







最近在学Spark的GraphX,希望通过博客或者总结的方式对学过的东西有所积累,同时也希望能有读者可以提出建议和意见。
关于GraphX
对于GraphX来说,大致的可以分为两部分:
第一部分是图的存储
第二部分是图的计算模型
在开始的时候,先来熟悉一下图的基本属性:
我们都知道,图是由顶点和边组成,在Spark中,数据都存储在RDD里面,GraphX也不例外,在图的基本操作当中,有几个常用的RDD,他们三个分别为VertexRDD、EdgeRDD、和?,嗯,那个问号不是乱码?至于为什么,接下来你们将会看到。
通过官网的图片我们先简单直观的看它们的结构:

图片有颜色的柱状结构就是它们的属性,对于顶点来说VertexRDD继承了RDD[(VertexId,VD)],而VertexId也就是Scala里面的Long类型,VD理应的就是顶点属性的类型了,EdgeRDD继承了RDD[Edge[ED]],而Edge是由srcId、dstId和Attr组成的类,同理的ED也就是边属性的类型。
通过图片可以看到,Triplets是由顶点、顶点属性、边属性构成。我们可与通过这三种基本结构对图进行求入度、子图等图的基本操作。
了解了图的基本信息之后,接下来要讲的是GraphX基本结构:
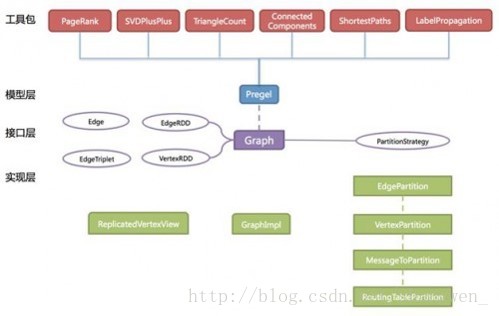
图片是来源于网上的文章,GraphX采用了Pregel的编程模型,即像PageRank、ShortestPaths等算法在GraphX中也是基于Pregel来实现,他们自定义了sendMessage函数,vertexProgram函数,和mergeMessage函数,然后交给Pregel去运行,而在Pregel中,他的核心函数是图的mapReduceTriplets,他通过一定的规则不断迭代,直到产生的activeMessage为0或者满足传入的迭代次数。最后计算得到相应的结果。
既然讲图的存储,先来一张粗略的函数调用图:
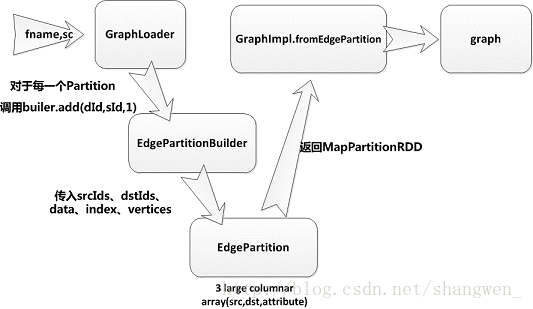
首先我们得加载数据。
我们可以通过GraphLoader加载文本文件,也可以通过图自己的构造器加载RDD,类似于下面两种方式:
加载文件:
graph = GraphLoader.edgeFile(sc,fname)
当然,也可以从RDD开始:
Graph = Graph(verticesRDD,edgesRDD,defaultVertexAttr)
对于加载文本文件来说,加载数据之后,需要对数据进行相应的格式化操作,就类似于下图:

对于每一行数据(忽略#开始的行)先转化为相应的顶点类型,通过上图可以看出,vertexId只能是数值类型,并且在初始化的时候,无法直接初始化边的属性,并且默认为1。
对于每个分区来说,产生的数据都会通过EdgePartitionBuilder的add函数把数据添加到其内部的一个edges的数组里面,之后通过toEdgePartition方法,将Edges的数据转化为源顶点的数组srcIds、目标顶点数组dstIds、和边的属性数组data、同时对srcIds进行建索引其数组为index,和由顶点(是所有顶点)进行Hash后和一个空的属性数组映射的vertexPartition,最后返回EdgePartition.
以下是部分的代码:
val vidsIter = srcIds.iterator ++ dstIds.iterator
val vertexIds = new OpenHashSet[VertexId]
vidsIter.foreach(vid => vertexIds.add(vid))
val vertices = new VertexPartition(
vertexIds, new Array[VD](vertexIds.capacity), vertexIds.getBitSet)
new EdgePartition(srcIds, dstIds, data, index, vertices)同时可以看出,现在的顶点数组是没有值的。
通过图的GraphImpl.fromEdgePartition方法,传入刚构建好的EdgePartition,并将其转化为EdgeRDD,并且传入默认的顶点属性。
GraphImpl.fromEdgePartitions(edges, defaultVertexAttr = 1) /** Create a graph from EdgePartitions, setting referenced vertices to `defaultVertexAttr`. */
def fromEdgePartitions[VD: ClassTag, ED: ClassTag](
edgePartitions: RDD[(PartitionID, EdgePartition[ED, VD])],
defaultVertexAttr: VD): GraphImpl[VD, ED] = {
fromEdgeRDD(new EdgeRDD(edgePartitions), defaultVertexAttr)
}通过构建好的EdgeRDD,通过VertexRDD.fromEdges方法,将EdgeRDD转化为routingTables和相应的VertexRDD,即刚才上面所提到的Vertices,routingTables存放的是vid对pid的映射(具体怎么存储希望有兴趣的可以讨论),我们在进行triplets和mapReduceTriplets操作的时候,会使用到路由表的路由信息,原理如下图:
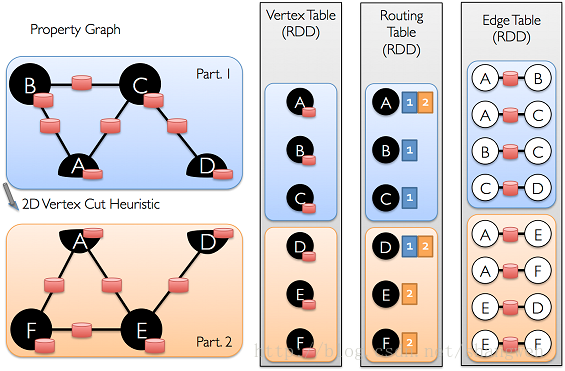
图存储的优化:
为了解决计算平衡的问题
PartitionStrategy类使用了四种分区策略:
图的计算模型
前面有提到,lib包里面的算法基本是实现了图的三个函数,然后传递给Pregel:
1、vertexProgram函数
2、sendMessage函数
3、messageCombiner函数
我们来简单看一下Pregel里面的apply函数参数:
graph:Graph[VD, ED]构造好的图
initialMsg: A 初始化信息
maxIterations: Int = Int.MaxValue 默认的最大迭代
activeDirection 设定边的活跃顶点的方向
vprog 顶点函数
sendMsg 发送函数
mergeMsg 合并函数
上一篇文章讲了pregel的基本运行方式,现在主要提一下activeDirection的作用
在pregel中,activeDirection 是默认以EdgeDirection.Either为默认选项的,原理请看下图(ShortestPaths例子):
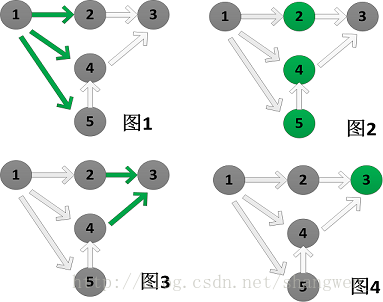
从之前的文章可以知道,只有接收到message的顶点才会在newVerts里面,当参数为Either时,即在Edges的集合当中,srcId或者dstId在newVert集合里面就可以发送消息 ,就像图2一样,绿色顶点为新的顶点集,所以message会被发送。顶点1->2 .... 顶点4->顶点3.
总结如下:
EdgeDirection.In:dstId在newVerts
EdgeDirection.Out:srcId在newVerts
EdgeDirection.Either:srcId或dstId在newVerts
EdgeDirection.Both:这个你懂得……
本文完....

















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









