






正则作为处理字符串的一个实用工具,在Python中经常会用到,比如爬虫爬取数据时常用正则来检索字符串等等。正则表达式已经内嵌在Python中,通过导入re模块就可以使用,作为刚学Python的新手大多数都听说”正则“这个术语。
今天来给大家分享一份关于比较详细的Python正则表达式宝典,学会之后你将对正则表达式达到精通的状态。

文章目录
一、re模块
在讲正则表达式之前,我们首先得知道哪里用得到正则表达式。正则表达式是用在findall()方法当中,大多数的字符串检索都可以通过findall()来完成。
1.导入re模块
在使用正则表达式之前,需要导入re模块。
import re
- 1
2.findall()的语法:
导入了re模块之后就可以使用findall()方法了,那么我们必须要清楚findall()的语法是怎么规定的。
findall(正则表达式,目标字符串)
- 1
不难看出findall()的是由正则表达式和目标字符串组成,目标字符串就是你要检索的东西,那么如何检索则是通过正则表达式来进行操作,也就是我们今天的重点。
使用findall()之后返回的结果是一个列表,列表中是符合正则要求的字符串
二、正则表达式
(一)字符串的匹配
1.普通字符
大多数的字母和字符都可以进行自身匹配。
import re
a = "abc123+-*"
b = re.findall('abc',a)
print(b)
- 1
- 2
- 3
- 4
输出结果:
['abc']
- 1
2.元字符
元字符指的是. ^ $ ? + {} \ []之类的特殊字符,通过它们我们可以对目标字符串进行个性化检索,返回我们要的结果。
这里我给大家介绍10个常用的元字符以及它们的用法,这里我先给大家做1个简单的汇总,便于记忆,下面会挨个讲解每一个元字符的使用。
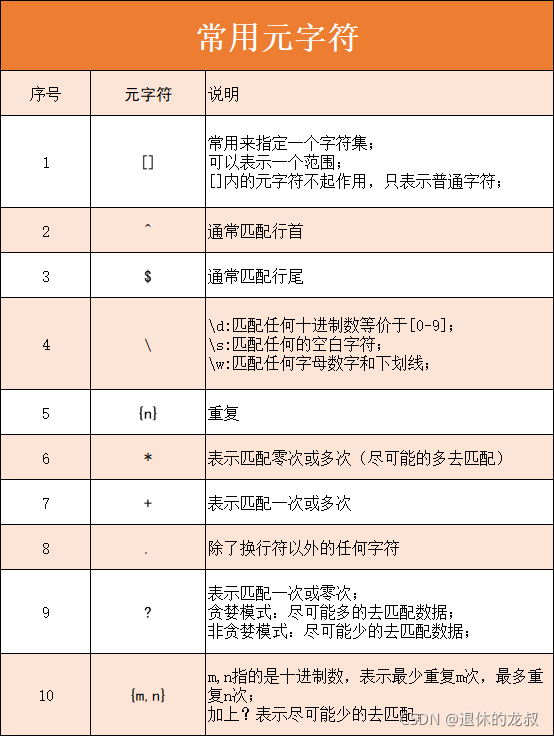
(1) []
[] 的使用方式主要有以下三种:
- 常用来指定一个字符集。
s = "a123456b"
rule = "a[0-9][1-6][1-6][1-6][1-6][1-6]b" #这里暂时先用这种麻烦点的方法,后面有更容易的,不用敲这么多[1-6]
l = re.findall(rule,s)
print(l)
- 1
- 2
- 3
- 4
输出结果为:
['a123456b']
- 1
- 可以表示一个范围。
例如要在字符串"abcabcaccaac"中选出abc元素:
s = "abcabcaccaac"
rule = "a[a,b,c]c" # rule = "a[a-z0-9][a-z0-9][a-z0-9][a-z0-9]c"
l = re.findall(rule, s)
print(l)
- 1
- 2
- 3
- 4
输出结果为:
['abc', 'abc', 'acc', 'aac']
- 1
- [] 内的元字符不起作用,只表示普通字符。
例如要在字符串“caabcabcaabc”中选出“caa”:
print(re.findall("caa[a,^]", "caa^bcabcaabc"))
- 1
输出结果为:
['caa^']
- 1
注意点:当在[]的第一个位置时,表示除了a以外的都进行匹配,例如把[]中的和a换一下位置:
print(re.findall("caa[^,a]", "caa^bcabcaabc"))
- 1
输出:
['caa^', 'caab']
- 1
(2)^
^ 通常用来匹配行首,例如:
print(re.findall("^abca", "abcabcabc"))
- 1
输出结果:
['abca']
- 1
(3) $
$ 通常用来匹配行尾,例如:
print(re.findall("abc$", "accabcabc"))
- 1
输出结果:
['abc']
- 1
(4)\
反斜杠后面可以加不同的字符表示不同的特殊含义,常见的有以下3种。
- \d:匹配任何十进制数等价于[0-9]
print(re.findall("c\d\d\da", "abc123abc"))
- 1
输出结果为:
['c123a']
- 1
\可以转义成普通字符,例如:
print(re.findall("\^abc", "^abc^abc"))
- 1
输出结果:
['^abc', '^abc']
- 1
- s
匹配任何的空白字符例如:
print(re.findall("\s\s", "a c"))
- 1
输出结果:
[' ', ' ']
- 1
- \w
匹配任何字母数字和下划线,等价于[a-zA-Z0-9_],例如:
print(re.findall("\w\w\w", "abc12_"))
- 1
输出:
['abc', '12_']
- 1
(5){n}
{n}可以避免重复写,比如前面我们用\w时写了3次\w,而这里我们这需要用用上{n}就可以,n表示匹配的次数,例如:
print(re.findall("\w{2}", "abc12_"))
- 1
输出结果:
['ab', 'c1', '2_']
- 1
(6)*
*表示匹配零次或多次(尽可能的多去匹配),例如:
print(re.findall("010-\d*", "010-123456789"))
- 1
输出:
['010-123456789']
- 1
**(7) + **
+表示匹配一次或多次,例如
print(re.findall("010-\d+", "010-123456789"))
- 1
输出:
['010-123456789']
- 1
(8) .
.是个点,这里不是很明显,它用来操作除了换行符以外的任何字符,例如:
print(re.findall(".", "010\n?!"))
- 1
输出:
['0', '1', '0', '?', '!']
- 1
(9) ?
?表示匹配一次或零次
print(re.findall("010-\d?", "010-123456789"))
- 1
输出:
['010-1']
- 1
这里要注意一下贪婪模式和非贪婪模式。
贪婪模式:尽可能多的去匹配数据,表现为\d后面加某个元字符,例如\d*:
print(re.findall("010-\d*", "010-123456789"))
- 1
输出:
['010-123456789']
- 1
非贪婪模式:尽可能少的去匹配数据,表现为\d后面加?,例如\d?
print(re.findall("010-\d*?", "010-123456789"))
- 1
输出为:
['010-']
- 1
(10){m,n}
m,n指的是十进制数,表示最少重复m次,最多重复n次,例如:
print(re.findall("010-\d{3,5}", "010-123456789"))
- 1
输出:
['010-12345']
- 1
加上?表示尽可能少的去匹配
print(re.findall("010-\d{3,5}?", "010-123456789"))
- 1
输出:
['010-123']
- 1
{m,n}还有其他的一些灵活的写法,比如:
- {1,} 相当于前面提过的 + 的效果
- {0,1} 相当于前面提过的 ? 的效果
- {0,} 相当于前面提过的 * 的效果
关于常用的元字符以及使用方法就先到这里,我们再来看看正则的其他知识。
(二)正则的使用
1.编译正则
在Python中,re模块可通过compile() 方法来编译正则,re.compile(正则表达式),例如:
s = "010-123456789"
rule = "010-\d*"
rule_compile = re.compile(rule) #返回一个对象
# print(rule_compile)
s_compile = rule_compile.findall(s)
print(s_compile) #打印compile()返回的对象是什么
- 1
- 2
- 3
- 4
- 5
- 6
输出结果:
['010-123456789']
- 1
2.正则对象的使用方法
正则对象的使用方法不仅仅是通过我们前面所介绍的 findall() 来使用,还可以通过其他的方法进行使用,效果是不一样的,这里我做个简单的总结:
(1)findall()
找到re匹配的所有字符串,返回一个列表
(2)search()
扫描字符串,找到这个re匹配的位置(仅仅是第一个查到的)
(3)match()
决定re是否在字符串刚开始的位置(匹配行首)
就拿上面的 compile()编译正则之后返回的对象来做举例,我们这里不用 findall() ,用 match() 来看一下结果如何:
s = "010-123456789"
rule = "010-\d*"
rule_compile = re.compile(rule) # 返回一个对象
# print(rule_compile)
s_compile = rule_compile.match(s)
print(s_compile) # 打印compile()返回的对象是什么
- 1
- 2
- 3
- 4
- 5
- 6
输出:
<re.Match object; span=(0, 13), match='010-123456789'>
- 1
可以看出结果是1个match 对象,开始下标位置为0~13,match为 010-123456789 。既然返回的是对象,那么接下来我们来讲讲这个match 对象的一些操作方法。
3.Match object 的操作方法
这里先介绍一下方法,后面我再举例,Match对象常见的使用方法有以下几个:
(1)group()
返回re匹配的字符串
(2)start()
返回匹配开始的位置
(3)end()
返回匹配结束的位置
(4)span()
返回一个元组:(开始,结束)的位置
举例:用span()来对search()返回的对象进行操作:
s = "010-123456789"
rule = "010-\d*"
rule_compile = re.compile(rule) # 返回一个对象
s_compile = rule_compile.match(s)
print(s_compile.span()) #用span()处理返回的对象
- 1
- 2
- 3
- 4
- 5
结果为:
(0, 13)
- 1
4.re模块的函数
re模块中除了上面介绍的findall()函数之外,还有其他的函数,来做一个介绍:
(1)findall()
根据正则表达式返回匹配到的所有字符串,这个我就不多说了,前面都是在介绍它。
(2)sub(正则,新字符串,原字符串)
sub() 函数的功能是替换字符串,例如:
s = "abcabcacc" #原字符串
l = re.sub("abc","ddd",s) #通过sub()处理过的字符串
print(l)
- 1
- 2
- 3
输出:
ddddddacc #把abc全部替换成ddd
- 1
(3)subn(正则,新字符串,原字符串)
subn()的作用是替换字符串,并返回替换的次数
s = "abcabcacc" #原字符串
l = re.subn("abc","ddd",s) #通过sub()处理过的字符串
print(l)
- 1
- 2
- 3
输出:
('ddddddacc', 2)
- 1
(4)split()
split()分割字符串,例如:
s = "abcabcacc"
l = re.split("b",s)
print(l)
- 1
- 2
- 3
输出结果:
['a', 'ca', 'cacc']
- 1
三、结语
关于正则,我就讲这么多了,正则几乎是Python所有方向中是必不可少的一个基础,祝你的Python之旅学有所成!
**感谢小伙伴的关注,我这里整理很多之前网安自学的干货视频,找资源不易,帮忙给个三连呗!**
# 如果你也想学习:黑客&网络安全的SQL攻防今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
在这里领取:

这个是我花了几天几夜自整理的最新最全网安学习资料包免费共享给你们,其中包含以下东西:
1.学习路线&职业规划


2.全套体系课&入门到精通

3.黑客电子书&面试资料

4.漏洞挖掘工具和学习文档
















 6438
6438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











