









ELECTRA
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
这篇论文中提出了一种新的自然语言表达的训练结构和预训练任务。整个训练结构为模仿gan的结构,由一个生成器和一个判别器组成,最后在下游任务使用时,通过对判别器进行fine-tuning得到。

下面具体介绍下整个模型:
生成器:
模型结构与vanilla bert基本一致,主要变动在以下几点:
-
[mask]时使用动态mask,在数据输入模型时才确定序列的掩码位置,而不是在数据预处理时确定。
-
输出时将[mask]预测的结果输出代替[mask]生成新的文本。
-
在layer_size上保持为生成器layer_size的1/2-1/4.在论文中经过实验发现将生成器的网络层尺寸维持在判别器的1/4时效果最好。

-
和判别器共享embedding层的权重。论文中经过比较,共享权重比不共享权重性能有所提高,但是当生成器层尺寸和判别器的层尺寸相同时会导致判别器难以学习,所以最终只共享embedding的权重。
-
损失只使用了MLM( masked language modeling),没有使用NSP(next sentence prediction)任务。下面为softmax层的结果。
p G ( x t ∣ x ) = e x p ( e ( x t ) T h G ( x ) t ) ∑ x ′ e x p ( e ( x ′ ) T h G ( x ) t ) p_G(x_t|\pmb{x}) = \frac{exp(e(x_t)^Th_G(\pmb{x})_t)}{\sum\limits_{x'}exp(e(x')^Th_G(\pmb{x})_t)} pG(xt∣x)=x′∑exp(e(x′)ThG(x)t)exp(e(xt)ThG(x)t)
判别器:
模型结构与vanilla bert基本一致,主要变动在以下几点:
- 输入没有[mask],输入是由生成器生成的文本。
- 输出使用序列标注,对每个字符预测是否为生成器生成的。**注意:**损失使用的是全部序列的损失来计算,而不是只使用[mask]的损失进行计算。
损失函数:
- 生成器损失:
L M L M ( x , θ G ) = E ( ∑ i ∈ m − log p G ( x i ∣ x m a s k e d ) ) L_{MLM}(\pmb{x}, θ_G) = \mathbb{E}(\sum_{i\in m}-\log p_G(x_i|\pmb{x}^{masked})) LMLM(x,θG)=E(i∈m∑−logpG(xi∣xmasked))
- 判别器损失:
L D i s c ( x , θ D ) = E ( ∑ t = 1 n I ( x t c o r r u p t = x t ) log D ( x c o r r u p t , t ) + I ( x t c o r r u p t ≠ x t ) log ( 1 − D ( x c o r r u p t , t ) ) ) L_{Disc}(\pmb{x}, θ_D) = \mathbb{E}(\sum_{t=1}^n\mathbb{I}(x_t^{corrupt}=x_t)\log D(\pmb{x}^{corrupt},t)+\mathbb{I}(x_t^{corrupt}\neq x_t)\log (1-D(\pmb{x}^{corrupt},t))) LDisc(x,θD)=E(t=1∑nI(xtcorrupt=xt)logD(xcorrupt,t)+I(xtcorrupt=xt)log(1−D(xcorrupt,t)))
- 整体损失
L = ∑ x ∈ X L M L M ( x , θ G ) + λ L D i s c ( x , θ D ) L=\sum_{\pmb{x} \in \pmb{X}}L_{MLM}(\pmb{x}, θ_G)+\lambda L_{Disc}(\pmb{x}, θ_D) L=x∈X∑LMLM(x,θG)+λLDisc(x,θD)
其它:
实际上除了 MLM loss,作者也尝试了另外两种训练策略:
- Adversarial Contrastive Estimation:ELECTRA 因为上述一些问题无法使用 GAN,但也可以以一种对抗学习的思想来训练。作者将生成器的目标函数由最小化 MLM loss 换成了最大化判别器在被替换 token 上的 RTD loss。但还有一个问题,就是新的生成器 loss 无法用梯度下降更新生成器,于是作者用强化学习 Policy Gradient 的思想,将被替换 token 的交叉熵作为生成器的 reward,然后进行梯度下降。强化方法优化下来生成器在 MLM 任务上可以达到 54% 的准确率,而之前 MLE 优化下可以达到 65%。
- Two-stage training:即先训练生成器,然后 freeze 掉,用生成器的权重初始化判别器,再接着训练相同步数的判别器。
对比三种训练策略,得到下图:
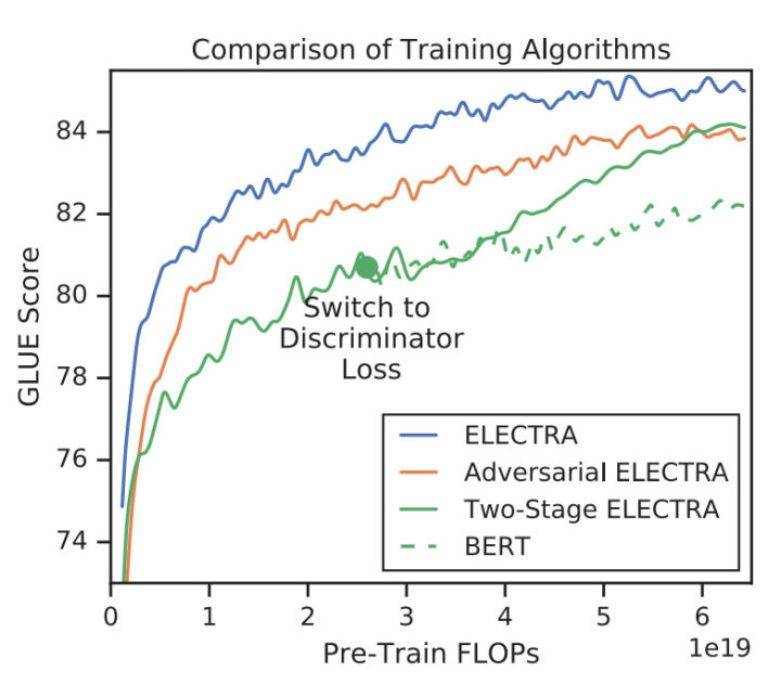
可见「隔离式」的训练策略效果还是最好的,而两段式的训练虽然弱一些,作者猜测是生成器太强了导致判别任务难度增大,但最终效果也比 BERT 本身要强,进一步证明了判别式预训练的效果。














 2234
2234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









