






本文介绍了 5 大常用机器学习模型类型:集合学习算法,解释型算法,聚类算法,降维算法
,相似性算法,并简要介绍了每种类型中最广泛使用的算法模型。我们希望本文可以做到以下三点:
1、应用性。 涉及到应用问题时,知识的普适性显然非常重要。所以我们希望通过给出模型的一般类别,让你更好地了解这些模型应当如何应用。
2、相关性。 本文并不包括所有的机器学习模型,比如Naïve Bayes(朴素贝叶斯)和SVM这种传统算法,在本文中将会被更好的算法所取代。
3、可消化性
。对于数学基础较薄弱的读者而言,过多地解释算法会让这篇文章的可读性变差,更何况,你可以在网上找到无数教我们实现这些模型的资源。因此,为了避免本文变得无聊,我们将会把目光放在不同类型的模型的应用上。
01 集成学习算法
(随机森林XGBoost, LightGBM, CatBoost)
什么是集成学习算法?
为了理解什么是集成学习算法,首先,你需要知道什么是集成学习。集成学习是一种同时使用多个模型,以达到比使用单一模型更好的性能的方法。
从概念上讲,可以参考下面这个比喻:
我们向一个班里的学生提出一个数学问题。他们有两种解答方式:合作解答和单人解答。生活经验告诉我们,如果全班同学一起合作,那么学生之间可以互相检查,协作解决问题,并最终给出一个唯一的答案。然而单人作答就没有这种检查的福利了——即使他/她的答案错了,也没有人能帮他/她检验。
这里的全班协作就类似于一个集成学习算法,即由几个较小的算法同时工作,并形成最终的答案。
应用
集成学习算法主要应用于回归和分类问题或监督学习问题。由于其固有的性质,集成学习算法优于所有传统的机器学习算法,包括Naïve Bayes、SVM和决策树。
机器学习 | Sklearn中的朴素贝叶斯全解
机器学习|支持向量机1–线性SVM用于分类原理
机器学习|支持向量机2–非线性SVM与核函数
机器学习 | 决策树模型(一)理论
机器学习 | 决策树模型(二)实例
算法
随机森林: 随机森林由许多相互独立的决策树构成。
集成算法 | 随机森林分类模型
集成算法 | 随机森林回归模型
XGBoost: 类似于梯度提升(GradientBoost)算法,但添加了剪枝,Newton
Boosting,随机化参数等功能,因而比梯度提升更强大。
XGBoost 与 LightGBM 哪个更胜一筹
信用卡欺诈检测|用启发式搜索优化XGBoost超参数
LightGBM: 利用基于梯度的单边采样(GOSS)技术过滤数据的一种提升算法,目前实验已经证实比XGBoost更快,且有时更准确。
机器学习|LightGBM原理及代码
CatBoost: 一种基于梯度下降的算法。
02 解释型算法
(线性回归、逻辑回归、SHAP、LIME)
什么是解释型算法?
解释型算法使我们能够识别和理解结果有统计学意义的变量。因此,与其创建模型来预测响应变量的值,不如创建解释性模型来帮助我们理解模型中变量之间的关系。
而从回归的角度来看,人们往往强调统计学上显著的变量,这是因为对于从一个整体中提取出的样本数据,如果想对样本做出结论,首先必须确保变量拥有足够的显著性,并由此做出有把握的假设。
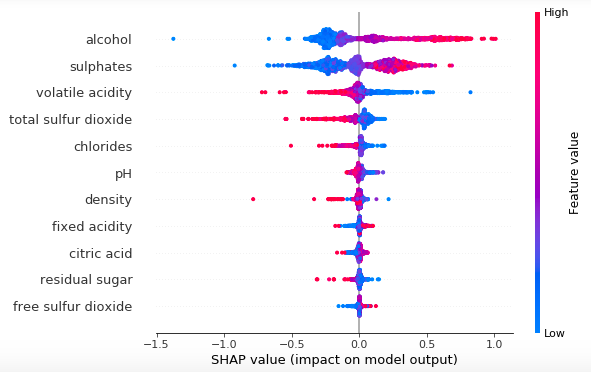
应用
解释性模型通常用于需要作出解释的场景。比如展示 「为什么 」做出某个决定,或者解释两个或多个变量之间「如何」相互关联。
在实践中,你的机器学习模型的可解释性与机器学习模型本身的性能一样重要。如果你不能解释一个模型是如何工作的,那么这个模型就很难取信于人,自然也就不会被人们应用。
算法
基于假设检验的传统解释模型:
线性回归: 如果 2 个或者多个变量之间存在“线性关系”,就可以通过历史数据,建立变量之间的有效“模型”,来预测未来的变量结果。例如,y = B0
Logistic回归: 逻辑回归主要解决二分类问题,用来表示某件事情发生的可能性。
机器学习 | 逻辑回归算法(一)理论
解释机器学习模型的算法:
SHAP: 即来自博弈论的沙普利加和解释,实际是将输出值归因到每一个特征的shapely值上,依此来衡量特征对最终输出值的影响。
用 SHAP 可视化解释机器学习模型实用指南(上)
用 SHAP 可视化解释机器学习模型实用指南(下)
LIME: LIME算法是Marco Tulio Ribeiro2016年发表的论文《“Why Should I Trust You?”
Explaining the Predictions of Any Classifier》中介绍的局部可解释性模型算法。该算法主要用于文本类与图像类的模型中。
03 聚类算法
(k-Means,分层聚类法)
什么是聚类算法?
聚类算法是用来进行聚类分析的一项无监督学习任务,通常需要将数据分组到聚类中。与监督学习的已知目标变量不同,聚类分析中通常没有目标变量。
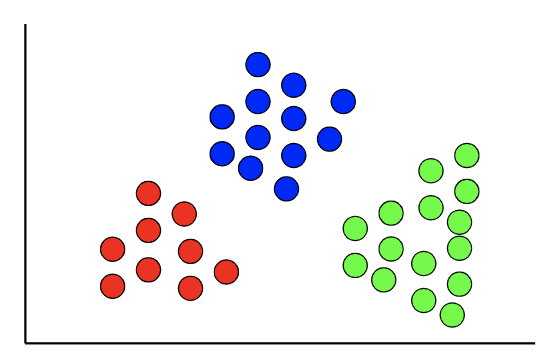
应用
聚类算法可以用于发现数据的自然模式和趋势。聚类分析在EDA阶段非常常见,因为可以得到更多的数据信息。
同样,聚类算法能帮你识别一组数据中的不同部分。一个常见的聚类细分是对用户/客户的细分。
算法
K-means聚类:
K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。
机器学习 | KMeans聚类分析详解
层次聚类: 通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。
04 降维算法
(PCA, LDA)
什么是降维算法?
降维算法是指减少数据集输入变量(或特征变量)数量的技术。本质上来说降维是用来解决“维度诅咒”的。(维度诅咒:随着维度(输入变量的数量)的增加,空间的体积呈指数级增长,最终导致数据稀疏。)
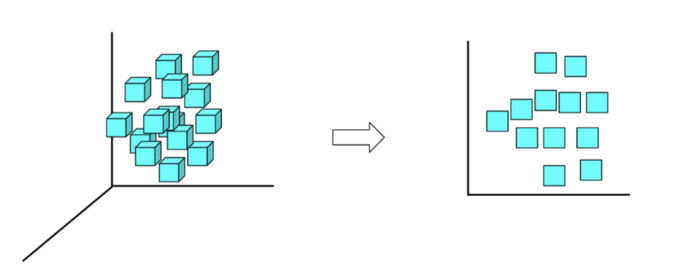
应用
降维技术适用于很多情况,比如:当数据集中的特征很多而实际需要的输入变量很少时,或者当ML模型过度拟合数据时,都可以使用降维技术。
算法
主成分分析(PCA)
:一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是在原有n维特征的基础上重新构造出来的,全新的正交特征。
机器学习|这次终于彻底理解了PCA主成分分析
线性判别分析(LDA): 用于在有两个以上的类时进行线性分类。
05 相似性算法
(KNN、欧几里得距离、余弦、列文斯坦、Jaro-Winkler、SVD…)
数据科学中 17 种相似性和相异性度量(上)
数据科学中 17 种相似性和相异性度量(下)
什么是相似性算法?
相似性算法是指那些计算记录/节点/数据点/文本对的相似性的算法。所以相似性算法包含许多种类,例如有比较两个数据点之间距离的相似性算法,如欧氏距离;也有计算文本相似性的相似性算法,如列文斯坦算法。
应用
相似性算法也可以用于各种场景,但在与“推荐”相关的应用上表现尤为出彩,比如用来决定:
-
根据你之前的阅读情况,Medium应该向你推荐哪些文章?
-
你可以用什么原料来替代蓝莓?
-
网易云应该根据你已经喜欢过的歌曲来推荐什么歌曲?
-
亚马逊应该根据你的订单历史推荐什么产品?
-
……
算法
K邻近: 通过在整个训练集上搜索与该数据点最相似的 K 个实例(近邻)并且总结这 K 个实例的输出变量,从而得出预测结果。
欧几里德距离: 一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。
余弦相似度:
利用向量空间中两个向量夹角间的余弦值衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
列文施泰因算法: 指两个字串之间,由一个转成另一个所需的最少编辑操作次数。
Jaro-Winkler算法: Jaro–Winkler distance
适合于较短的字符之间计算相似度。0分表示没有任何相似度,1分则代表完全匹配。
奇异值分解(SVD)(不完全属于相似性算法,但与相似性有间接关系): 定义一个m×n的矩阵A的SVD为:A=UΣVT
,其中U是一个m×m的矩阵,Σ是一个m×n的矩阵,除了主对角线上的元素以外全为0,主对角线上的每个元素都称为奇异值,V是一个n×n的矩阵。U和V都是酉矩阵,即满足UTU=I,VTV=I。这次终于彻底理解了SVD奇异值分解
以上就是对当前主流的机器学习算法的总结,希望本文能帮助你更好地了解各种ML模型以及它们的应用场景。当然,纸上得来终觉浅,如果本文使你有所收获,那就请开始你的应用之路吧,看看你能用ML解决什么问题!
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 3201
3201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









