






1.训练了两个自回归模型Transformer-XL, XLNet)和四个自编码器模型(BERT, Albert, Electra, T5),
2.数据来源UniRef50,UniRef100和BFD,包含3930亿个氨基酸
UniRef:集成了三大蛋白质数据库,并经过高质量处理的大型权威数据库,包含多个子库
详细介绍一文极速读懂 Uniprot 蛋白质数据库 - 知乎 (zhihu.com)
BFD:AlphaFold2所用序列库大超凡(BFD)
大超凡就是由文章的第25作者 Martin Steinegger(M.S.)构建的序列数据库。

3.蛋白质LMs (pLMs)在Summit超级计算机上使用5616 gpu和高达1024核的TPU Pod进行训练。
Summit(顶点)超级计算机是IBM计划研发的一款超级计算机,其计算性能超过中国TaihuLight超级计算机。
Gpu:图形处理单元
Tpu张量处理单元
4.随机种子的设置
通过设置不同的随机种子可以给模型的不同的初始参数
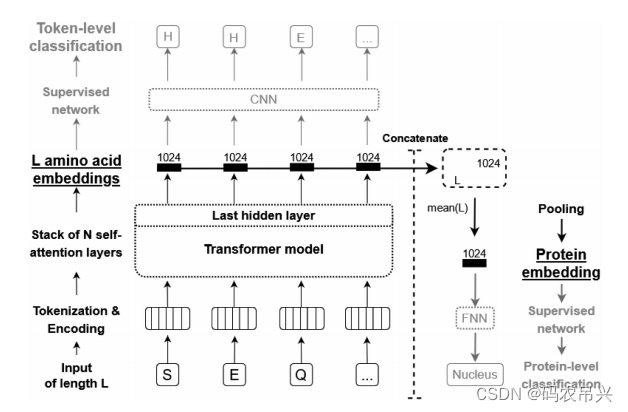
- 预训练模型概述
(模型简介)
BERT: BERT是第一个双向模型,用于重构被破坏的token(词元)。它被认为是NLP中迁移学习的事实标准。BERT通过预测输入中被掩盖的部分来训练模型,从而学习语境中的深层次语义。
Albert:Albert是对BERT的简化,通过在其注意力层之间进行硬参数共享来减少模型复杂度,这允许增加更多的注意力头(本文中选择了64个)。这种设计减少了模型的大小和训练成本,同时保持了性能。
Electra:Electra通过训练两个网络(生成器和鉴别器)来提高预训练任务的采样效率。生成器(基于BERT)负责重构被掩盖的token,可能创造出合理的替代选项;而鉴别器(Electra)则检测哪些token是被掩盖的。这种方法让所有token都能计算损失,而不仅仅是被破坏的token(通常只有15%),从而丰富了训练信号。
T5:T5使用了最初为序列翻译提出的原始变压器架构,包括一个编码器和一个解码器。编码器将源语言投射到一个嵌入空间,解码器则基于编码器的嵌入生成目标语言的翻译。T5显示了这种设计的简化可能需要付出一定的代价,但它在多个NLP基准测试中达到了最先进的结果。此外,它还提供了应用不同训练方法和掩码策略的灵活性,例如,T5允许重构token的跨度而不仅仅是单个token。
Transformer-XL和XLNet: 这些模型使用了T5的解码器或编码器的一部分,以实现更专注的功能。Transformer-XL和XLNet都旨在处理更长的序列数据,以提高模型在处理长文本时的性能和效率。
7.Global batch size和local batch size的区别:
在分布式训练中,`local batch size` 和 `global batch size` 是两个常用的术语,它们定义了训练过程中用于梯度计算的数据批量大小:
1. **Local Batch Size**:
- 这指的是分配给单个训练单元(比如一个GPU或者CPU)的数据批量大小。
- 在模型并行化训练中,每个计算单元只处理其分配的数据子集。
- Local batch size影响着单个训练单元的内存使用和计算需求。
2. **Global Batch Size**:
- 这是所有训练单元处理的数据总和,等于所有单个计算单元的local batch sizes之和。
- 在数据并行化训练中,每个计算单元处理不同的数据批量,但是它们都是从相同的数据集中分配得到的,这些数据批量的大小是local batch size。所有计算单元完成一次迭代后得到的参数更新会被合并,这一合并过程会参考所有local batch的数据,因此得到的是global batch size对应的更新。
- Global batch size直接影响模型训练的稳定性和最终的性能,较大的global batch size可以提高训练的效率,但也可能需要更精细的学习率调整策略来保持训练稳定。
简单来说,local batch size关注单个计算单元上的数据处理,而global batch size是指整个分布式系统中用于一次参数更新的总数据量。调整这两个参数可以影响训练速度、内存使用和模型性能。
8.位置编码
相对位置编码和绝对位置编码
由于绝对位置编码只关注单个位置信息,因此它的实现通常在输入层,可以通过简单的向量相加融入模型;而相对位置一定是pair对的信息,因此它无法直接在输入层实现,通常是通过改变Attention_score的计算方式来实现。
因此绝对位置编码无法处理长序列,因为他在输入的时候就要嵌入,已经固定好长度了
绝对位置编码:绝对位置编码是在序列中每个位置上都固定地分配一个唯一的编码。这种编码通常是基于正弦和余弦函数的周期性函数生成的。
相对位置编码:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









