









Searching for MobileNetV3
https://arxiv.org/abs/1905.02244
[Pytorch] https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
MobileNet V3 = MobileNet v2 + SE结构 + hard-swish activation +网络结构头尾微调。除了激活函数,看不出有什么亮点。
2 网络架构搜索
关于网络架构搜索(NAS)
2-1 模块级的搜索(Block-wise Search)
资源受限的NAS(platform-aware NAS)在资源受限条件下搜索网络的各个模块。

MnasNet: Platform-Aware Neural Architecture Search for Mobile
2-2 层级的搜索(Layer-wise Search)
NetAdapt对各个模块确定之后的网络层进行微调。

Netadapt: Platform-aware neural network adaptation for mobile applications
3 网络设计
3-1 网络结构优化
a. 网络端部加速
砍掉最后的一些层来提速,即先使用global average pooling降低计算代价。
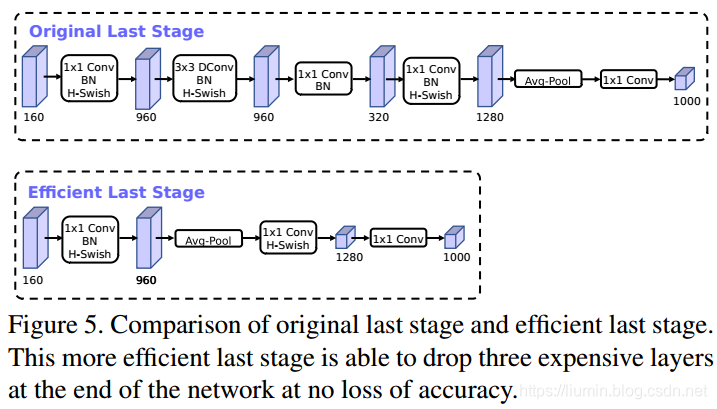
b. 网络头部加速
通道数减半;
使用h-swish代替ReLU 或者 swish;
3-2 激活函数(h-swish)
swish x【1】 能有效改进网络精度,但是比较耗时,
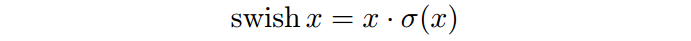
因此提出swish x 的近似版h-swish
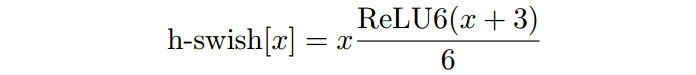
h-swish 实现比 swish 快,但是比 relu 还是要慢不少。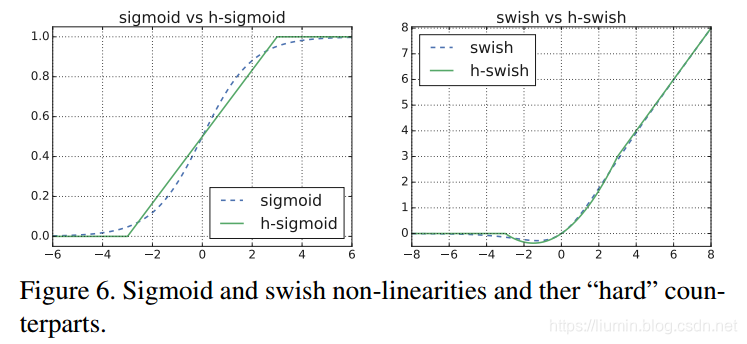
【1】 Searching for activation functions
3-3 MobileNetV3 网络结构

4 实验结果
4-1 图像分类(Classification)

4-2 目标检测(Detection)

4-3 语义分割(Semantic Segmentation)
Lite R-ASPP结构:

PyTorch代码:
import torch
import torch.nn as nn
import torchvision
class HardSwish(nn.Module):
def __init__(self, inplace=True):
super(HardSwish, self).__init__()
self.relu6 = nn.ReLU6(inplace)
def forward(self, x):
return x*self.relu6(x+3)/6
def ConvBNActivation(in_channels,out_channels,kernel_size,stride,activate):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, groups=in_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True) if activate == 'relu' else HardSwish()
)
def Conv1x1BNActivation(in_channels,out_channels,activate):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True) if activate == 'relu' else HardSwish()
)
def Conv1x1BN(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels)
)
class SqueezeAndExcite(nn.Module):
def __init__(self, in_channels, out_channels,se_kernel_size, divide=4):
super(SqueezeAndExcite, self).__init__()
mid_channels = in_channels // divide
self.pool = nn.AvgPool2d(kernel_size=se_kernel_size,stride=1)
self.SEblock = nn.Sequential(
nn.Linear(in_features=in_channels, out_features=mid_channels),
nn.ReLU6(inplace=True),
nn.Linear(in_features=mid_channels, out_features=out_channels),
HardSwish(inplace=True),
)
def forward(self, x):
b, c, h, w = x.size()
out = self.pool(x)
out = out.view(b, -1)
out = self.SEblock(out)
out = out.view(b, c, 1, 1)
return out * x
class SEInvertedBottleneck(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels, kernel_size, stride,activate, use_se, se_kernel_size=1):
super(SEInvertedBottleneck, self).__init__()
self.stride = stride
self.use_se = use_se
# mid_channels = (in_channels * expansion_factor)
self.conv = Conv1x1BNActivation(in_channels, mid_channels,activate)
self.depth_conv = ConvBNActivation(mid_channels, mid_channels, kernel_size,stride,activate)
if self.use_se:
self.SEblock = SqueezeAndExcite(mid_channels, mid_channels, se_kernel_size)
self.point_conv = Conv1x1BNActivation(mid_channels, out_channels,activate)
if self.stride == 1:
self.shortcut = Conv1x1BN(in_channels, out_channels)
def forward(self, x):
out = self.depth_conv(self.conv(x))
if self.use_se:
out = self.SEblock(out)
out = self.point_conv(out)
out = (out + self.shortcut(x)) if self.stride == 1 else out
return out
class MobileNetV3(nn.Module):
def __init__(self, num_classes=1000,type='large'):
super(MobileNetV3, self).__init__()
self.type = type
self.first_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(16),
HardSwish(inplace=True),
)
if type=='large':
self.large_bottleneck = nn.Sequential(
SEInvertedBottleneck(in_channels=16, mid_channels=16, out_channels=16, kernel_size=3, stride=1,activate='relu', use_se=False),
SEInvertedBottleneck(in_channels=16, mid_channels=64, out_channels=24, kernel_size=3, stride=2, activate='relu', use_se=False),
SEInvertedBottleneck(in_channels=24, mid_channels=72, out_channels=24, kernel_size=3, stride=1, activate='relu', use_se=False),
SEInvertedBottleneck(in_channels=24, mid_channels=72, out_channels=40, kernel_size=5, stride=2,activate='relu', use_se=True, se_kernel_size=28),
SEInvertedBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1,activate='relu', use_se=True, se_kernel_size=28),
SEInvertedBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1,activate='relu', use_se=True, se_kernel_size=28),
SEInvertedBottleneck(in_channels=40, mid_channels=240, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),
SEInvertedBottleneck(in_channels=80, mid_channels=200, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),
SEInvertedBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=2,activate='hswish', use_se=False),
SEInvertedBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),
SEInvertedBottleneck(in_channels=80, mid_channels=480, out_channels=112, kernel_size=3, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
SEInvertedBottleneck(in_channels=112, mid_channels=672, out_channels=112, kernel_size=3, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
SEInvertedBottleneck(in_channels=112, mid_channels=672, out_channels=160, kernel_size=5, stride=2,activate='hswish', use_se=True,se_kernel_size=7),
SEInvertedBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1,activate='hswish', use_se=True,se_kernel_size=7),
SEInvertedBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1,activate='hswish', use_se=True,se_kernel_size=7),
)
self.large_last_stage = nn.Sequential(
nn.Conv2d(in_channels=160, out_channels=960, kernel_size=1, stride=1),
nn.BatchNorm2d(960),
HardSwish(inplace=True),
nn.AvgPool2d(kernel_size=7, stride=1),
nn.Conv2d(in_channels=960, out_channels=1280, kernel_size=1, stride=1),
HardSwish(inplace=True),
)
else:
self.small_bottleneck = nn.Sequential(
SEInvertedBottleneck(in_channels=16, mid_channels=16, out_channels=16, kernel_size=3, stride=2,activate='relu', use_se=True, se_kernel_size=56),
SEInvertedBottleneck(in_channels=16, mid_channels=72, out_channels=24, kernel_size=3, stride=2,activate='relu', use_se=False),
SEInvertedBottleneck(in_channels=24, mid_channels=88, out_channels=24, kernel_size=3, stride=1,activate='relu', use_se=False),
SEInvertedBottleneck(in_channels=24, mid_channels=96, out_channels=40, kernel_size=5, stride=2,activate='hswish', use_se=True, se_kernel_size=14),
SEInvertedBottleneck(in_channels=40, mid_channels=240, out_channels=40, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
SEInvertedBottleneck(in_channels=40, mid_channels=240, out_channels=40, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
SEInvertedBottleneck(in_channels=40, mid_channels=120, out_channels=48, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
SEInvertedBottleneck(in_channels=48, mid_channels=144, out_channels=48, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
SEInvertedBottleneck(in_channels=48, mid_channels=288, out_channels=96, kernel_size=5, stride=2,activate='hswish', use_se=True, se_kernel_size=7),
SEInvertedBottleneck(in_channels=96, mid_channels=576, out_channels=96, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=7),
SEInvertedBottleneck(in_channels=96, mid_channels=576, out_channels=96, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=7),
)
self.small_last_stage = nn.Sequential(
nn.Conv2d(in_channels=96, out_channels=576, kernel_size=1, stride=1),
nn.BatchNorm2d(576),
HardSwish(inplace=True),
nn.AvgPool2d(kernel_size=7, stride=1),
nn.Conv2d(in_channels=576, out_channels=1280, kernel_size=1, stride=1),
HardSwish(inplace=True),
)
self.classifier = nn.Conv2d(in_channels=1280, out_channels=num_classes, kernel_size=1, stride=1)
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.Linear):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.first_conv(x)
if self.type == 'large':
x = self.large_bottleneck(x)
x = self.large_last_stage(x)
else:
x = self.small_bottleneck(x)
x = self.small_last_stage(x)
out = self.classifier(x)
out = out.view(out.size(0), -1)
return out
if __name__ == '__main__':
model = MobileNetV3(type='small')
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)














 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









