







 超级会员免费看
超级会员免费看
稀疏表示综述:A Survey of Sparse Representation: Algorithms and Applications_2015(2)
本文地址:http://blog.csdn.net/shanglianlm/article/details/46866803
VI. 基于邻近算法的优化策略(PROXIMITY ALGORITHM BASED OPTIMIZATION STRATEGY)
proximity algorithm 的核心是 使用邻近算子(proximal operator)去迭代地求解子问题(sub-problem)。
proximity algorithm 被广泛地应用于求解非光滑(nonsmooth),约束凸优化问题(constrained convex optimization problems) [29]。
假设一个简单的约束优化问题
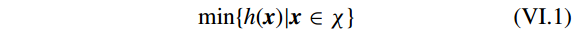
其中

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 6182
6182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











