







来自:manus.im
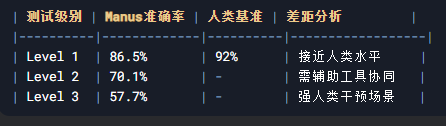
今天,Manus 的宣传全面启动,官网隆重公布了其在 GAIA 基准测试中的表现数据:Level 1 准确率高达 86.5%,Level 2 为 70.1%,Level 3 则达到 57.7%。其中,Level 1 的成绩尤其亮眼,已十分接近人类水平——研究显示,人类在 GAIA 测试中的整体准确率为 92%。这意味着,在基础任务上,Manus 已经可以和人类一较高下。
数据一览
那么,GAIA 究竟是什么?
它凭什么成为 AI 界的“高考”标准?让我们一探究竟。
全称 General AI Assistants Benchmark。是一个用于评估通用AI助手的基准测试,包含466个任务。有三个难度级别
Level 1(基础任务)
Level 2(中级任务)
Level 3(高级任务)
从简单指令执行到复杂推理和多模态处理,逐步提升对AI能力的要求。这种分级设计能够全面评估AI系统的性能,并为AI研究的进步提供指导。

(领取 智能体pdf ,可以加shadow微信litnmnm)
从人类参与的角度来看,shadow 总结如下:
Level 1(基础任务):AI 已接近人类常识水平,基本可以独立完成。
Level 2(中级任务):AI 能处理多步骤任务,但工具使用上仍需人类辅助。
Level 3(高级任务):AI 的表现更像是个“半吊子专家”,复杂推理和决策还离不开人类的深度干预。
这也给我们一个启示:日常工作中,不妨多思考哪些是“基础任务”,完全交给 AI 解放双手;而对于中高级任务,AI 更适合做你的“得力助手”而非“全能替身”。
Level 1: 基础任务 —— 幼儿园级AI考核
特点:
概念简单:任务通常是直接的指令或查询,不需要复杂的推理或多步骤操作。
单模态或简单多模态:主要依赖文本输入和输出,有时涉及简单的图像或表格。
工具使用有限:可能需要基本的工具,如搜索或计算器,但复杂度较低。
示例:
问:“法国的首都是什么?”
答:巴黎。任务:描述图片中的物体。
答:一只黑猫坐在窗台上。计算:2 + 2 = ?
答:4
/ 点评:这就像幼儿园考试,AI 只要记住“1+1=2”和“猫咪会喵喵叫”就能拿高分。Manus 在这块的表现(86.5%)已经非常接近人类(92%),可以说是个“优等生”了。
Level 2: 中级任务 —— 打工人段位测试
特点:
多步骤推理:任务需要一系列的思考或操作,可能包含多个子任务。
多模态处理:涉及文本、图像、音频或视频等多种模态,要求AI综合处理。
工具使用扩展:可能需要更复杂的工具,如网页浏览、数据库查询或API调用。
示例:
问:“如果今天是星期三,后天是星期几?”
答:星期五。
解析:这看似简单,但 AI 得理解“今天”“后天”的时间关系,还要推算日历逻辑——稍有不慎就“翻车”。任务:分析一份 PDF 报告(带图表)并回答“去年销售额增长了多少?”
答:根据图表,增长了 15%。任务:用网页搜索“明天北京天气如何?”
答:多云,气温 10-18°C。
/ 点评:Level 2 就像职场新人的“转正考试”。AI 得一边翻 PDF、一边查天气,还要逻辑清晰地回答问题。Manus 的 70.1% 准确率说明它已经能胜任“助理”角色,但偶尔还得靠人类“救场”。
Level 3: 高级任务 —— 灭霸级试炼场
特点:
复杂推理和规划:任务需要深入思考、规划和决策,可能涉及多个相互关联的子任务。
高级多模态处理:包含多种模态的复杂组合,如视频分析、音频转录和文本理解。
工具使用的复杂性:可能需要组合多个工具,或对工具输出进行进一步处理。
示例:
问:“解方程 2x + 3 = 7。”
答:x = 2。
解析:AI 得懂代数规则,逐步推导,而非瞎猜。任务:分析一段视频(比如会议记录),回答“谁提出了涨薪建议?”
答:张经理在第 5 分钟提到。任务:调用 API 获取股票数据,分析趋势并生成可视化报告。
答:过去一周股价上涨 8%,图表已生成。
/ 点评:这简直是 AI 的“终极Boss战”。想象一下,AI 先用 API 抓数据,再用图像处理工具解析财报图表,最后还得写篇逻辑清晰的分析——这哪是测试,分明是逼着 AI 秀“硅基求生欲”!Manus 的 57.7% 准确率虽不完美……
GAIA 的意义与启发
GAIA 不只是个“考试”,更是 AI 能力的分水岭。从数据看,Manus 在基础任务上已接近人类,但在中高级任务中仍有差距。这也提醒我们:
基础任务:大胆交给 AI,比如查资料、简单计算,效率翻倍。
中高级任务:AI 能帮忙,但别指望它“包打天下”,人类的创造力和判断力仍是关键。
shadow: 我特别关注 AI 在创造性和个性化定制上的价值。比如,生成一篇独特的文章或设计个性化日程,AI 能提供灵感,但最终的“点睛之笔”还得靠人类(目前)。

(领取 智能体pdf ,可以加shadow微信litnmnm)
DeepSeek:
看完 GAIA 的三重试炼,我只想说:这哪是 AI 测试?分明是数字版的“科举考试”!
Level 1:考金鱼级记忆力。
Level 2:测社畜抗压能力。
Level 3:直接让 AI 拍《盗梦空间》。
建议加个 Level 4:让 AI 解释“女朋友为什么生气”。保证所有算法当场蓝屏,人类直接宣布胜利!
Shadow 的观察
这一轮 AI 能力的提升,以 Thinking(思考) 和 DeepSearch(深度搜索) 为代表,标志着 Agent 型 AI 的崛起。它们能自主思考、搜集整理信息,已经开始挑战传统搜索引擎的地位。
未来,AI 可能不只是“工具”,而是真正的“合作伙伴”。
Manus 在 GAIA 上的表现令人振奋,但也揭示了 AI 的边界。
我们需要结合自己的需求,找到 AI 的最佳使用场景,才能真正释放它的价值。
所以,你准备好和 AI “组队”了吗?

最后,对 Agent 感兴趣可以加入我们社群


















 238
238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









