







1 Embeddings from Language Model (ELMO)
1.1 Contextualized Word Embedding
在之前的word embedding中,同一个单词(同样type的内容),会被表示成相同的embedding。
但是一个单词会有很多的意思(token),比如下图中的”bank“,就有不同的含义
所以我们需要给不同的token,以不同的embedding


1.2 ELMO
基于RNN的language model
给这个RNN-based model 很多个句子,让他学。
中间的这个蓝色的hidden layer,就是考虑了前文的 embedding

当然可以不止学习前向顺序,还可以学习反向顺序,将二者的embedding拼起来

这种基于RNN的模型也可以叠很多层,那么就会有很多的中间hidden state,那么,如何选择/如何合理利用这些hidden state呢

ELMO的做法是,学一组加权系数,将这些hidden 都考虑进来
右下方是一个例子,Token表示没有经过一层RNN,也就是原始的embedding,LSTM 1表示经过了一层RNN,LSTM2表示经过了2层RNN。加权的系数α1和α2是根据下游任务学出来的

2 Bidirectional Encoder Representations from Transformers (BERT)
2.0 简单的理解
简单但不严谨的理解,可以把Bert看成是Transformer的encoder部分

我喂入Bert一句句子,输出的是句子中每个单词的embedding

2.0.1 BERT的输入 
2.0.2 BERT的特点
- Pre-train:这是个预训练的语言模型
- Deep
- Bidirectional Transformer:Transformer的encoder部分
- Language Understanding:Contextualized Word Embedding
2.1 Bert的训练
2.1.1 Masked LM
把输入句子中一定比例(论文中是15%)的词汇替换为MASK(也就是被遮住),让BERT猜测被盖住的地方是一个什么词汇【注:原论文中,这些被选中的单词80%的概率被替换成MASK,10%的概率替换成随机别的单词,10%的概率不变】
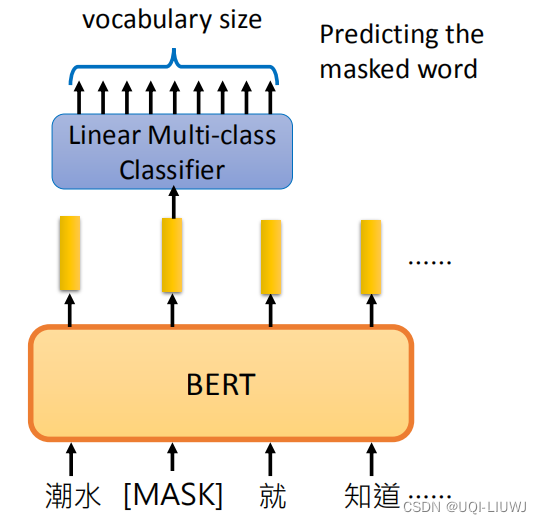
每一个词经过BERT得到一个相应的embedding。把被遮住部分的embedding未入一个线性分类器,预测被MASK掉的词是哪个词。
由于线性的分类器能力非常有限,所以需要BERT学出非常好的embedding(分类预测的词和实际遮住的词是一样/相近的)

2.1.2 Next Sentence Prediction
给两个句子,判断这两个句子是接在一起的还是不接在一起的
CLS表示特殊的token,代表要做分类
【注:原始论文中,50%的是相邻的两句话,50%的不是相邻的两句话】
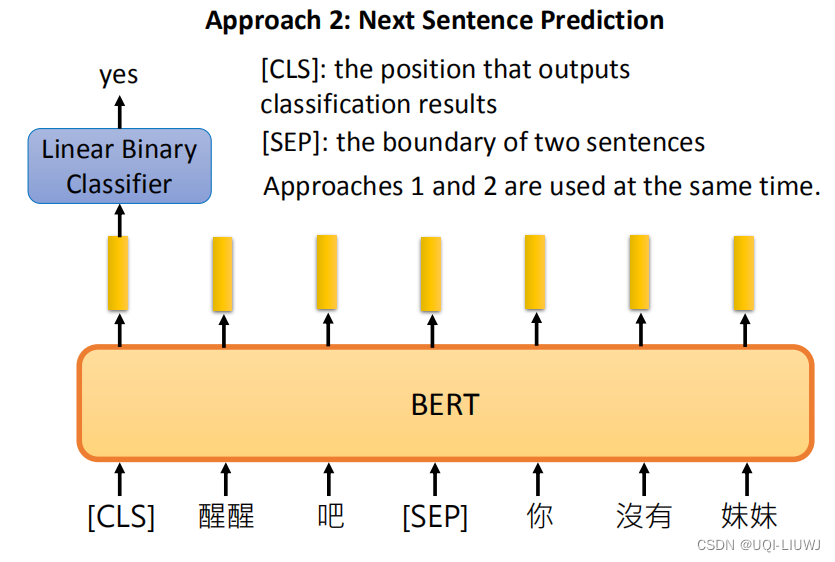
为什么CLS在开头呢?
如果是正向RNN,那CLS确实应该放在末尾,这样才能看到整个句子的内容
但是BERT的内部是transformer的encoder,也就是self-attention。不考虑positional encoding的话, CLS无论放在开头还是结尾,差别都不会很大。
2.2 BERT应用
BERT+downstream task BERT参数微调,downstream从零开始训练
——》由于大部分参数BERT都学过了,所以实际上要学的参数非常少
2.2.1 句子分类

这边的CLS代表分类的符号
这里的BERT的初始化权重为预训练BERT模型的权重,而全连接层的权重随机初始化
2.2.2 每个单词属于那个类

2.2.3 根据前提,是否能得到某个假设
- 利用语言模型来判断句子间的关系,这种关系是以类别形式呈现
- 给定两个句子,一个句子是前提(premise),一个句子是假设(hypothesis)
- 将这两个句子同时输入到模型中,判断这两个句子的关系,是矛盾、蕴涵还是中性的

2.2.4 Extraction-based Question Answering (QA)
- 给定一个文档(稍微长一些的文字序列),给定一个问题(稍微短一些的文字序列),然后在文档中找到能够回应这个问题的答案。
- 需要注意的是,这个答案是可以直接在文档中找到的
给出文本回答问题(问题的答案一定在文本中出现过)

输入文本和问题,输出两个整数s,e,表示答案就在qs到qe之间

那么怎么实现呢?除了BERT之外,我们还需要学习两个向量(一红一蓝)
红色的向量和BERT输出的embedding 分别做内积,然后进行softmax,选择结果最大的,作为s
蓝色的向量做的事情和红色的向量做的是一致的,不过蓝色向量学习的是e


这里会存在一个问题,如果学出来的s在e后面咋办?那么说明这个问题无解
2.3 BERT的改进
2.3.1 BART——降噪自编码器的引入
- MLM 将原文中的词用[MASK]标记随机替换,这本身是对文本进行了破坏,相当于在文本中添加了噪声,然后通过训练语言模型来还原文本,消除噪声。
BART引入了降噪自编码器,丰富了文本的破坏方式- 例如随机掩盖(同 MLM 一致)某些词、随机删掉某些词或片段、打乱文档顺序等
- 将文本输入到编码器中后,利用一个解码器生成破坏之前的原始文档,通过这种方式进行预训练

2.3.2 ELECTRA——替代词检测
- MLM 对文本中的[MASK]标记的词进行预测,以试图恢复原始文本。
- 其预测结果可能完全正确,也可能预测出一个不属于原文本中的词。
ELECTRA引入了替代词检测,来预测一个由语言模型生成的句子中哪些词是原本句子中的词,哪些词是语言模型生成的且不属于原句子中的词。- 使用一个小型的 MLM 模型作为生成器(Generator),来对包含[MASK]的句子进行预测
- 另外训练一个基于二分类的判别器(Discriminator)来对生成器生成的句子进行判断

2.3.3 DistilBERT——与虚拟连接段蒸馏
DistilBERT在预训练阶段蒸馏,其学生模型具有与BERT相似的结构,但层数减半
3 GPT
可以在一定程度上看成是Transformer的 Decoder
在完全没有训练资料的情况下硬做
给定一些词汇,预测接下来的词汇。
和已经看到过的词汇做attention


3.1 GPT应用
3.1.1 Reading Comprehension
将如下内容送入GPT中,获得输出

3.1.2 summarization

3.1.3 Translation
















 1029
1029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











