







第五章 深度学习
十、生成对抗网络(GAN)
6. DCGAN的实现
6.1 任务目标
实现DCGAN,并利用其合成卡通人物头像。
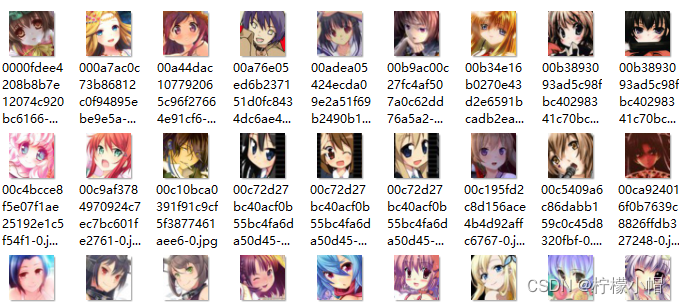
6.2 数据集
样本内容:卡通人物头像
样本数量:51223个
6.3 代码清单
6.3.1 avatar.py
import os
import scipy.misc
import numpy as np
from glob import glob
# Avatar(化身)类
class Avatar:
def __init__(self):
self.data_name = 'faces'
self.source_shape = (96, 96, 3)
self.resize_shape = (48, 48, 3)
self.crop = True # 裁剪
self.img_shape = self.source_shape if not self.crop else self.resize_shape # 图片形状
self.img_list = self._get_img_list() # 加载所有图片
self.batch_size = 64 # batch_size大小
self.batch_shape = (self.batch_size,) + self.img_shape
self.chunk_size = len(self.img_list) // self.batch_size # 总批次数量 = 样本数 / 批次大小
def _get_img_list(self):
"""
加载所有图片样本路径
:return:所有图片样本路径列表
"""
path = os.path.join(os.getcwd(), self.data_name, '*.jpg')
return glob(path)
def _get_img(self, name):
"""
读取图像数据
:param name: 图片路径
:return: 图像数据
"""
assert name in self.img_list
img = scipy.misc.imread(name).astype(np.float32) # 读取图像
assert img.shape == self.source_shape
return self._resize(img) if self.crop else img # 调整大小并返回
def _resize(self, img):
h, w = img.shape[:2]
resize_h, resize_w = self.resize_shape[:2]
crop_h, crop_w = self.source_shape[:2]
j = int(round((h - crop_h) / 2.))
i = int(round((w - crop_w) / 2.))
cropped_image = scipy.misc.imresize(img[j:j + crop_h, i:i + crop_w], [resize_h, resize_w])
return np.array(cropped_image) / 127.5 - 1.
@staticmethod
def save_img(image, path):
scipy.misc.imsave(path, image)
return True
def batches(self):
start = 0
end = self.batch_size
for _ in range(self.chunk_size):
name_list = self.img_list[start:end]
imgs = [self._get_img(name) for name in name_list]
batches = np.zeros(self.batch_shape)
batches[::] = imgs
yield batches
start += self.batch_size
end += self.batch_size
if __name__ == '__main__':
avatar = Avatar()
batch = avatar.batches()
b = next(batch)
for num in range(len(b)):
avatar.save_img(b[num], 'samples' + os.sep + str(num) + '.jpg')
6.3.2 avatar_model.py
import os
import math
import numpy as np
import tensorflow as tf
from datetime import datetime
# from avatarDcgan.avatar import Avatar
from avatar import Avatar
class AvatarModel:
def __init__(self):
self.avatar = Avatar()
# 真实图片shape (height, width, depth)
self.img_shape = self.avatar.img_shape # (48,48,3)
# 一个batch图片shape (batch, height, width, depth)
self.batch_shape = self.avatar.batch_shape
# 一个batch包含的图片数量
self.batch_size = self.avatar.batch_size
# batch数量
self.chunk_size = self.avatar.chunk_size
self.noise_img_size = 100 # 白噪声图片大小
self.gf_size = 64 # 卷积转置通道数量
self.df_size = 64 # 卷积输出通道数量
self.epoch_size = 1 # 训练循环次数
self.learning_rate = 0.0002 # 学习率
self.beta1 = 0.5 # 优化指数衰减率
self.sample_size = 64 # 生成图像数量(和avatar类中batch_size数量要一致, 不然生成图像报错)
@staticmethod
def conv_out_size_same(size, stride):
"""
计算每层高度、宽度
:param size:
:param stride:
:return:
"""
return int(math.ceil(float(size) / float(stride)))
@staticmethod
def linear(images, output_size, stddev=0.02, bias_start=0.0, name="Linear"):
"""
计算线性模型 wx + b
:param images: 输入数据 (x)
:param output_size: 输出值大小
:param stddev: 创建正态分布张量的标准差
:param bias_start: 偏置初始值
:param name: 变量作用域名称
:return: 返回计算结果及参数
"""
shape = images.get_shape().as_list() # 取出输入数据形状并转换为列表
with tf.variable_scope(name):
w = tf.get_variable("w", # 名称
[shape[1], output_size], # 矩阵行、列
tf.float32, # 类型
tf.random_normal_initializer(stddev=stddev)) # 初始值
b = tf.get_variable("b", # 名称
[output_size], # 个数等于列数
initializer=tf.constant_initializer(bias_start)) # 初始值
return tf.matmul(images, w) + b, w, b
@staticmethod
def batch_normailizer(x, epsilon=1e-5, momentum=0.9, train=True, name="batch_norm"):
"""
批量归一化
:param x: 输入
:param epsilon: 给一个很小的值,避免除数为0的情况
:param momentum: 衰减系数, 推荐使用0.9
:param train: 图否处于训练模式
:param name: 变量作用域名称
:return:
"""
with tf.variable_scope(name):
return tf.contrib.layers.batch_norm(x, # 输入
decay=momentum, # 衰减系数, 推荐使用0.9
updates_collections=None,
epsilon=epsilon, # 避免被零除
scale=True, # 是否缩放
is_training=train) # 图否处于训练模式
@staticmethod
def conv2d(images, output_dim, stddev=0.02, name="conv2d"):
"""
二维卷积
:param images: 图像数据
:param output_dim: 输出数据大小
:param stddev: 创建正态分布张量的标准差
:param name: 变量作用域名称
:return:
"""
with tf.variable_scope(name):
# filter: [height, width, in_channels, output_channels]
filter_shape = [5, 5, images.get_shape()[-1], output_dim]
strides_shape = [1, 2, 2, 1] # 步长
w = tf.get_variable("w", # 名称
filter_shape,
initializer=tf.random_normal_initializer(stddev=stddev)) # 初始值
b = tf.get_variable("b", # 名称
[output_dim], # 偏置数量
initializer=tf.constant_initializer(0.0)) # 初始值
conv = tf.nn.conv2d(images, w, strides=strides_shape, padding="SAME") # 卷积运算
conv = tf.reshape(tf.nn.bias_add(conv, b), conv.get_shape())
return conv
@staticmethod
def deconv2d(images, output_shape, stddev=0.02, name="deconv2d"):
"""
反向卷积(也称为转置卷积)
:param images: 图像数据
:param output_dim: 输出数据大小
:param stddev: 创建正态分布张量的标准差
:param name: 变量作用域名称
:return:
"""
with tf.variable_scope(name):
# 卷积核形状
filter_shape = [5, 5, output_shape[-1], images.get_shape()[-1]]
strides_shape = [1, 2, 2, 1] # 步长
w = tf.get_variable("w", # 名称
filter_shape,
initializer=tf.random_normal_initializer(stddev=stddev)) # 初始值
b = tf.get_variable("biases", # 名称
[output_shape[-1]], # 偏置数量
initializer=tf.constant_initializer(0.0)) # 初始值
deconv = tf.nn.conv2d_transpose(images,
w,
output_shape=output_shape,
strides=strides_shape)
deconv = tf.nn.bias_add(deconv, b)
return deconv, w, b
@staticmethod
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)
def generator(self, noise_imgs, train=True):
"""
生成器
:param noise_imgs: 输入(白噪声)
:param train: 是否为训练模式
:return:
"""
with tf.variable_scope("generator"):
# 计算每一层的高、宽
s_h, s_w, _ = self.img_shape # 48*48*3
s_h2, s_w2 = self.conv_out_size_same(s_h, 2), self.conv_out_size_same(s_w, 2) # 24,24
s_h4, s_w4 = self.conv_out_size_same(s_h2, 2), self.conv_out_size_same(s_w2, 2) # 12,12
s_h8, s_w8 = self.conv_out_size_same(s_h4, 2), self.conv_out_size_same(s_w4, 2) # 6,6
s_h16, s_w16 = self.conv_out_size_same(s_h8, 2), self.conv_out_size_same(s_w8, 2) # 3,3
# layer 0: 输入层
# 对输入噪音图片进行线性变换
z, h0_w, h0_b = self.linear(noise_imgs,
self.gf_size * 8 * s_h16 * s_w16) # 64*8*3*3=4608
# reshape为合适的输入层格式
h0 = tf.reshape(z, [-1, s_h16, s_w16, self.gf_size * 8]) # [-1, 3, 3, 512]
# 批量归一化, 加快收敛速度
h0 = self.batch_normailizer(h0, train=train, name="g_bn0")
h0 = tf.nn.relu(h0) # 激活
# layer 1: 反卷积进行上采样(对图像填充数据进行放大)
h1, h1_w, h1_b = self.deconv2d(h0,
[self.batch_size, s_h8, s_w8, self.gf_size * 4], # [32,6,6,256]
name="g_h1")
h1 = self.batch_normailizer(h1, train=train, name="g_bn1")
h1 = tf.nn.relu(h1)
# layer 2: 反卷积
h2, h2_w, h2_b = self.deconv2d(h1,
[self.batch_size, s_h4, s_w4, self.gf_size * 2], # [32,12,12,128]
name="g_h2")
h2 = self.batch_normailizer(h2, train=train, name="g_bn2")
h2 = tf.nn.relu(h2)
# layer 3: 反卷积
h3, h3_w, h3_b = self.deconv2d(h2,
[self.batch_size, s_h2, s_w2, self.gf_size * 1], # [32,24,24,64]
name="g_h3")
h3 = tf.nn.relu(h3)
# layer 4: 反卷积
h4, h4_w, h4_b = self.deconv2d(h3, self.batch_shape, name="g_h4") # [32,48,48]
return tf.nn.tanh(h4) # 激活函数计算并返回
def discriminator(self, real_imgs, reuse=False):
"""
判别器
:param real_imgs: 图像数据
:param reuse: 是否重用名字空间
:return:
"""
with tf.variable_scope("discriminator", reuse=reuse):
# layer 0: 卷积
h0 = self.conv2d(real_imgs, self.df_size, name="d_h0_conv")
h0 = self.lrelu(h0) # 激活
# layer 1
h1 = self.conv2d(h0, self.df_size * 2, name="d_h1_conv")
h1 = self.batch_normailizer(h1, name="d_bn1") # 批量归一化
h1 = self.lrelu(h1) # 激活
# layer 2
h2 = self.conv2d(h1, self.df_size * 4, name="d_h2_conv")
h2 = self.batch_normailizer(h2, name="d_bn2") # 批量归一化
h2 = self.lrelu(h2) # 激活
# layer 3
h3 = self.conv2d(h2, self.df_size * 8, name="d_h3_conv")
h3 = self.batch_normailizer(h3, name="d_bn3") # 批量归一化
h3 = self.lrelu(h3) # 激活
# layer 4
h4, _, _ = self.linear(tf.reshape(h3, [self.batch_size, -1]),
1,
name="d_h4_lin")
return tf.nn.sigmoid(h4), h4
@staticmethod
def loss_graph(real_logits, fake_logits):
# 生成器loss
# 生成器希望判别器判断出来标签为1
gen_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=fake_logits,
labels=tf.ones_like(fake_logits)))
# 判别器识别生成的图片loss
# 判别器希望识别出来的标签为0
fake_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=fake_logits,
labels=tf.zeros_like(fake_logits)))
# 判别器识别真实图片loss
# 判别器希望识别出来标签全为1
real_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=real_logits,
labels=tf.ones_like(real_logits)))
# 判别器总的loss
# 对真实图片和生成图片总体判别结果
dis_loss = tf.add(fake_loss, real_loss)
return gen_loss, fake_loss, real_loss, dis_loss
@staticmethod
def optimizer_graph(gen_loss, dis_loss, learning_rate, beta1):
"""
定义优化器
:param gen_loss: 生成器损失函数
:param dis_loss: 判别器损失函数
:param learning_rate: 学习率
:param beta1: 衰减率
:return:
"""
train_vars = tf.trainable_variables()
# 生成器变量
gen_vars = [var for var in train_vars if var.name.startswith("generator")]
# 判别器变量
dis_vars = [var for var in train_vars if var.name.startswith("discriminator")]
# 优化器
# beta1: 衰减率
# var_list: 优化的变量
gen_optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate,
beta1=beta1).minimize(gen_loss, var_list=gen_vars)
dis_optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate,
beta1=beta1).minimize(dis_loss, var_list=dis_vars)
return gen_optimizer, dis_optimizer
def train(self):
"""
训练
:return:
"""
# 真实图像
real_imgs = tf.placeholder(tf.float32, self.batch_shape, name="real_images")
# 白噪声图像
noise_imgs = tf.placeholder(tf.float32, [None, self.noise_img_size], name="noise_images")
# 生成图像
fake_imgs = self.generator(noise_imgs)
# 判别
## 对真实图像进行判别
real_outputs, real_logits = self.discriminator(real_imgs)
## 对生成器生成的图像进行判别
fake_outputs, fake_logits = self.discriminator(fake_imgs, reuse=True)
# 获取损失函数
gen_loss, fake_loss, real_loss, dis_loss = self.loss_graph(real_logits, fake_logits)
# 优化器
gen_optimizer, dis_optimizer = self.optimizer_graph(gen_loss, # 生成器损失函数
dis_loss, # 判别器损失函数
self.learning_rate, # 学习率
self.beta1) # 衰减率
# 开始训练
saver = tf.train.Saver()
step = 0
# 限定占用GPU比率
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
# 创建Session,执行训练
# 创建Session时通过config来设置参数
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)) as sess:
sess.run(tf.global_variables_initializer()) # 初始化
# 训练之前,加载增量模型
if os.path.exists("./model/checkpoint"):
print("saver restore:", os.getcwd())
# 获取最后一个检查点文件并加载
saver.restore(sess, tf.train.latest_checkpoint("./model/"))
for epoch in range(self.epoch_size):
batches = self.avatar.batches() # 取出一个批次数据
for batch_imgs in batches:
# 产生一个批次的均匀分布的白噪声数据
noises = np.random.uniform(-1, 1,
size=(self.batch_size, self.noise_img_size)).astype(np.float32)
_ = sess.run(dis_optimizer, feed_dict={real_imgs: batch_imgs, noise_imgs: noises})
_ = sess.run(gen_optimizer, feed_dict={noise_imgs: noises})
_ = sess.run(gen_optimizer, feed_dict={noise_imgs: noises})
step += 1
print(datetime.now().strftime("%c"), epoch, step)
# 每一轮训练结束计算loss
## 总判别器loss
loss_dis = sess.run(dis_loss, feed_dict={real_imgs: batch_imgs, noise_imgs: noises})
## 判别器对真实图片loss
loss_real = sess.run(real_loss, feed_dict={real_imgs: batch_imgs, noise_imgs: noises})
## 判别器对生成的图片loss
loss_fake = sess.run(fake_loss, feed_dict={real_imgs: batch_imgs, noise_imgs: noises})
## 生成器loss
loss_gen = sess.run(gen_loss, feed_dict={noise_imgs: noises})
print("")
print(datetime.now().strftime('%c'), ' epoch:', epoch, ' step:', step, ' loss_dis:', loss_dis,
' loss_real:', loss_real, ' loss_fake:', loss_fake, ' loss_gen:', loss_gen)
# 训练结束保存模型
model_path = "./model/" + "avatar.model"
saver.save(sess, model_path, global_step=step)
def gen(self):
"""
生成图像
:return:
"""
noise_imgs = tf.placeholder(tf.float32, [None, self.noise_img_size],
name="noise_imgs") # 白噪声
sample_imgs = self.generator(noise_imgs, train=False) # 生成
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver.restore(sess, tf.train.latest_checkpoint("./model/")) # 加载模型
# 生成白噪声
sample_noise = np.random.uniform(-1, 1,
size=(self.sample_size, self.noise_img_size))
# 执行生成图像操作
samples = sess.run(sample_imgs, feed_dict={noise_imgs: sample_noise})
# 爆存生成的图像
for num in range(len(samples)):
self.avatar.save_img(samples[num], "samples" + os.sep + str(num) + ".jpg")
6.3.3 avatar_train.py
from avatar_model import AvatarModel
if __name__ == '__main__':
avatar = AvatarModel()
avatar.train()
6.3.4 avatar_gen.py
from avatar_model import AvatarModel
if __name__ == '__main__':
avatar = AvatarModel()
avatar.gen()
print("图片生成完成.")
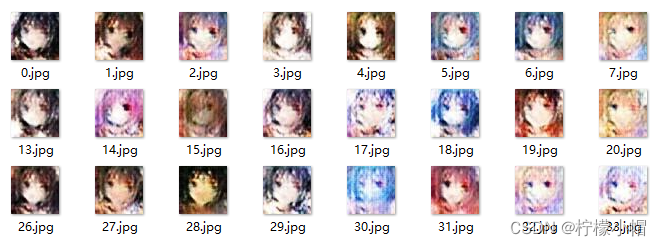
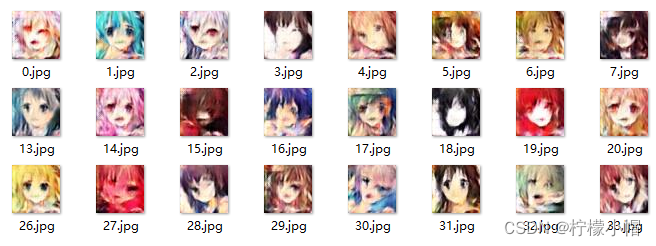
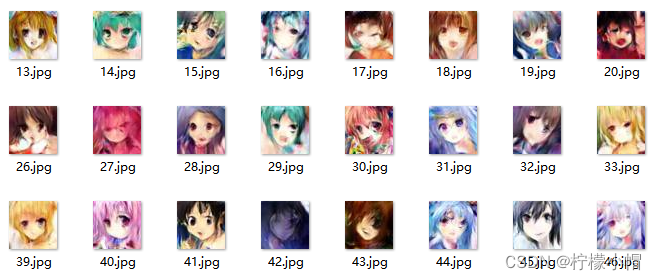
6.4 实验结果
为了加快训练速度,实际只采用了8903个样本进行训练,执行每20轮一次增量训练。实验结果如下:
- 1轮训练

- 5轮训练

- 10轮训练

- 20轮训练
- 40轮训练
- 60轮训练
7. 其它GAN模型
7.1 文本生成图像:GAWWN

7.2 匹配数据图像转换:Pix2Pix

7.3 非匹配数据图像转换:CycleGAN,用于实现两个领域图片互转

7.4 多领域图像转换:StarGAN

7.5 NAFNet:图像去噪和超分辨率提升模型

项目地址:https://aistudio.baidu.com/projectdetail/4918611?channelType=0&channel=0
7.6 AnimeGAN:数码照片动漫化

项目地址:https://aistudio.baidu.com/projectdetail/1308514?channelType=0&channel=0
8. 附录:参考资源
8.1 在线视频
李宏毅GAN教程:https://www.ixigua.com/pseries/6783110584444387843/?logTag=cZwYY0OhI8vRiNppza2UW
8.2 书籍
《生成对抗网络入门指南》,史丹青编著,机械工业出版社
















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











