







本系列博客主要是在学习《模式识别(张学工著 第三版)》时的一些笔记。
本文地址:http://blog.csdn.net/shanglianlm/article/details/49734441
1 引言
1-1 分类
- 基于样本的概率分布模型进行聚类
- 直接根据样本间的距离或相似性度量进行聚类
2 基于模型的方法
如果已经知道或者可以估计样本在特征空间的概率分布,就可以用基于模型的方法进行聚类分析。模型就是样本在其所在空间里的概率密度函数。
2-1 单峰子集分离

2-2 高维特征的单峰子集分离

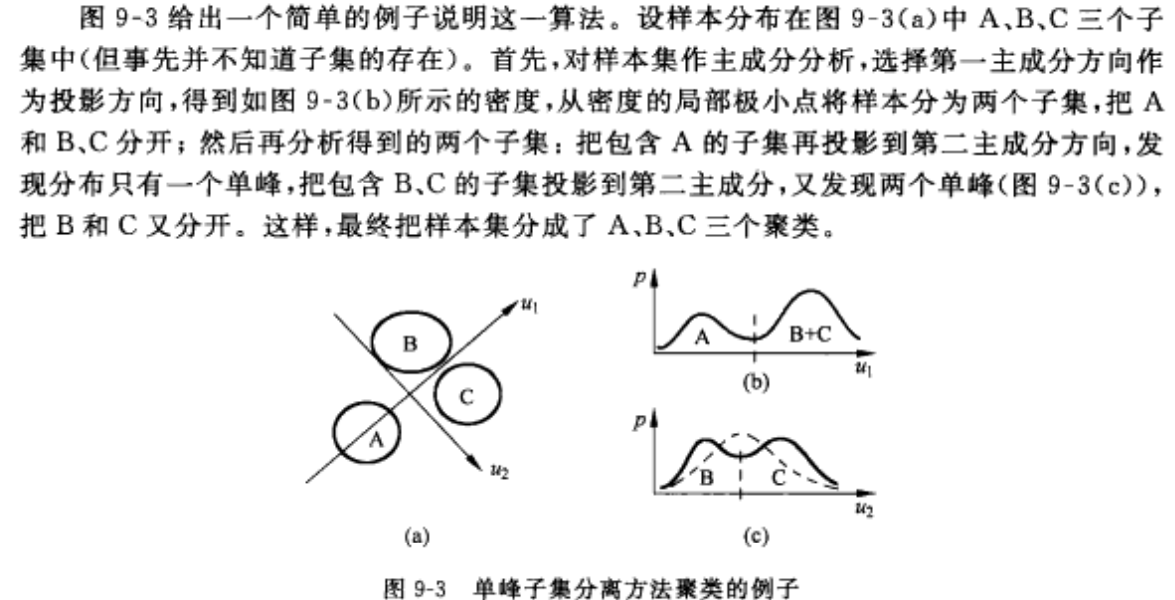
2-3 实例
3 混合模型的估计
非监督最大似然估计
- 假设条件

- 似然函数

- 可识别性问题

- 计算问题



4 动态聚类方法
特点
1. 选定某种距离度量作为样本间的相似性度量;
2. 确定某个评价聚类结果质量的准则函数;
3. 选定某个初始分类,然后用迭代算法 使准则函数取极值的最好聚类结果。
4-1 C均值聚类

4-2 ISODATA方法


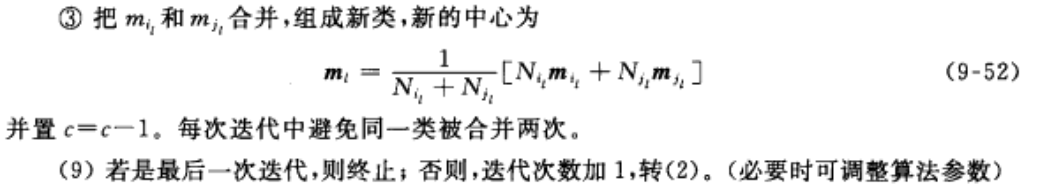
4-3 基于样本与核的相似性度量的动态聚类方法
5 模糊聚类方法
模糊集
模糊C均值聚类
改进的模糊C均值聚类
















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











