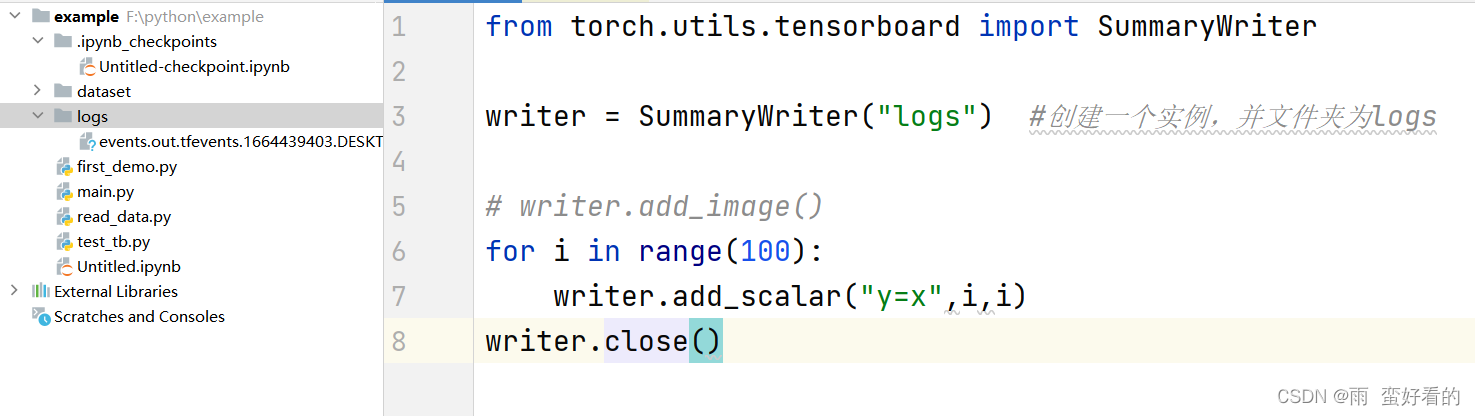
打开上述事件文件,使用terminal,使用以下指令打开,默认打开的是6006主机端口,但是都用一个端口的话就很麻烦,我们可以指定端口,按CTRL+C退出,再指定。点开端口以后即可打开。
tensorboard --logdir=logs #logdir=事件文件所在文件夹名

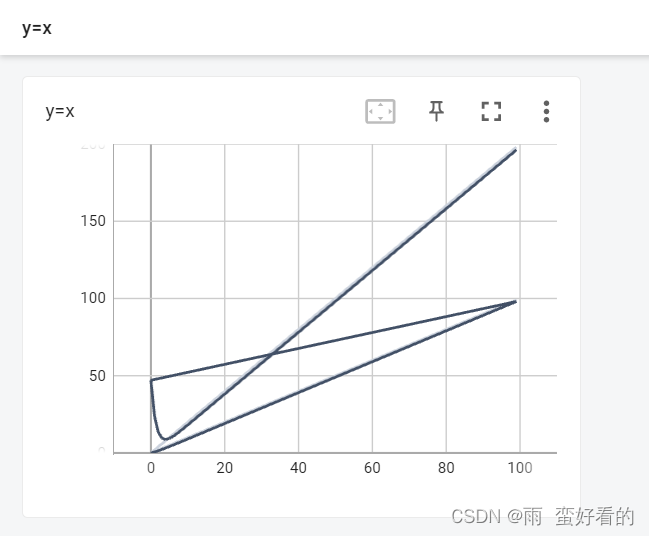
以下为绘制的 y=x 的图像,如果绘制 y = 2x,但是 writer.add_scalsr("y=x",i,i ) 里的 tag 仍为 y=x,这样就会导致在原有的图像上叠加 y = 2x 同时会出现拟合曲线,如下图,解决办法是:把左侧的事件文件删除,然后重新运行,terminal重新指定端口。

常用函数-add_image()
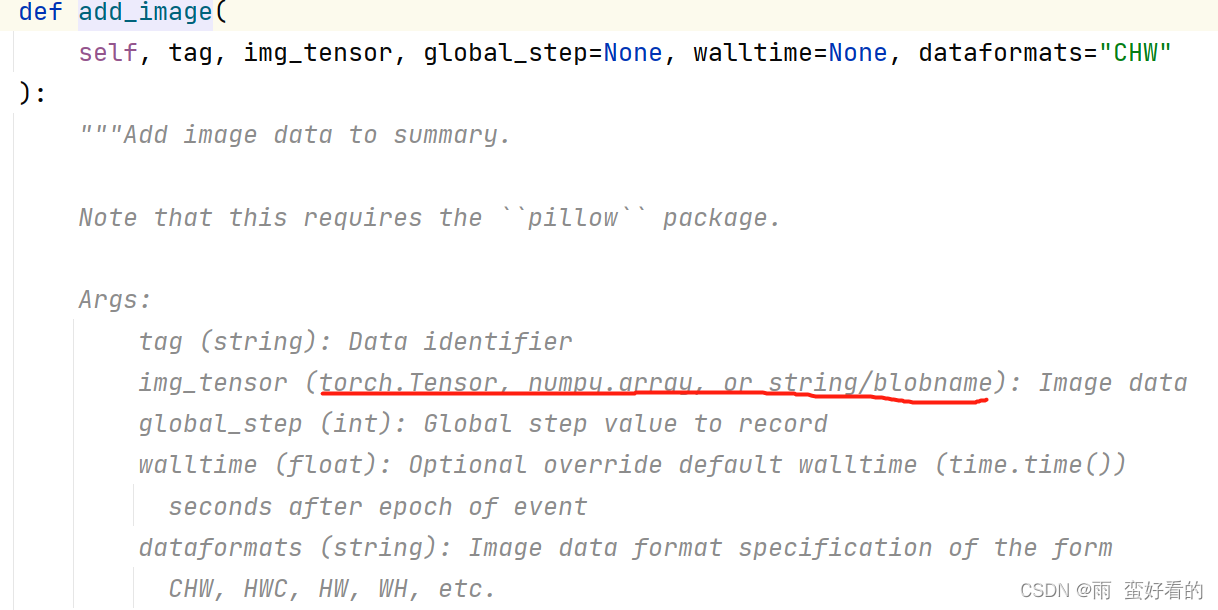
下面我们查看我们训练的数据集的图像类型,如果不是以上的类型我们需要进行转换,我们可以看到图片的类型不是 add_image() 可以传入的参数类型(也可以通过右侧的变量显示看到类型),因此我们要进行格式转换,转换方法见下一级标题。
img_path="dataset/train/ants_image/0013035.jpg"
from PIL import Image
img = Image.open(img_path)
print(type(img))
<class 'PIL.JpegImagePlugin.JpegImageFile'>转化完成后使用 add_image() 打开,但是运行后发现报错,我们查看函数的说明
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs") #创建一个实例,并文件夹为logs
image_path = "dataset/train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path) #打开图片,此时为PIL类型
img_array = np.array(img_PIL) #将图片转化为numpy
writer.add_image("test",img_array,1) #调用函数,global参数传入第一步
for i in range(100):
writer.add_scalar("y=x",2*i,i)
writer.close() 我们在python控制台中查看 img_array 的shape类型,发现三通道确实是 3 在后面的类型,我们将进行修改,然后在terminal中打开即可查看图片。如果我们想要查看蜜蜂,我们将相对地址修改为蜜蜂,然后step步骤改为2,打开即可查看蜜蜂,拖动即可进行切换(因为有两步)。如果单独看蜜蜂只需要把 title 修改运行即可,这样设定步骤可以得到训练日志
我们在python控制台中查看 img_array 的shape类型,发现三通道确实是 3 在后面的类型,我们将进行修改,然后在terminal中打开即可查看图片。如果我们想要查看蜜蜂,我们将相对地址修改为蜜蜂,然后step步骤改为2,打开即可查看蜜蜂,拖动即可进行切换(因为有两步)。如果单独看蜜蜂只需要把 title 修改运行即可,这样设定步骤可以得到训练日志




numpy.array()对PIL图片转换
import numpy as np
img = np.array(img)
print(type(img))
<class 'numpy.ndarray'>transform工具
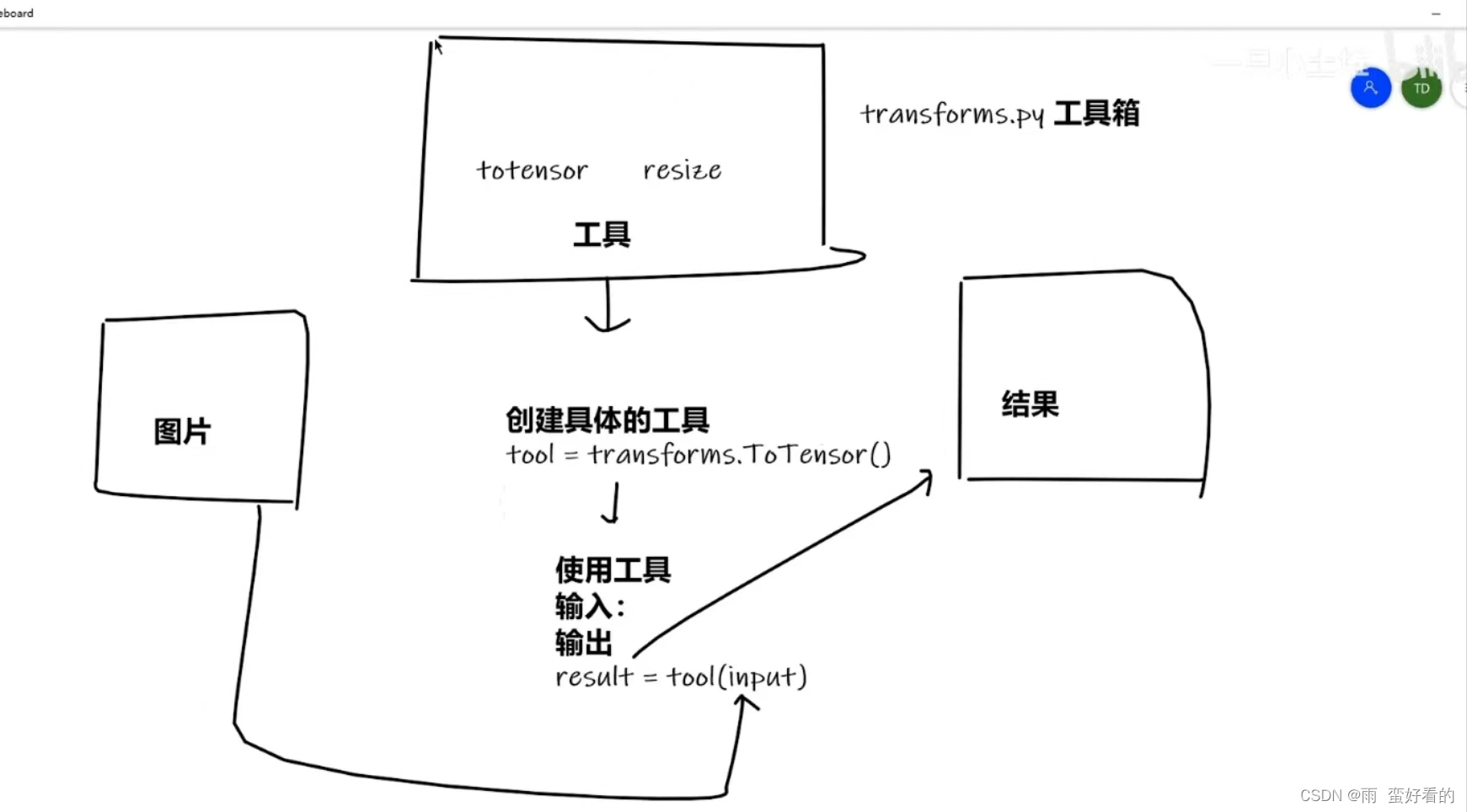
打开transform函数,在这个函数中,点击structure可以看到里面定义的class,常用的就是前面的几个类。transform,就是拿一些图片,从transform中挑选工具(不同的class)然后输出想要的图片的结果。
(13条消息) pytorch中transform的使用_NNNJY的博客-CSDN博客_pytorch transform
transform.totensor
totensor中的_call_方法,使用魔法方法调用了里面的_call_函数才可以传参数,关于内置call如下
class person:
def __call__(self, name):
print("HELLO"+name)
def hello(self,name):
print("hello"+name)
a = person()
a("zhangsan")
a.hello("zhangsan")
HELLOzhangsan
hellozhangsan
tensor是张量,也就是数组,高维数组
为什么要转tensor类型?因为它包装了神经网络的一些参数
totensor也考虑了常用的一些类型 PILimg和numpy
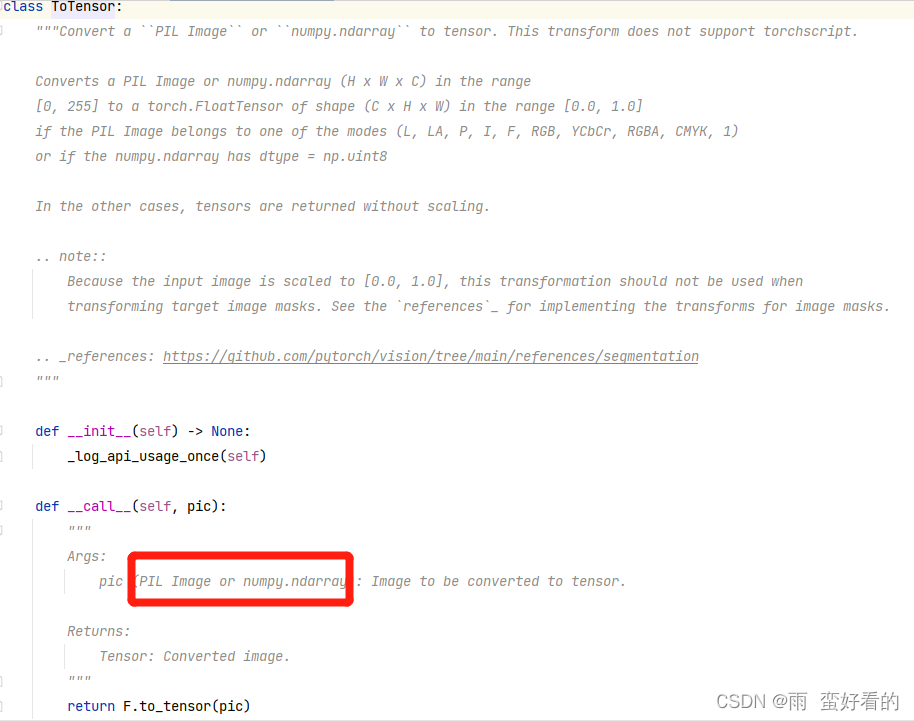
from PIL import Image
from torchvision import transforms
#python 用法 -》tensor数据类型
#通过transforms.totensor去看两个问题
#1、transform如何使用 2、tensor数据类型
img_path = "dataset/train/ants_image/6240338_93729615ec.jpg"
img = Image.open(img_path)
print(img)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(tensor_img)进行读取图片,再通过terminal,打开端口。
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
from torchvision import transforms
#python 用法 -》tensor数据类型
#通过transforms.totensor去看两个问题
#1、transform如何使用 2、tensor数据类型
img_path = "dataset/train/ants_image/6240338_93729615ec.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
writer.add_image("tensor_img",tensor_img)
writer.close()opencv-numpy类型读取

opencv的下载
安装 opencv 或者安装 tensorboard,挡在pycharm中的terminal中安装不上时,使用anaconda中的pytoch环境安装上述包,即可安装完成。


常见transform
关注(输入,输出,作用)图片的格式(*PIL,*tensor,*narrays)方法(Image.open,totensor,cv.imread)
从网络下载图片,并进行读取。
compose函数
先中心裁剪---》再转化为tensor类型
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
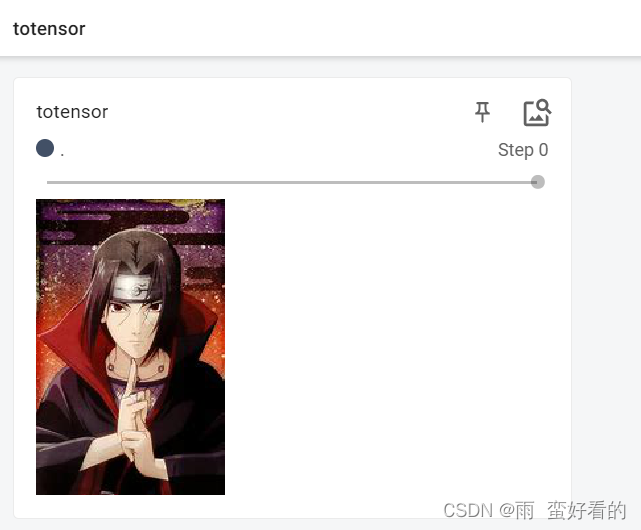
img = Image.open("image/OIP-C.jpg")
#将PIL通过transfor中的totensor转换为了tensor类型
#totensor的使用
tran_totensor = transforms.ToTensor()
img_tensor = tran_totensor(img)
writer.add_image("totensor",img_tensor)
normalize函数

#normalize
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
writer.add_image("normalize",img_norm)左图为0.5归一化,右图为修改部分值后对比,记着改add_image的步骤


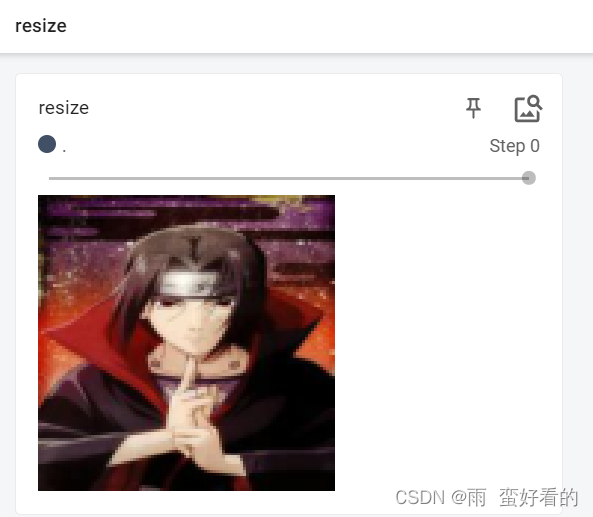
resize函数
#resize
print(img.size)
trans_resize = transforms.Resize((100,100))
img_resize = trans_resize(img)
print(img_resize)
将原有的尺寸裁剪至100×100 ,图见上。

#resize
print(img.size)
trans_resize = transforms.Resize((100,100))
img_resize = trans_resize(img)
print(img_resize)
img_resize = tran_totensor(img_resize)
writer.add_image("resize",img_resize)torchvision数据集的使用
pytorch官网有内置的数据集,现在讲torchvision和transform的联合使用。通过torchvision-download设置为true,可以直接下载。

进行下载,左侧可以看到文件夹数据集
import torchvision
from torch.utils.tensorboard import SummaryWriter
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0]) #(<PIL.Image.Image image mode=RGB size=32x32 at 0x16F2DB687C0>, 3)
img,target = test_set[0] #img对应第一个图片,target对应后面的3
print(img)
print(target)
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
print(test_set[0]) #已经转化为了tensor数据类型
writer = SummaryWriter("abc") #把日志文件保存到abc
for i in range(10): #测试数据集的前十张照片
img,target = test_set[i]
writer.add_image("testset",img,i)
writer.close()
然后通过terminal命令行打开即可
dataloader
加载器,讲数据加载到神经网络中,从dataset中取数据,从torch官网查看,参数基本都有默认值,只有dataset没有默认值
import torchvision
from torch.utils.data import DataLoader
#准备测试集
test_data = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor())
test_loader= DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
#测试数据集第一张图片以及target
img,target = test_data[0]
print(img.shape)
print(target)
for data in test_loader:
imgs,targets = data
print(imgs.shape)
print(targets)
#结果torch.Size([3, 32, 32])
#3如果想要展示,使用summarywriter
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images("test_data",imgs,step)
step = step+1
writer.close()













 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









